Clear Sky Science · ru
От данных к открытиям: рост информационно-теоретических предсказательных моделей в разработке лекарств
Почему важно ускорить поиск лекарств
Многие серьёзные заболевания по-прежнему лишены эффективных терапий, и даже когда появляются перспективные препараты, путь от идеи до прилавка аптеки остаётся долгим и дорогим. В этой статье исследуется, как более умные компьютерные модели способны просеивать огромные массивы химических и биологических данных, чтобы быстрее и надёжнее выделять несколько перспективных кандидатов в лекарства. Заимствуя идеи из теории информации — математики того, сколько можно узнать из данных — авторы показывают способ сузить поиск новых лекарств и лучше понять, что делает молекулу вероятно эффективной в организме.
От проб и ошибок к дизайну, основанному на данных
Традиционный поиск лекарств опирался на комбинацию обоснованных предположений, скрининга в лаборатории и порой удачных случайностей, таких как открытие пенициллина. Сегодня исследователи могут проверять миллионы соединений в компьютере, не прикасаясь к пробирке. Инструменты виртуального скрининга классифицируют молекулы по предсказанному биологическому поведению, помогая учёным сосредоточиться на наиболее перспективных. Однако многие существующие инструменты либо рассматривают каждую молекулу изолированно, либо дают лишь приблизительные оценки вероятности, и им бывает сложно учесть, как реальные биологические контексты — например, перемещение препарата по организму — влияют на успех или неудачу.
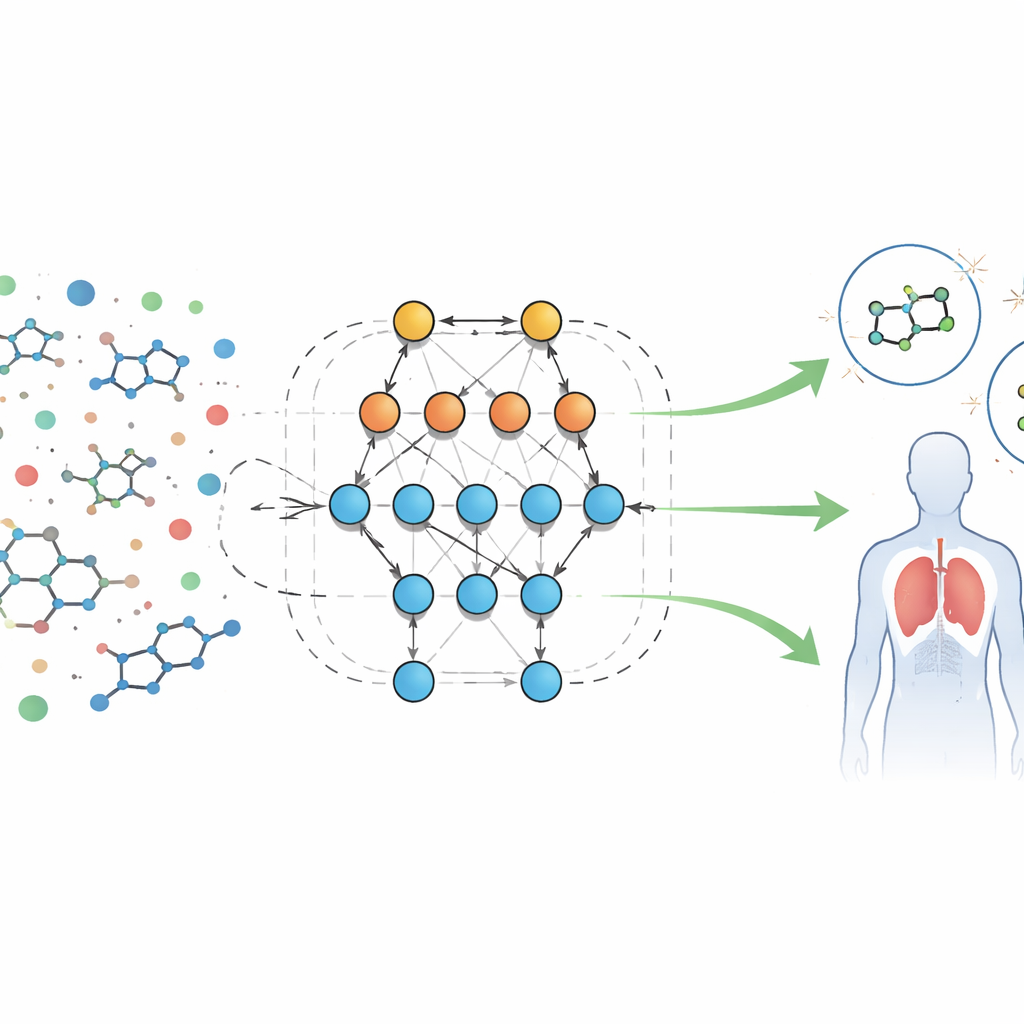
Новый способ читать биологические отпечатки
Авторы анализируют большую общедоступную базу данных результатов биологического скрининга для молекул, нацеленных на рецептор формилпептида — белок, участвующий в воспалении и иммунной защите. Каждая запись сопровождается десятками измеримых признаков, или «дескрипторов», таких как размер молекулы, растворимость в липидах или воде, способность проникать через гематоэнцефалический барьер и формировать водородные связи. Вместо того чтобы записывать фиксированные уравнения для поведения этих признаков, команда использует автоматизированную систему под названием Eidos, которая строит информационно-теоретические предсказательные модели непосредственно из данных. Эти модели, именуемые ASC (automated system-cognitive) анализом, обучаются тому, как сочетания признаков связаны с тем, проявляет ли образец активность (потенциально полезен) или неактивен в биологических тестах.
Очистка данных и выбор важного
Реальные данные скрининга шумны: измерения могут быть непоследовательными, а некоторые образцы — не вписываться в чёткие шаблоны. Система Eidos сначала фильтрует такие «артефакты», удаляя более тысячи спорных записей и оставляя чуть более двух тысяч надёжных образцов. Затем она рассматривает более 300 признаков, чтобы выяснить, какие из них действительно помогают отличать активные образцы от неактивных. Используя понятия теории информации, каждый признак оценивается по тому, насколько он снижает неопределённость в отношении исхода. Анализ показывает, что лишь меньшинство признаков несёт основную полезную информацию, что означает: исследователи могут безопасно игнорировать многие измерения и при этом сохранить почти всю предсказательную мощность. Такая «обрезка» делает модели проще, понятнее и быстрее в работе.
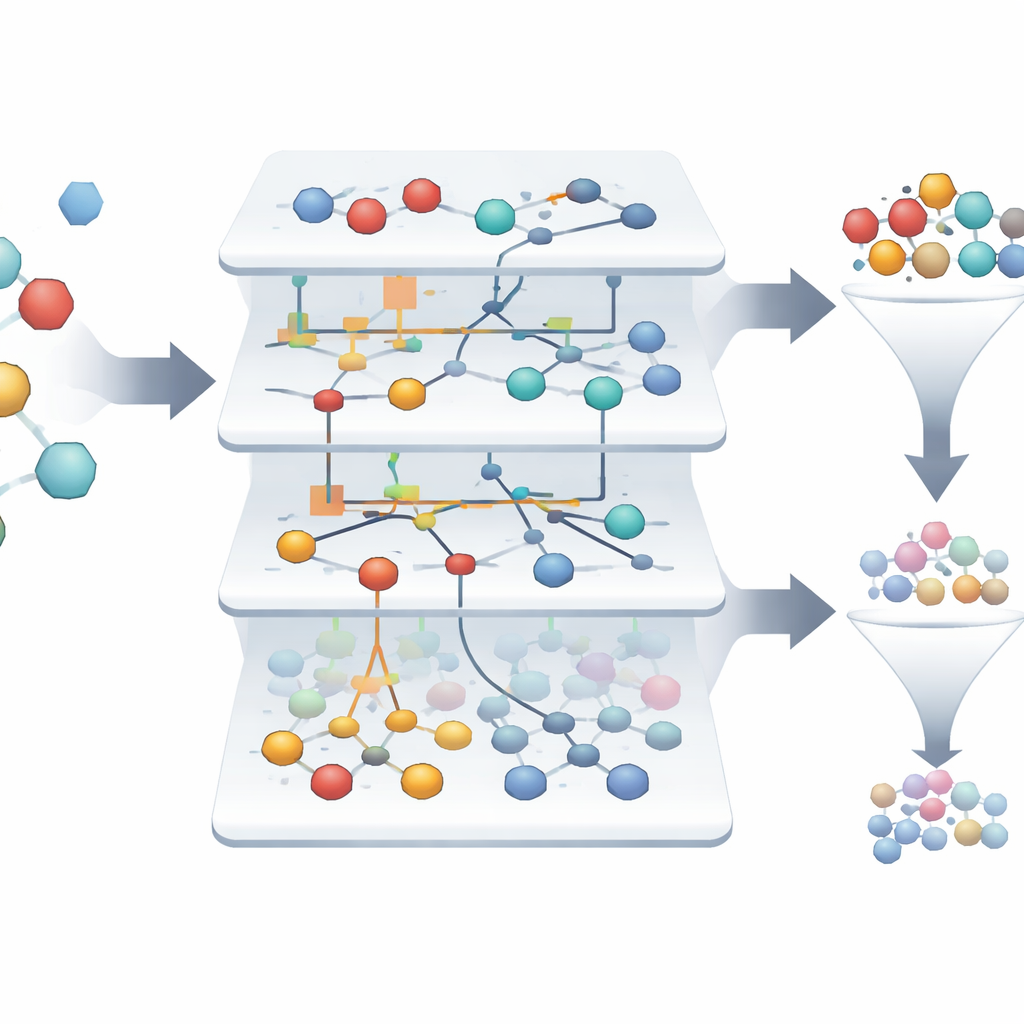
Поиск редких победителей в море неудач
В изученной выборке лишь около 1,4% молекул действительно активны, что затрудняет обнаружение нескольких победителей среди тысяч поражений. Модели на базе ASC автоматически строят «информационные портреты», показывающие, насколько сильно каждый признак и их комбинации сдвигают образец в сторону активности или неактивности. Из более чем трёх тысяч исходных образцов система выделяет всего двоих, которые проявляют себя как высоконадежные кандидаты на препараты, нацеленные на рецептор формилпептида, с надёжностью модели, приближающейся к 99,9% при ретроспективных тестах. Визуальные сетевые диаграммы показывают, какие молекулярные характеристики наиболее сильно поддерживают активное состояние, давая учёным интерпретируемую карту факторов, приводящих к многообещающему поведению.
Как этот подход выглядит на фоне других и что дальше
Авторы сравнивают свой метод с популярными инструментами раннего прогнозирования, такими как pkCSM, SwissADME и ADMETlab, которые оценивают, как препарат всасывается, распределяется, метаболизируется и выводится. В то время как эти системы в основном опираются на заранее заданные правила или универсальные методы машинного обучения, рамочная модель ASC явно измеряет вклад каждого признака в прирост знаний о поведении, похожем на лекарственное, и может моделировать изменения биологического контекста. Вместе с тем исследование отмечает ограничения: набор данных относительно небольшой и сильно несбалансирован, а метод применён пока только к одному рецептору. Авторы предполагают, что будущие версии могли бы сочетать модели ASC с глубоким обучением и расширять применение на несколько мишеней.
Что это значит для будущих лекарств
С практической точки зрения эта работа демонстрирует, что информационно насыщенные модели способны превращать неаккуратные данные скрининга в ясные, проверяемые предсказания о том, какие молекулы заслуживают дальнейшего внимания. Автоматически очищая данные, ранжируя важность признаков и выделяя редкие, но перспективные соединения, подход может сократить время и затраты, необходимые для перехода к лабораторным исследованиям и, в конечном счёте, к клинике. Хотя он не заменяет эксперименты на животных или клинические испытания, он выступает мощным фильтром и ориентиром, помогая учёным более эффективно и с большей уверенностью двигаться от сырых данных к потенциальным терапии.
Цитирование: Saied, H., Alfahad, O., Aljaffer, A.A. et al. From data to discovery: The rise of information-theoretic predictive models in drug development. Sci Rep 16, 12857 (2026). https://doi.org/10.1038/s41598-026-45644-5
Ключевые слова: поиск лекарств, виртуальный скрининг, предиктивное моделирование, данные биотестов, рецептор формилпептида