Clear Sky Science · zh
用于最优控制中安全强化学习的自组织双缓冲自适应聚类经验回放(SODACER)
教机器安全地学习
当计算机学习控制现实系统(例如医疗治疗或机器人)时,我们希望它们在快速改进的同时绝不使人处于风险之中。本文介绍了一种新的学习算法在过去经验上练习的方法,使其既更快又更安全,并展示了该方法如何帮助设计更佳的策略以限制人乳头瘤病毒(HPV)的传播与费用。
为何控制复杂系统如此困难
现代技术常涉及随时间连续变化的系统,从群体中疾病传播到机器人的运动。工程师希望将这些系统引导到健康或高效状态,同时遵守严格的限制,例如安全规则或资源约束。当系统高度复杂、不确定或随时间变化时,传统控制方法可能难以应对。强化学习(通过试错让人工智能体学习)在此情形下很有吸引力,但必须谨慎设计,以免学习过程本身偏离到不安全的区域。
从记忆中学习但不忘安全
许多成功学习系统的关键组成是称为经验回放的记忆机制,算法将过去的交互存储并重复使用以改进决策。基本的回放策略从该记忆中随机抽样,在世界变化时可能既低效又不稳定。作者提出了一种名为自组织双缓冲自适应聚类经验回放(SODACER)的新回放框架。与其保留一个未分化的大记忆,SODACER 将其分为一个记录最新经验的快速缓冲区和一个将旧经验组织为簇的慢速缓冲区,自动修剪冗余以节省空间同时保留多样性。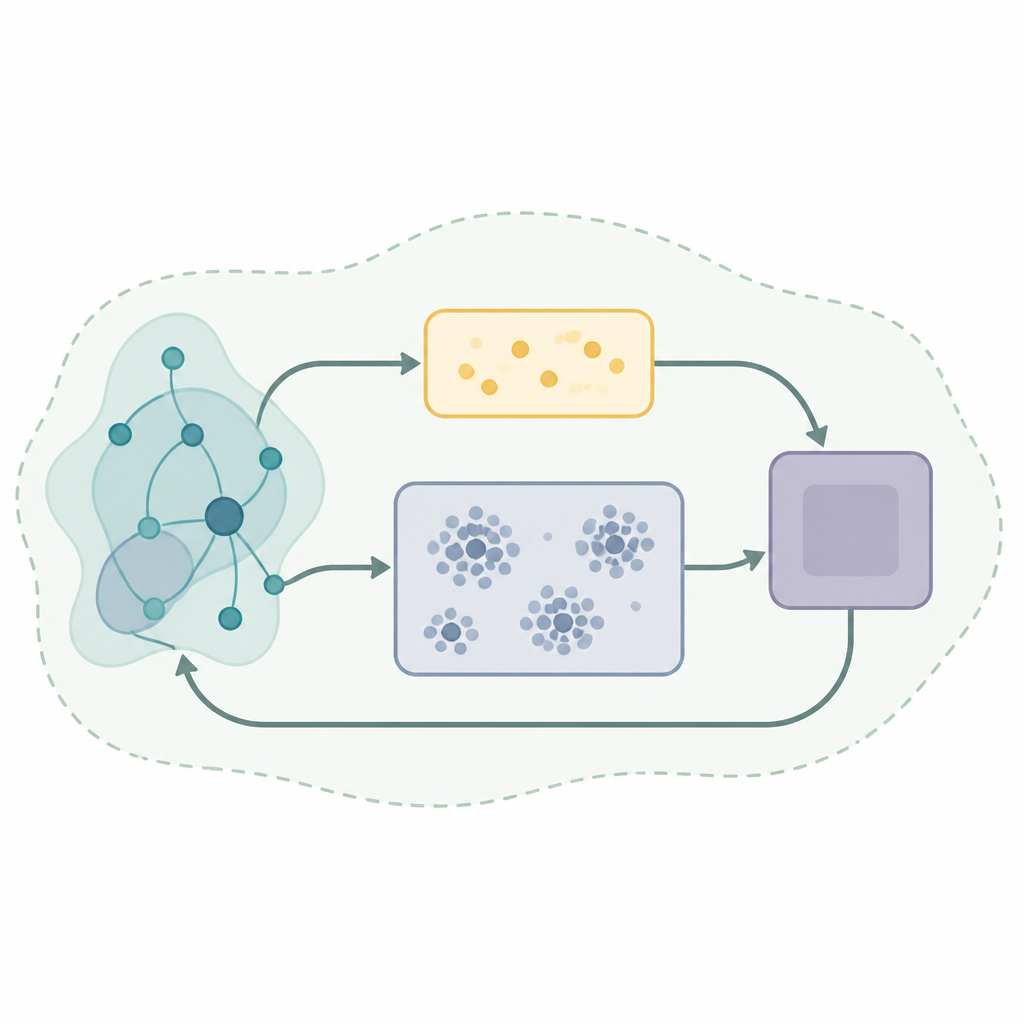
双缓冲记忆如何学习
在 SODACER 中,快速缓冲区捕捉系统和学习智能体的最新行为。这些新鲜样本携带关于当前情形的重要信息,因此即使含噪也能帮助智能体快速调整。随着时间推移,经挑选的经验会被转移到慢速缓冲区,在那里自组织聚类机制将相似情形分组。当两个簇高度重叠时会合并,而变得过窄或无信息价值的簇会被移除。这保持了慢速缓冲区的紧凑但丰富,提供系统在多种条件下行为的广阔视角。学习算法从两者中抽取样本,平衡短期的灵活性与长期的稳定性,减轻统计学习中偏差与方差之间的拉扯。
将学习保持在安全范围内
除了学习高质量的控制策略外,该框架必须确保系统永不违反安全限制。为此,作者将 SODACER 与基于控制屏障函数的安全层相结合。简而言之,强化学习策略提出一个控制动作,安全过滤器会检查该动作是否可能将系统推离预定义的安全区域。如有必要,过滤器会对动作进行最小调整以确保所有安全条件得到满足。这一设计使学习智能体可以专注于提升性能(例如降低疾病负担或成本),而屏障函数则在每一步强制执行安全性。
在 HPV 控制上的方法测试
为了验证该方法,研究人员将 SODACER 应用于包含男女、疫苗接种、筛查和预算限制的详细 HPV 传播模型。目标是在尊重现实疫苗接种和筛查率约束的同时随时间减少感染和相关成本。他们将该方法与另外两种回放策略进行了比较:简单随机回放和基于标准聚类的回放。在五种不同干预情景和 200 次重复模拟中,SODACER 与一种称为 Sophia 的高效优化器配合使用时收敛更快、采样更少且最终成本更低。它在运行间也表现出更低的变异性,表明学习更可靠,并且得益于安全层,在所有测试案例中保持了零约束违规率。
对现实世界控制的意义
简而言之,这项工作展示了如何通过为学习算法提供更智能的记忆和始终在线的安全屏障,产生既有效又可信的控制策略。系统不是盲目探索,而是有选择地记住最有信息量的经验,并将每个建议动作与明确的安全边界进行核对。尽管案例研究聚焦于 HPV,SODACER 及其安全集成背后的思想具有普适性,指向在机器人、医疗保健和大型基础设施系统等多领域实现更安全、更高效的基于学习的控制。
引用: Khalili-Amirabadi, R., Jalaeian-Farimani, M. & Solaymani-Fard, O. Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay (SODACER) for safe reinforcement learning in optimal control. Sci Rep 16, 14960 (2026). https://doi.org/10.1038/s41598-026-44517-1
关键词: 安全强化学习, 经验回放, 双缓冲记忆, HPV 控制, 最优控制