Clear Sky Science · it
Da dati a scoperta: L'ascesa dei modelli predittivi basati sulla teoria dell'informazione nello sviluppo di farmaci
Perché accelerare la scoperta di farmaci è importante
Molte malattie gravi sono ancora prive di terapie efficaci e, anche quando si individuano farmaci promettenti, il percorso dall'idea allo scaffale della farmacia è lungo e costoso. Questo articolo esplora come modelli informatici più intelligenti possano setacciare vaste raccolte di dati chimici e biologici per individuare più rapidamente e con maggiore affidabilità alcuni candidati farmaci promettenti. Prendendo in prestito concetti dalla teoria dell'informazione—la matematica di quanto possiamo apprendere dai dati—gli autori mostrano un modo per restringere la ricerca di nuovi medicinali e comprendere meglio cosa renda una molecola probabile di funzionare nell'organismo.
Dal tentativo e errore alla progettazione guidata dai dati
La scoperta tradizionale di farmaci si è basata su una combinazione di ipotesi fondate, screening di laboratorio e, talvolta, fortuite coincidenze come la scoperta della penicillina. Oggi i ricercatori possono testare milioni di composti al computer prima ancora di toccare una provetta. Gli strumenti di screening virtuale classificano le molecole in base al loro comportamento biologico previsto, aiutando gli scienziati a concentrarsi su quelle più promettenti. Tuttavia, molti strumenti esistenti trattano ogni molecola in isolamento o forniscono solo stime probabilistiche approssimative, e spesso fanno fatica a catturare come il contesto biologico reale—ad esempio il modo in cui un farmaco si distribuisce nell'organismo—influisca sul successo o sul fallimento.
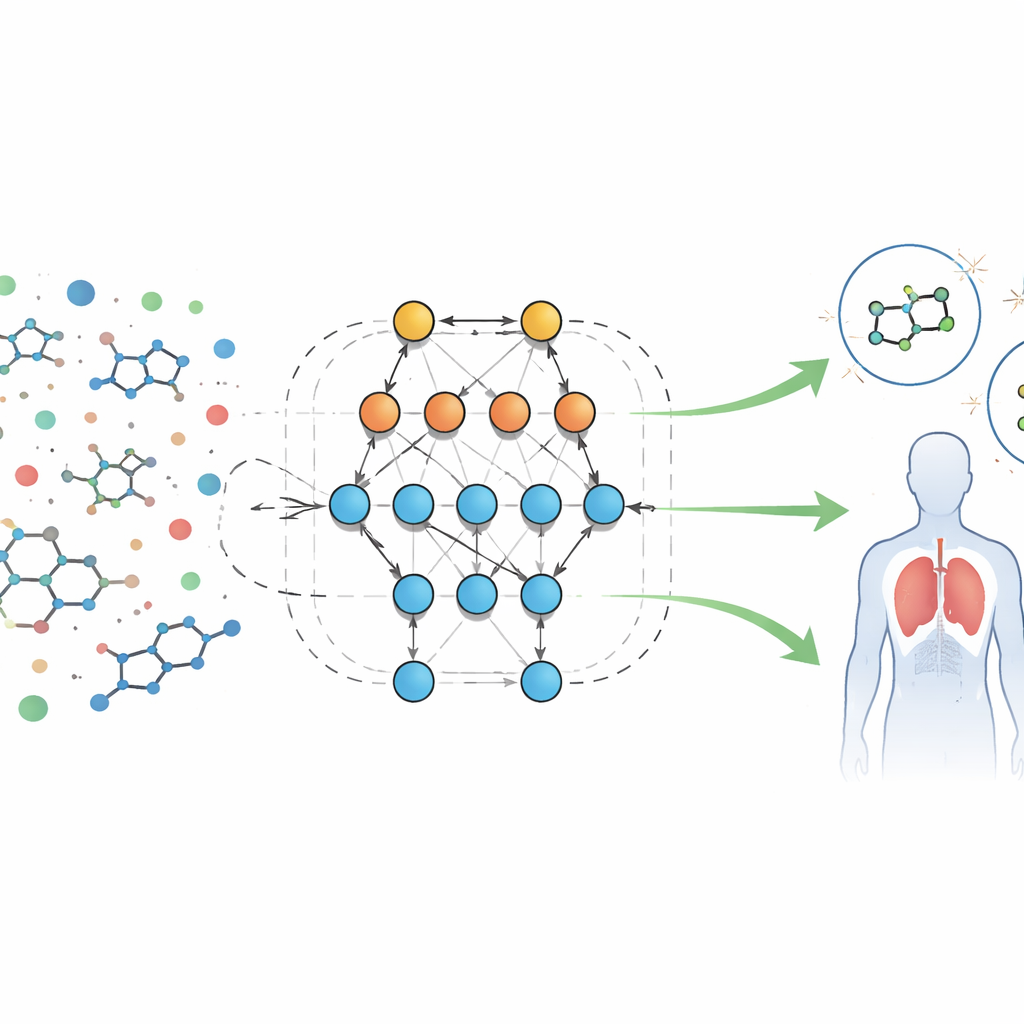
Un nuovo modo di leggere le impronte biologiche
Gli autori analizzano un ampio set di dati pubblici di risultati di screening biologici per molecole rivolte a un recettore peptidico formilico, una proteina coinvolta nell'infiammazione e nelle difese immunitarie. Ogni campione è accompagnato da dozzine di caratteristiche misurabili, o “descrittori”, come dimensione molecolare, facilità di dissoluzione in lipidi o acqua, capacità di attraversare la barriera emato-encefalica e attitudine a formare legami a idrogeno. Invece di scrivere equazioni fisse su come queste caratteristiche dovrebbero comportarsi, il team utilizza un sistema automatizzato chiamato Eidos, che costruisce modelli predittivi basati sulla teoria dell'informazione direttamente dai dati. Questi modelli, indicati come analisi ASC (automated system-cognitive), apprendono come le combinazioni di caratteristiche siano collegate al fatto che un campione risulti attivo (potenzialmente utile) o inattivo nei test biologici.
Pulire i dati e scegliere ciò che conta
I dati di screening del mondo reale sono rumorosi: le misurazioni possono essere incoerenti e alcuni campioni potrebbero non seguire alcun pattern chiaro. Il sistema Eidos filtra prima di tutto questi “artefatti”, rimuovendo oltre mille voci discutibili e mantenendo poco più di duemila campioni affidabili. Esamina poi più di 300 caratteristiche per vedere quali effettivamente aiutano a distinguere campioni attivi da inattivi. Usando concetti della teoria dell'informazione, ogni caratteristica riceve un punteggio in base a quanto riduce l'incertezza sull'esito. L'analisi rivela che solo una minoranza di caratteristiche contiene la maggior parte dell'informazione utile, il che significa che i ricercatori possono ignorare in sicurezza molte misurazioni e mantenere comunque quasi tutto il potere predittivo. Questo snellimento rende i modelli più semplici, più facili da interpretare e più veloci da eseguire.
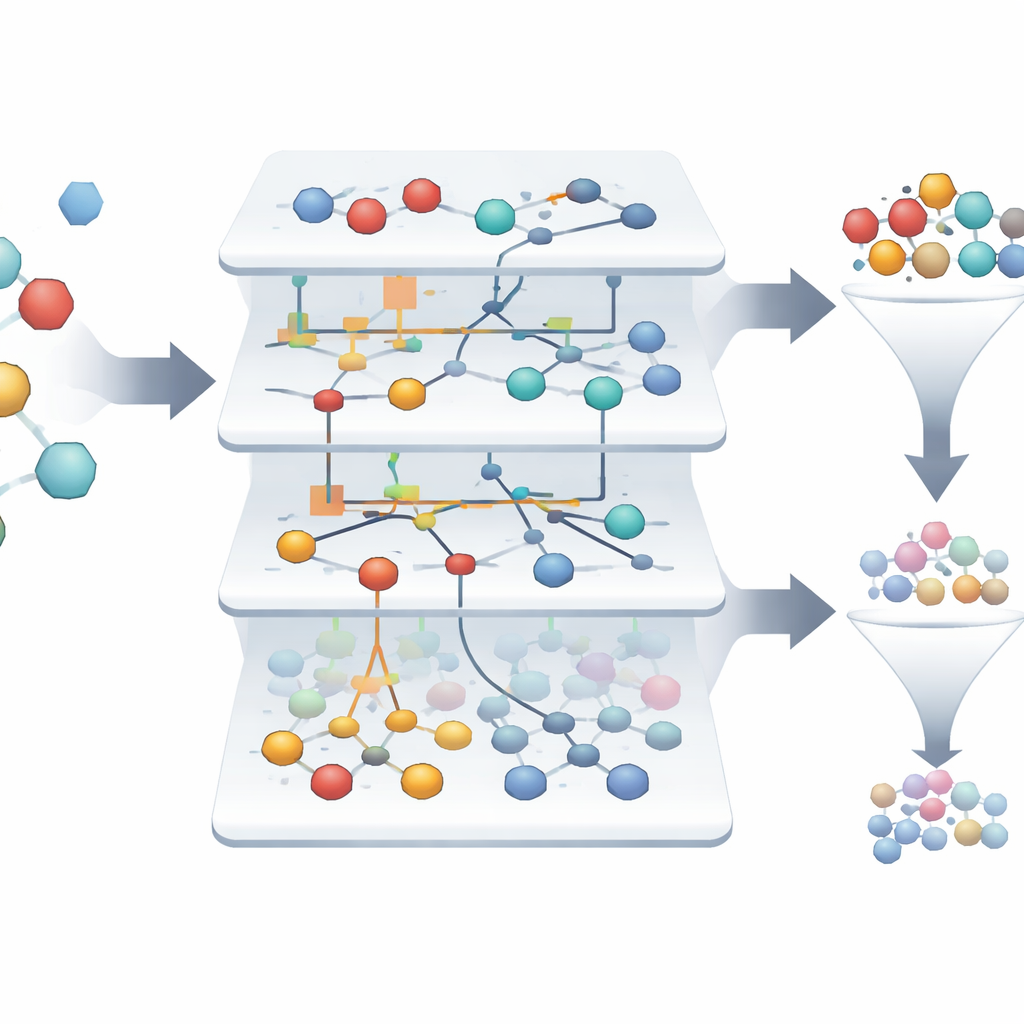
Trovare rari vincitori in un mare di fallimenti
Nel dataset studiato, solo circa l'1,4% delle molecole è davvero attivo, rendendo difficile individuare i pochi vincitori tra migliaia di insuccessi. I modelli basati su ASC costruiscono automaticamente “ritratti informativi” che mostrano quanto fortemente ogni caratteristica e combinazione di caratteristiche spinge un campione verso lo stato attivo o inattivo. Su più di tremila campioni originali, il sistema evidenzia solo due che emergono come candidati altamente affidabili per farmaci diretti al recettore peptidico formilico, con affidabilità del modello che si avvicina al 99,9% nei test retrospettivi. Diagrammi di rete visuali mostrano quali caratteristiche molecolari supportano maggiormente uno stato attivo, offrendo agli scienziati una mappa interpretabile dei fattori che guidano un comportamento promettente.
Come si confronta questo approccio e cosa viene dopo
Gli autori confrontano il loro metodo con strumenti di previsione precoce diffusi come pkCSM, SwissADME e ADMETlab, che stimano come un farmaco viene assorbito, distribuito, metabolizzato ed eliminato. Mentre quei sistemi si basano principalmente su regole predefinite o apprendimento automatico di uso generale, il quadro ASC misura esplicitamente quanto ogni caratteristica contribuisce alla conoscenza acquisita sul comportamento simile a un farmaco e può simulare cambiamenti nel contesto biologico. Allo stesso tempo, lo studio sottolinea limiti: il dataset è relativamente piccolo e fortemente sbilanciato, e il metodo è stato finora applicato a un solo recettore. Gli autori suggeriscono che versioni future potrebbero combinare i modelli ASC con il deep learning ed estendersi a più bersagli.
Cosa significa per i futuri medicinali
In termini pratici, questo lavoro dimostra che modelli ricchi di informazione possono trasformare dati di screening disordinati in previsioni chiare e verificabili su quali molecole meritano ulteriore attenzione. Pulendo automaticamente i dati, classificando l'importanza delle caratteristiche e mettendo in luce composti rari ma promettenti, l'approccio può ridurre il tempo e i costi necessari per arrivare in laboratorio e, infine, in clinica. Pur non sostituendo gli studi su animali o le sperimentazioni umane, funge da filtro e guida potente, aiutando gli scienziati a passare dai dati grezzi a potenziali terapie in modo più efficiente e con maggiore fiducia.
Citazione: Saied, H., Alfahad, O., Aljaffer, A.A. et al. From data to discovery: The rise of information-theoretic predictive models in drug development. Sci Rep 16, 12857 (2026). https://doi.org/10.1038/s41598-026-45644-5
Parole chiave: scoperta di farmaci, screening virtuale, modellazione predittiva, dati di bioassay, recettore peptidico formilico