Clear Sky Science · sv
Från data till upptäckt: Informations-teoretiska prediktiva modeller i läkemedelsutveckling
Varför snabbare läkemedelsupptäckt spelar roll
Många allvarliga sjukdomar saknar fortfarande effektiva behandlingar, och även när lovande läkemedel upptäcks är vägen från idé till apotekslåda lång och kostsam. Denna artikel undersöker hur smartare datormodeller kan sålla i enorma samlingar av kemisk och biologisk information för att snabbare och mer tillförlitligt peka ut ett fåtal lovande läkemedelskandidater. Genom att låna idéer från informationsteori — matematiken kring hur mycket vi kan lära oss från data — visar författarna ett sätt att begränsa sökandet efter nya läkemedel och bättre förstå vad som gör en molekyl sannolik att fungera i kroppen.
Från trial-and-error till datadriven design
Traditionell läkemedelsupptäckt har förlitat sig på en blandning av välinformerade gissningar, laboratoriescreening och ibland lyckliga tillfälligheter som upptäckten av penicillin. Idag kan forskare testa miljontals föreningar i datorer innan de någonsin rör ett provrör. Verktyg för virtuell screening klassificerar molekyler efter deras förväntade biologiska beteende och hjälper forskare att fokusera på de mest lovande. Många befintliga verktyg behandlar dock varje molekyl isolerat eller ger endast grova sannolikhetsuppskattningar, och de har ofta svårt att fånga hur verklig biologisk kontext — som hur ett läkemedel rör sig i kroppen — formar framgång eller misslyckande.
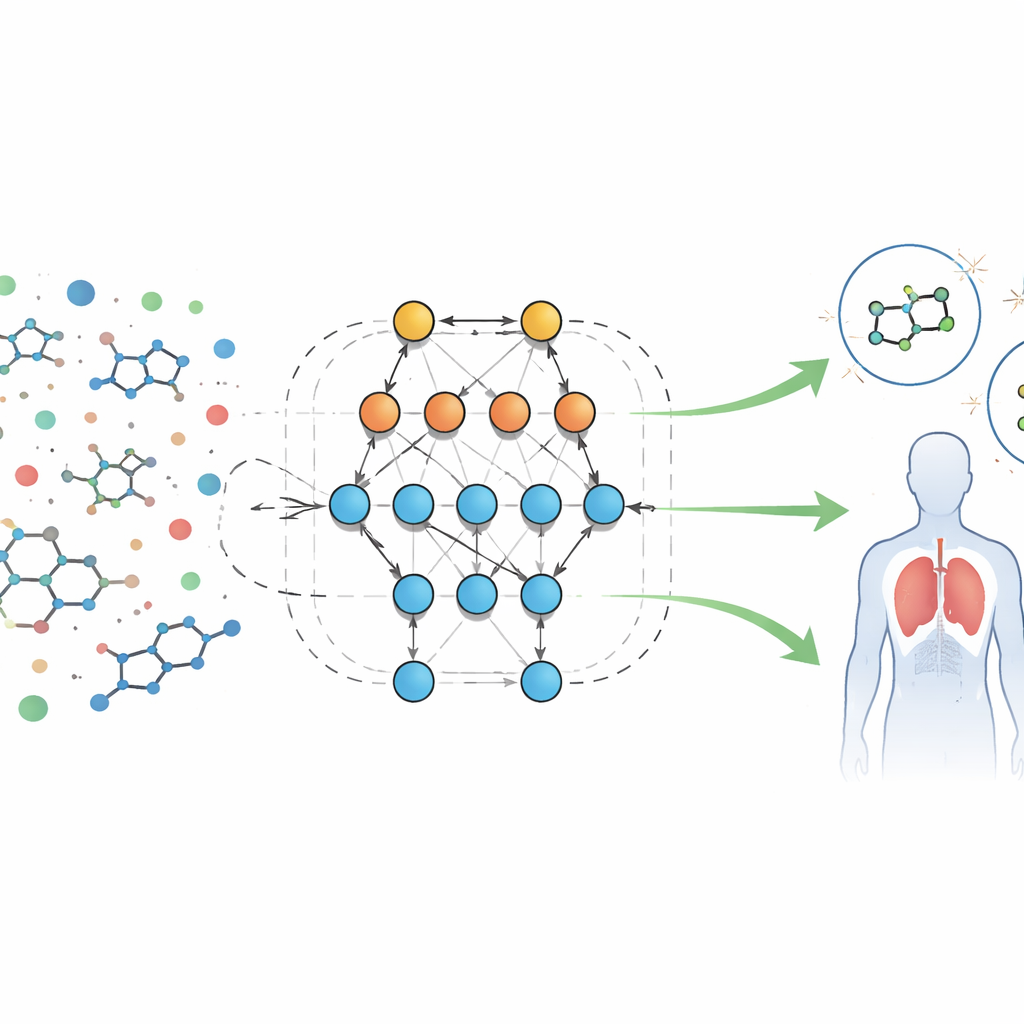
Ett nytt sätt att läsa biologiska fingeravtryck
Författarna analyserar en stor offentlig datamängd med resultat från biologiska screeningar av molekyler riktade mot en formylpeptidreceptor, ett protein involverat i inflammation och immunförsvar. Varje prov har dussintals mätbara egenskaper, eller ”deskriptorer”, såsom molekylstorlek, hur lätt den löser sig i fett eller vatten, förmåga att passera blod–hjärnbarriären samt kapacitet att bilda vätebindningar. Istället för att skriva fasta ekvationer för hur dessa egenskaper ska bete sig använder teamet ett automatiserat system kallat Eidos, som bygger informationsteoretiska prediktiva modeller direkt från data. Dessa modeller, benämnda ASC (automated system-cognitive) analys, lär sig hur kombinationer av egenskaper kopplas till om ett prov beter sig som aktivt (potentiellt användbart) eller inaktivt i biologiska tester.
Rensa data och välja vad som räknas
Verkliga screeningdata är brusiga: mätningar kan vara inkonsekventa och vissa prover passar inte in i något tydligt mönster. Eidos-systemet filtrerar först bort dessa ”artefakter”, tar bort över tusen tveksamma poster och behåller knappt över tvåtusen pålitliga prover. Därefter undersöks mer än 300 egenskaper för att se vilka som verkligen hjälper till att skilja aktiva från inaktiva prov. Med hjälp av begrepp från informationsteori poängsätts varje egenskap utifrån hur mycket den minskar osäkerheten om utgången. Analysen visar att endast en minoritet av egenskaperna bär den mesta användbara informationen, vilket innebär att forskare säkert kan ignorera många mätningar och ändå behålla nästan all prediktiv kraft. Denna trimning gör modellerna enklare, lättare att tolka och snabbare att köra.
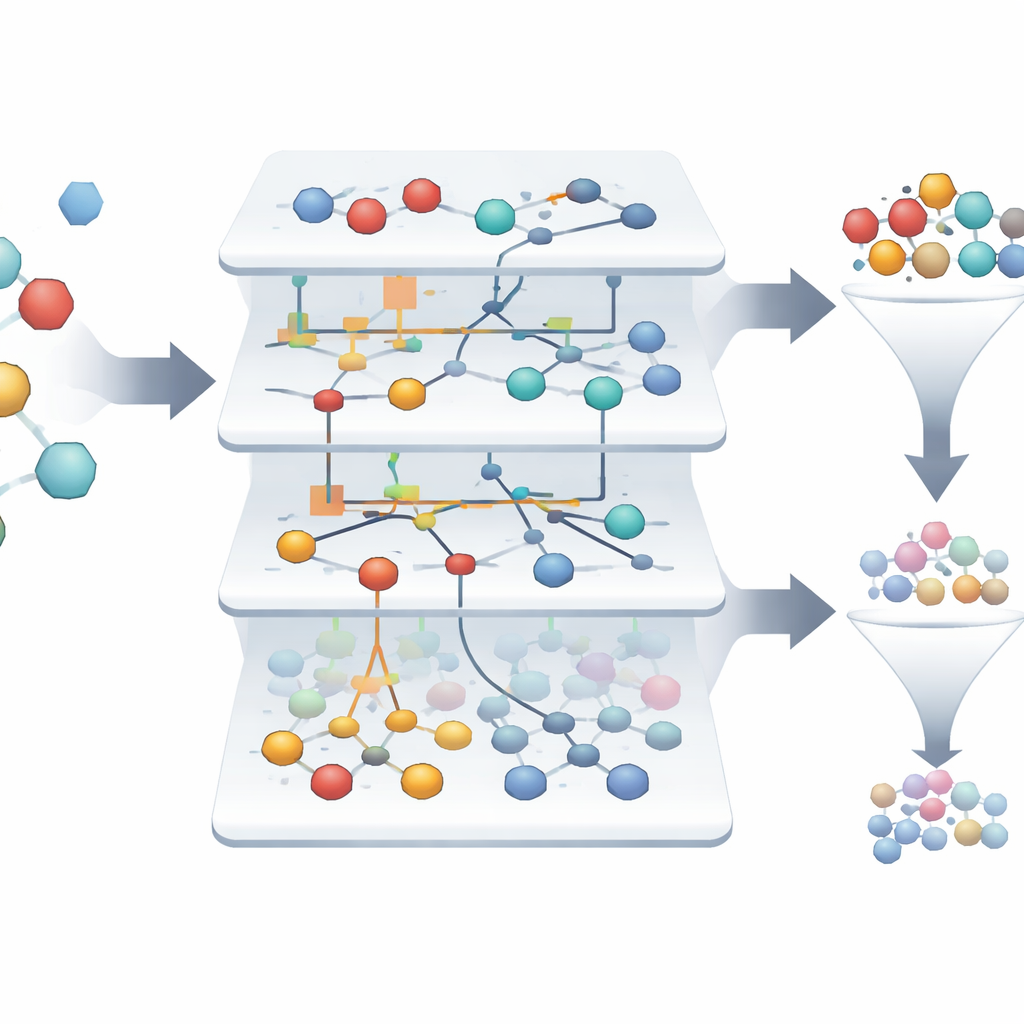
Hitta sällsynta vinnare i ett hav av misslyckanden
I den undersökta datamängden är endast omkring 1,4 % av molekylerna verkligt aktiva, vilket gör det svårt att hitta de få vinnarna bland tusentals misslyckanden. ASC-baserade modeller bygger automatiskt ”informationsporträtt” som visar hur starkt varje egenskap och kombination av egenskaper skjuter ett prov mot att vara aktivt eller inaktivt. Av mer än tretusen ursprungliga prover lyfter systemet fram endast två som sticker ut som mycket pålitliga kandidater för läkemedel som riktar sig mot formylpeptidreceptorn, med modellpålitlighet som närmar sig 99,9 % i retrospektiva tester. Visuella nätverksdiagram visar vilka molekylära egenskaper som starkast stödjer ett aktivt tillstånd och ger forskare en tolkbar karta över vad som driver ett lovande beteende.
Hur denna metod står sig och vad som kommer härnäst
Författarna jämför sin metod med populära tidiga prediktionsverktyg såsom pkCSM, SwissADME och ADMETlab, som uppskattar hur ett läkemedel tas upp, distribueras, bryts ner och utsöndras. Medan dessa system främst förlitar sig på fördefinierade regler eller allmänna maskininlärningsmetoder mäter ASC-ramverket uttryckligen hur mycket varje egenskap bidrar till den kunskap som vunnits om läkemedelslikt beteende och kan simulera förändringar i biologisk kontext. Samtidigt noterar studien begränsningar: datamängden är relativt liten och starkt obalanserad, och metoden har hittills endast tillämpats på en receptor. Författarna föreslår att framtida versioner kan kombinera ASC-modeller med djupinlärning och utvidgas till flera mål.
Vad det betyder för framtida läkemedel
I praktiska termer visar detta arbete att informationsrika modeller kan förvandla röriga screeningdata till tydliga, testbara förutsägelser om vilka molekyler som förtjänar fortsatt uppmärksamhet. Genom att automatiskt rensa data, rangordna egenskapernas betydelse och lyfta fram sällsynta men lovande föreningar kan tillvägagångssättet minska tiden och kostnaden som krävs för att nå laboratoriet och så småningom kliniken. Även om det inte ersätter djurstudier eller kliniska prövningar fungerar det som ett kraftfullt filter och vägvisare som hjälper forskare att röra sig från rådata till potentiella behandlingar effektivare och med större säkerhet.
Citering: Saied, H., Alfahad, O., Aljaffer, A.A. et al. From data to discovery: The rise of information-theoretic predictive models in drug development. Sci Rep 16, 12857 (2026). https://doi.org/10.1038/s41598-026-45644-5
Nyckelord: läkemedelsupptäckt, virtuell screening, prediktiv modellering, bioassay-data, formylpeptidreceptor