Clear Sky Science · ja
データから発見へ:創薬における情報理論的予測モデルの台頭
なぜ創薬の高速化が重要か
多くの深刻な病気には依然として有効な治療法がなく、有望な薬が見つかっても、概念から薬局の棚に並ぶまでの道のりは長く費用がかかります。本稿は、コンピュータモデルを賢く使うことで、膨大な化学・生物学データの中から有望な候補をより速く、より確実に絞り込める方法を探ります。情報理論──データからどれだけ学べるかを扱う数学──の発想を取り入れることで、薬探しの範囲を狭め、分子が体内で有効に働く可能性を左右する要因をよりよく理解する道筋を示します。
試行錯誤からデータ駆動設計へ
従来の創薬は、経験に基づく推測、実験室でのスクリーニング、時にはペニシリンの発見のような偶然の産物に頼ってきました。現在では、研究者は試験管に触れる前にコンピュータ上で何百万もの化合物を評価できます。バーチャルスクリーニングツールは、分子を予測される生物学的振る舞いに基づいて分類し、研究者が最も有望な候補に集中できるよう支援します。しかし、多くの既存ツールは各分子を孤立して扱うか、粗い確率推定しか出さず、薬物が体内でどう動くかといった実際の生物学的文脈が成功や失敗に与える影響を十分に捉え切れていないことが多いのです。
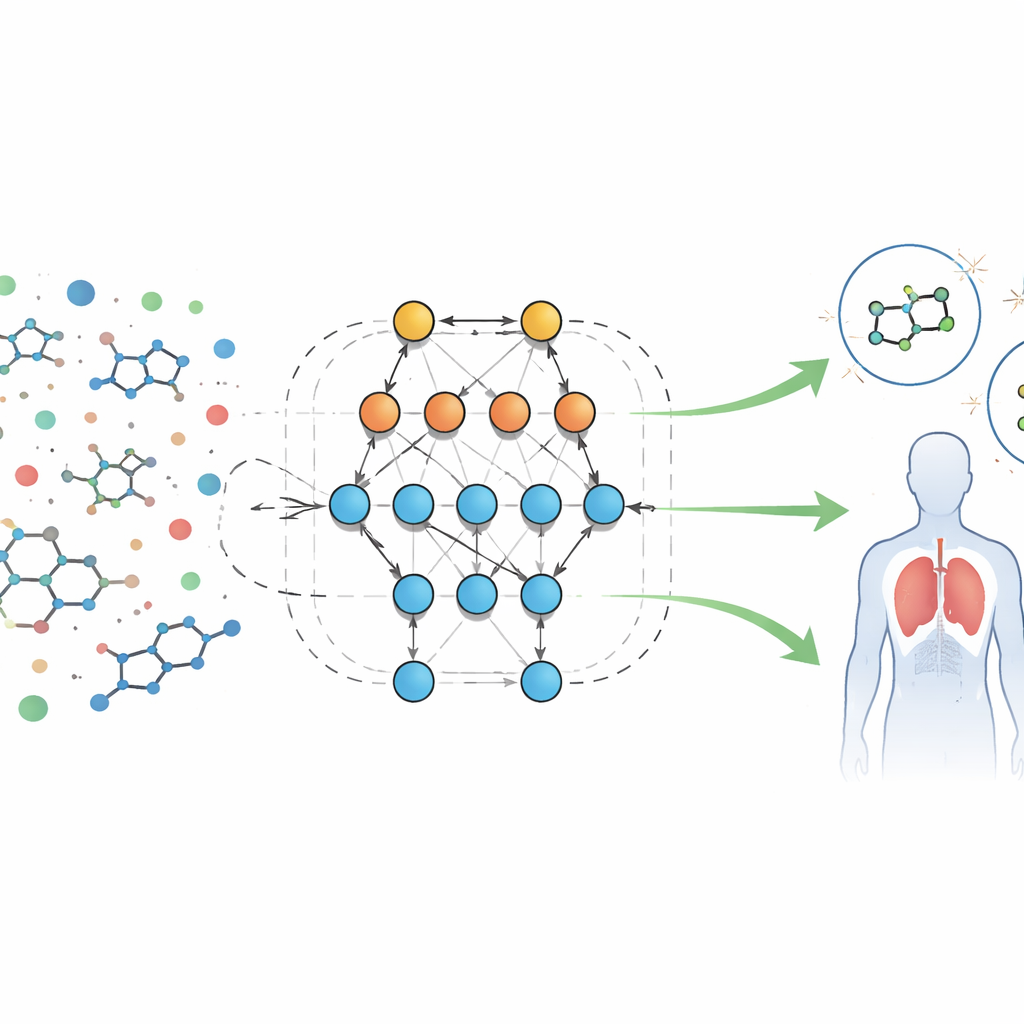
生物学的「指紋」の新しい読み方
著者らは、炎症や免疫防御に関与するタンパク質であるホルミルペプチド受容体を標的とした化合物に関する大規模な公開バイオスクリーニングデータを解析します。各サンプルには分子サイズ、脂溶性・水溶性の溶解性、血液脳関門通過能、求電子対形成能など数十の測定可能な特徴(「記述子」)が付随します。これらの特徴に対して固定的な方程式を当てはめる代わりに、研究チームはEidosと呼ばれる自動化システムを用い、データから直接情報理論に基づく予測モデルを構築します。ASC(automated system-cognitive)解析と呼ばれるこれらのモデルは、特徴の組み合わせが生物学的試験でサンプルが活性(有用である可能性)か非活性かにどう結び付くかを学習します。
データの浄化と重要項目の選別
現実のスクリーニングデータはノイズを含みます:測定が一貫しなかったり、いくつかのサンプルが明瞭なパターンに当てはまらないことがあります。Eidosはまずそうした「アーティファクト」を除外し、千件以上の疑わしいエントリを削り、信頼できる二千件強のサンプルを残します。次に300以上の特徴を検討して、どれが実際に活性と非活性を区別するのに役立つかを評価します。情報理論の概念を用い、各特徴は結果に関する不確実性をどれだけ減らすかでスコア付けされます。解析の結果、有用な情報の大半を担うのはごく一部の特徴に過ぎないことが判明し、多くの測定を無視してもほとんど予測力を失わないことが示されます。この剪定によりモデルは簡潔になり、解釈しやすく、実行も高速になります。
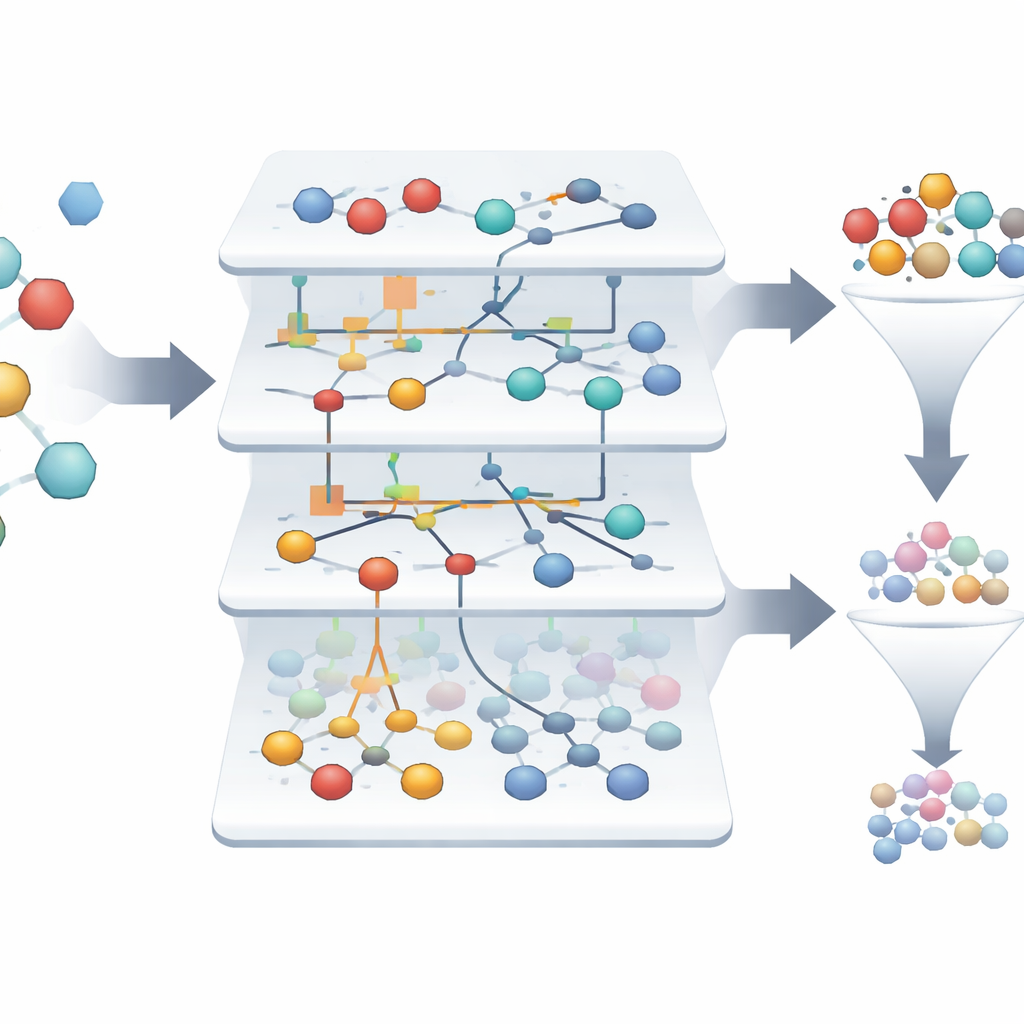
失敗の海から稀な勝者を見つける
解析対象のデータセットでは、真に活性な分子は約1.4%しかなく、何千もの失敗の中から数少ない有望株を見つけるのは難しい状況です。ASCベースのモデルは各特徴や特徴の組合せがサンプルを活性寄りあるいは非活性寄りにどれほど押しやるかを示す「情報ポートレート」を自動的に作成します。三千件超の元のサンプルの中から、同システムはホルミルペプチド受容体を標的とする薬剤候補として際立って信頼できる2件のみをハイライトし、遡及的テストではモデルの信頼度が約99.9%に達しました。視覚的なネットワーク図は、活性状態を最も強く支持する分子特性を示し、研究者に有望な挙動を駆動する因子の解釈しやすいマップを提供します。
他手法との比較と今後の展望
著者らは、自らの手法を、薬物の吸収・分布・代謝・排泄を推定するpkCSM、SwissADME、ADMETlabといった広く使われる初期予測ツールと比較します。これらのシステムは主に事前定義の規則や汎用の機械学習に頼るのに対し、ASCフレームワークは各特徴が薬様挙動について得られる知識にどれだけ寄与するかを明示的に測り、生物学的文脈の変化をシミュレートすることができます。一方で、研究には限界もあります:データセットは比較的小さく大きく不均衡であり、手法はこれまでに一つの受容体に対してのみ適用されています。著者らは将来的にASCモデルを深層学習と組み合わせ、複数のターゲットへ拡張する可能性を示唆しています。
将来の医薬品にとっての意義
実務的には、この研究は情報量の多いモデルが雑多なスクリーニングデータを、どの分子にさらに注目すべきかについての明確で検証可能な予測へと変え得ることを示しています。データの自動浄化、特徴の重要度ランキング、稀でありながら有望な化合物の可視化を通じて、このアプローチは実験室や最終的には臨床に到達するまでの時間とコストを減らせます。動物実験やヒト試験に取って代わるものではありませんが、強力なフィルターかつガイドとして働き、生データから潜在的治療法へとより効率的かつ確信をもって進む手助けをします。
引用: Saied, H., Alfahad, O., Aljaffer, A.A. et al. From data to discovery: The rise of information-theoretic predictive models in drug development. Sci Rep 16, 12857 (2026). https://doi.org/10.1038/s41598-026-45644-5
キーワード: 創薬, バーチャルスクリーニング, 予測モデリング, バイオアッセイデータ, ホルミルペプチド受容体