Clear Sky Science · tr
Veriden keşfe: İlaç geliştirmede bilgi teorik öngörücü modellerin yükselişi
Neden daha hızlı ilaç keşfi önemli?
Birçok ciddi hastalığın hâlâ etkili tedavileri yok ve umut verici ilaçlar bulunsa bile fikirden eczane rafına ulaşmak uzun ve maliyetli bir süreç. Bu makale, daha akıllı bilgisayar modellerinin kimyasal ve biyolojik verilerin büyük koleksiyonlarını nasıl tarayıp birkaç umut verici ilaç adayını daha hızlı ve güvenilir şekilde tespit edebileceğini inceliyor. Bilgi teorisinden — veriden ne kadar şey öğrenebileceğimizin matematiğinden — ödünç alınan fikirlerle yazarlar, yeni ilaç arayışını daraltmanın ve bir molekülün vücutta işe yaramasına neyin etki ettiğini daha iyi anlamanın bir yolunu gösteriyorlar.
Deneme-yanılmadan veri odaklı tasarıma
Geleneksel ilaç keşfi eğitimli varsayımlar, laboratuvar taramaları ve bazen penisilin gibi şans eseri buluşların bir karışımına dayanıyordu. Bugün araştırmacılar test tüpüne dokunmadan önce bilgisayarlarda milyonlarca bileşiği deneyebilirler. Sanal tarama araçları molekülleri tahmini biyolojik davranışlarına göre sınıflandırarak bilim insanlarının en umutlu olanlara odaklanmasına yardımcı olur. Ancak mevcut araçların birçoğu ya her molekülü izole olarak ele alır ya da yalnızca kabaca olasılık tahminleri verir ve sıklıkla bir ilacın vücutta nasıl hareket ettiği gibi gerçek dünya biyolojik bağlamın başarıyı veya başarısızlığı nasıl şekillendirdiğini yakalamakta zorlanır.
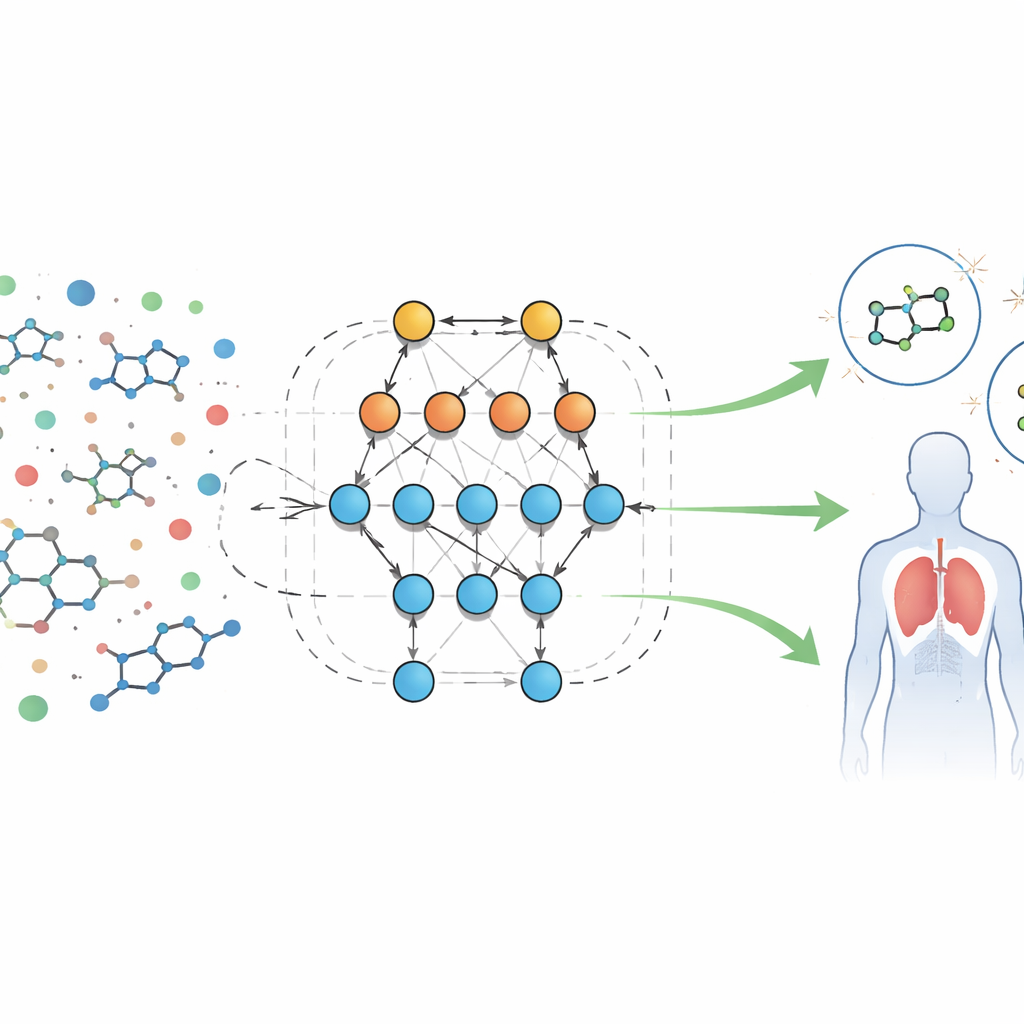
Biyolojik parmak izlerini okumaya yeni bir yaklaşım
Yazarlar, inflamasyon ve bağışıklık savunmasında rol oynayan bir protein olan formil peptit reseptörünü hedefleyen moleküller için geniş bir açık biyo-tarama veri setini analiz ediyorlar. Her örnek, moleküler boyut, yağda veya suda çözünme eğilimi, kan-beyin bariyerini geçebilme ve hidrojen bağları kurma kapasitesi gibi onlarca ölçülebilir özellikle — “tanımlayıcılarla” birlikte gelir. Bu özelliklerin nasıl davranması gerektiğine dair sabit denklemler yazmak yerine ekip, verilerden doğrudan bilgi teorik öngörücü modeller kuran Eidos adlı otomatik bir sistemi kullanıyor. ASC (otomatik sistem-bilişsel) analizi olarak anılan bu modeller, özellik kombinasyonlarının bir örneğin biyolojik testlerde aktif (potansiyel olarak faydalı) veya inaktif olarak davranmasıyla nasıl bağlantılı olduğunu öğreniyor.
Veriyi temizlemek ve önemli olanı seçmek
Gerçek dünya tarama verileri gürültülüdür: ölçümler tutarsız olabilir ve bazı örnekler belirgin herhangi bir desene uymayabilir. Eidos sistemi önce bu “artefaktları” filtreleyerek binin üzerinde şüpheli kaydı çıkarır ve yaklaşık iki bin güvenilir örneği elde eder. Ardından hangi özelliklerin gerçekten aktif ile inaktif örnekleri ayırt etmeye yardımcı olduğunu görmek için 300’den fazla özelliği inceler. Bilgi teorisinden kavramlar kullanılarak her özellik, sonucu hakkındaki belirsizliği ne kadar azalttığına göre puanlanır. Analiz, faydalı bilginin büyük kısmını yalnızca azınlık özelliklerin taşıdığını ortaya koyuyor; bu da araştırmacıların birçok ölçümü güvenle görmezden gelebileceği ve neredeyse tüm öngörü gücünü koruyabileceği anlamına geliyor. Bu kırpma modelleri daha basit, daha yorumlanabilir ve çalıştırması daha hızlı hale getiriyor.
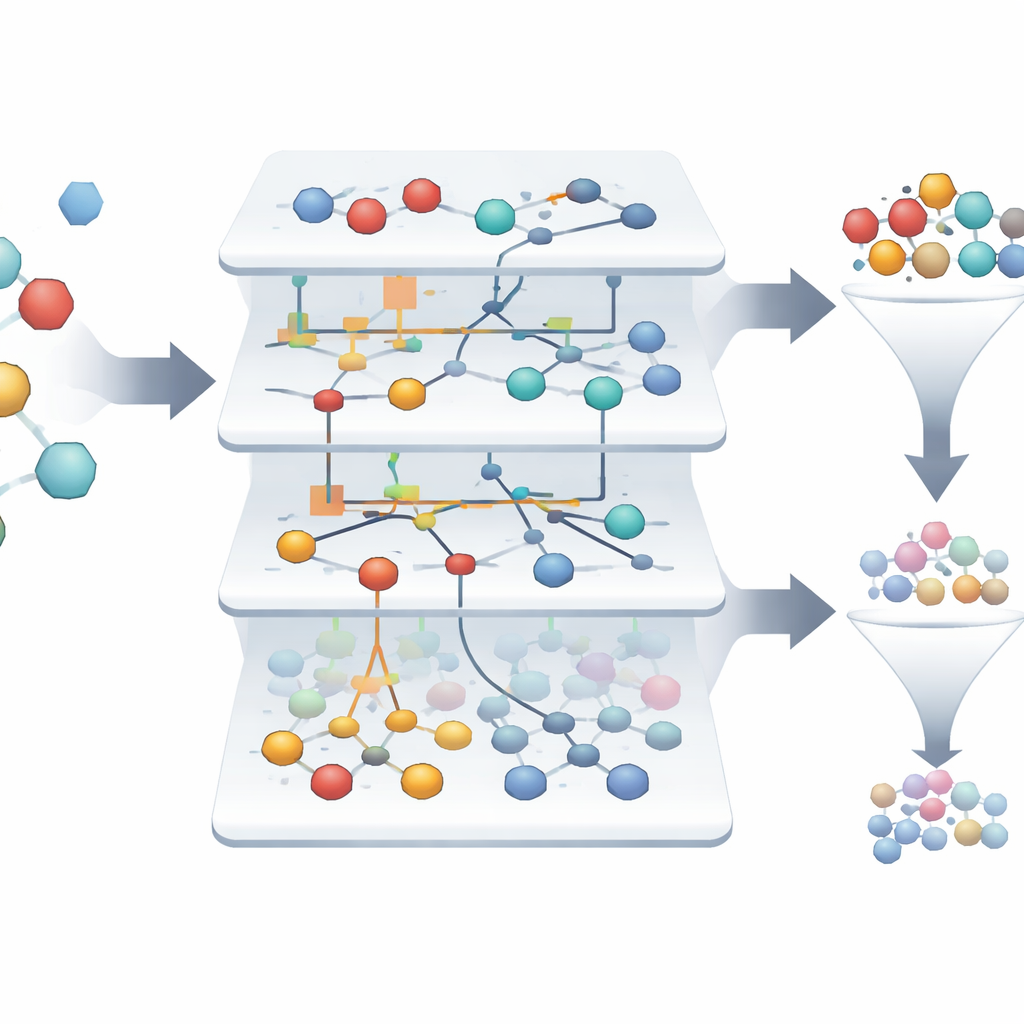
Başarısızlık denizinde nadir kazananları bulmak
İncelenen veri setinde moleküllerin yalnızca yaklaşık %1,4’ü gerçekten aktiftir; bu da binlerce başarısızlık arasından birkaç kazananı tespit etmeyi zorlaştırır. ASC tabanlı modeller her bir özellik ve özellik kombinasyonunun bir örneği aktif veya inaktif yönde ne kadar ittiğini gösteren “bilgi portreleri” otomatik olarak oluşturur. Üç binden fazla orijinal örnek arasından sistem, formil peptit reseptörünü hedefleyen ilaç adayları olarak öne çıkan sadece iki örneği vurgular; geriye dönük testlerde model güvenilirliği yaklaşık %99,9’a yaklaşmıştır. Görsel ağ diyagramları, hangi moleküler özelliklerin aktif durumu en güçlü şekilde desteklediğini göstererek bilim insanlarına umut vaadeden davranışı yönlendirenlerin yorumlanabilir bir haritasını sunar.
Bu yaklaşımın karşılaştırması ve sonrası
Yazarlar yöntemlerini, bir ilacın nasıl emildiği, dağıldığı, parçalandığı ve atıldığına dair tahminler yapan pkCSM, SwissADME ve ADMETlab gibi popüler erken aşama tahmin araçlarıyla karşılaştırıyorlar. Bu sistemler esasen önceden tanımlanmış kurallara veya genel amaçlı makine öğrenimine dayanırken, ASC çerçevesi her bir özelliğin ilaç-benzeri davranış hakkında kazanılan bilgiye ne kadar katkıda bulunduğunu açıkça ölçer ve biyolojik bağlamdaki değişiklikleri simüle edebilir. Bununla birlikte çalışma sınırlardan da söz ediyor: veri seti nispeten küçük ve ağır bir şekilde dengesiz, ve yöntem şu ana dek yalnızca tek bir reseptöre uygulanmış. Yazarlar, gelecekteki sürümlerin ASC modellerini derin öğrenmeyle birleştirebileceğini ve birden fazla hedefe genişletilebileceğini öne sürüyorlar.
Geleceğin ilaçları için ne anlama geliyor?
Pratik açıdan bakıldığında bu çalışma, bilgi açısından zengin modellerin dağınık tarama verilerini hangi moleküllerin daha fazla dikkat gerektirdiğine dair net, test edilebilir öngörülere dönüştürebileceğini gösteriyor. Veriyi otomatik temizleyip özelliklerin önemini sıralayarak ve nadir ama umut verici bileşikleri ön plana çıkararak bu yaklaşım laboratuvara ve nihayetinde kliniğe ulaşmak için gereken zaman ve maliyeti azaltabilir. Hayvan çalışmaları veya insan denemelerinin yerini almasa da güçlü bir filtre ve rehber görevi görerek bilim insanlarının ham veriden potansiyel tedavilere daha verimli ve daha yüksek güvenle geçmesine yardımcı olur.
Atıf: Saied, H., Alfahad, O., Aljaffer, A.A. et al. From data to discovery: The rise of information-theoretic predictive models in drug development. Sci Rep 16, 12857 (2026). https://doi.org/10.1038/s41598-026-45644-5
Anahtar kelimeler: ilaç keşfi, sanal tarama, öngörücü modelleme, biyoassay verisi, formil peptit reseptörü