Clear Sky Science · en
Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay (SODACER) for safe reinforcement learning in optimal control
Teaching Machines to Learn Safely
When computers learn to control real-world systems, such as medical treatments or robots, we need them to improve quickly without ever putting people at risk. This paper introduces a new way for learning algorithms to practice on past experience, so they become both faster and safer, and shows how it can help design better strategies to limit the spread and cost of Human Papillomavirus (HPV).
Why Controlling Complex Systems Is Hard
Modern technologies often involve systems that change continuously over time, from disease spread in a population to motion in a robot. Engineers want to steer these systems toward healthy or efficient states while obeying strict limits, such as safety rules or resource constraints. Traditional control methods can struggle when the system is highly complex, uncertain, or changes over time. Reinforcement learning, where an artificial agent learns by trial and error, is attractive here but it must be carefully designed so that the learning process itself does not wander into unsafe territory.
Learning from Memory without Forgetting Safety
A key ingredient in many successful learning systems is a kind of memory called experience replay, where the algorithm stores past interactions and reuses them to improve its decisions. Basic replay strategies draw random samples from this memory, which can be wasteful and unstable when the world is changing. The authors propose a new replay framework named Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay, or SODACER. Instead of keeping one big undifferentiated memory, SODACER splits it into a fast buffer for very recent experiences and a slow buffer that organizes older experiences into clusters, automatically pruning redundant ones to save space while preserving variety. 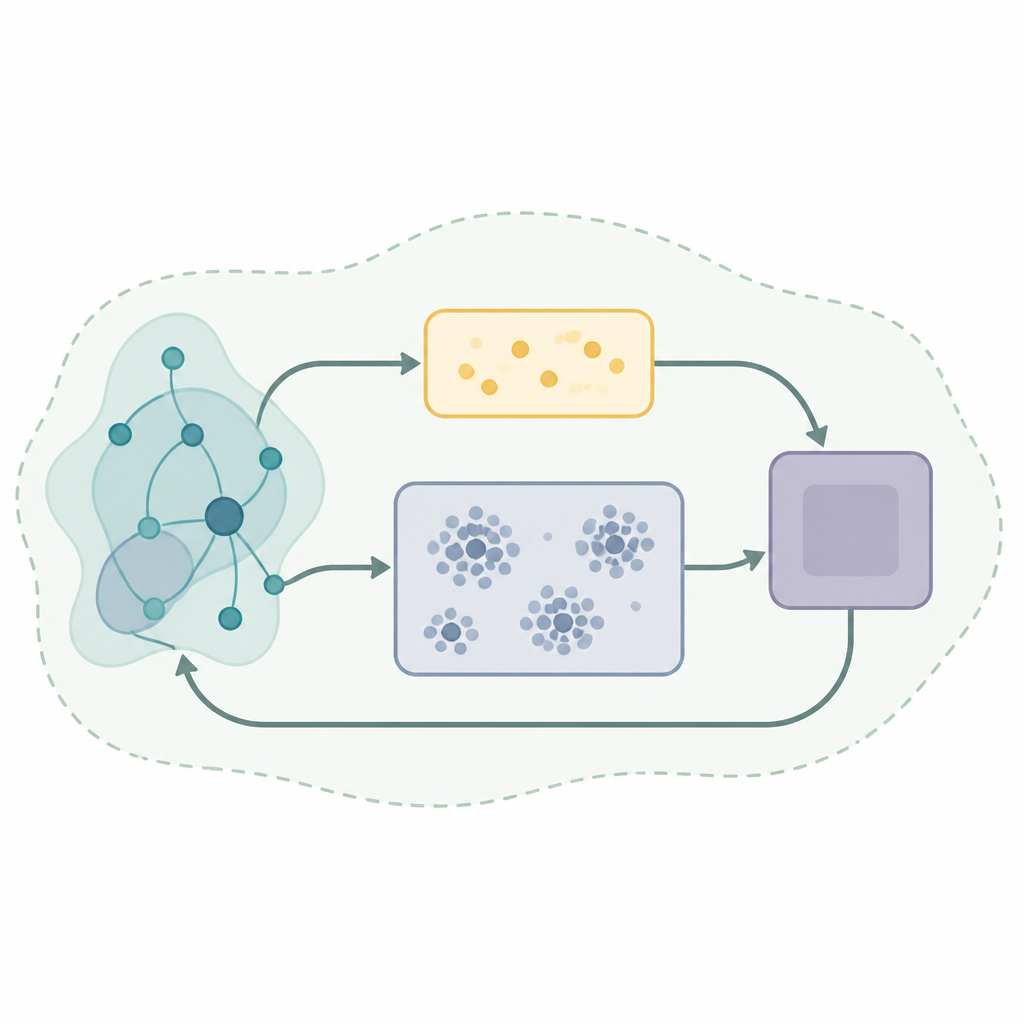
How the Two-Buffer Memory Learns
In SODACER, the fast buffer captures the latest behavior of the system and the learning agent. These fresh samples carry strong information about the current situation, so they help the agent adjust quickly, even if they are noisy. Over time, selected experiences move into the slow buffer, where a self-organizing clustering mechanism groups similar situations together. When two clusters overlap strongly, they are merged, and clusters that become too narrow or uninformative are removed. This keeps the slow buffer compact but rich, offering a broad view of how the system behaves under many different conditions. The learning algorithm draws from both buffers, balancing short-term flexibility with long-term stability and reducing the usual tug-of-war between bias and variance in statistical learning.
Keeping Learning Within Safe Bounds
Beyond learning high-quality control strategies, the framework must ensure that the system never violates safety limits. To achieve this, the authors combine SODACER with a safety layer based on control barrier functions. In simple terms, the reinforcement learning policy proposes a control action, and a safety filter checks whether this action might push the system outside a predefined safe region. If needed, the filter minimally adjusts the action so that all safety conditions remain satisfied. This design allows the learning agent to focus on improving performance, such as lowering disease burden or cost, while the barrier functions enforce safety at every step.
Testing the Method on HPV Control
To demonstrate the approach, the researchers apply SODACER to a detailed model of HPV transmission that includes both men and women, vaccination, screening, and budget limits. The goal is to reduce infections and associated costs over time while respecting realistic constraints on vaccination and screening rates. They compare their method with two other replay strategies: simple random replay and a standard clustering-based replay. Across five different intervention scenarios and 200 repeated simulations, SODACER paired with an efficient optimizer called Sophia converges faster, uses fewer samples, and achieves lower final cost. It also shows lower variability between runs, indicating more reliable learning, and, thanks to the safety layer, maintains a zero rate of constraint violations in all tested cases. 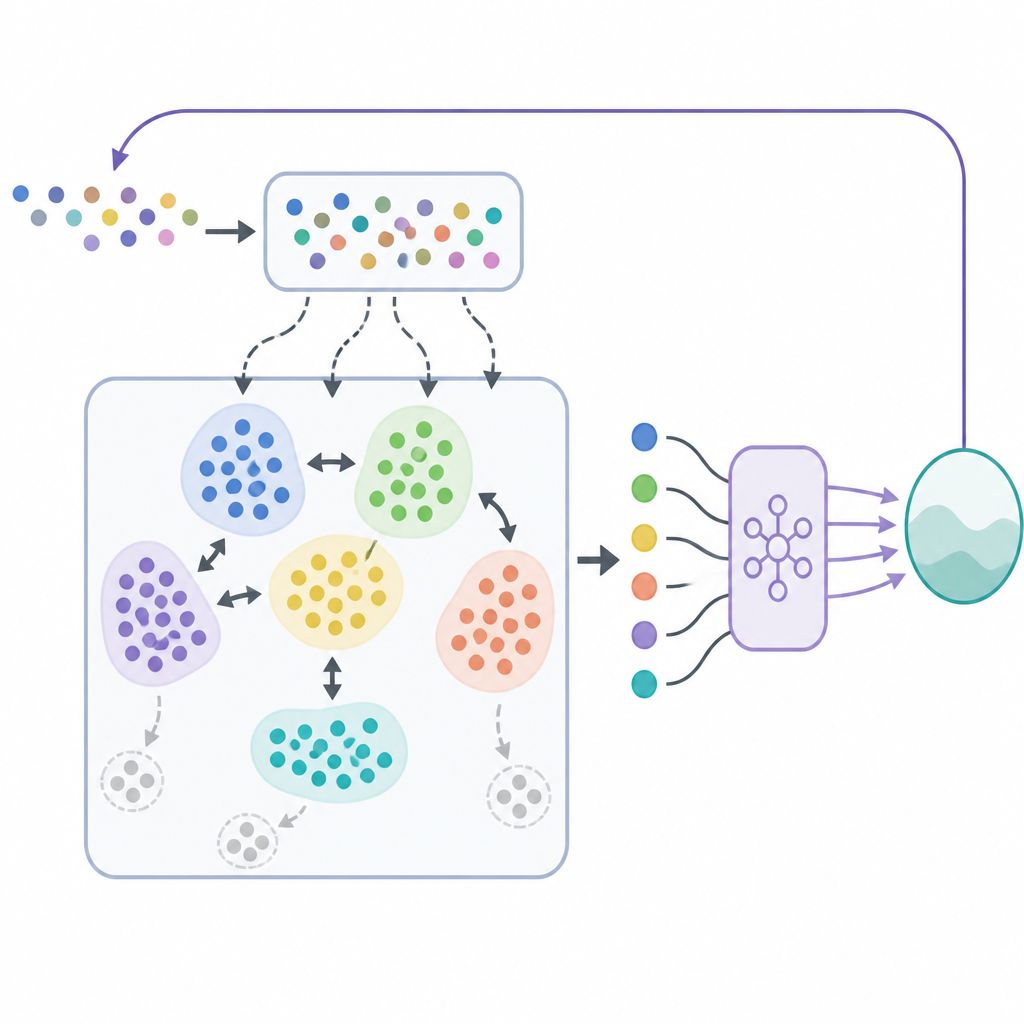
What This Means for Real-World Control
In plain terms, this work shows how giving a learning algorithm a smarter memory and an always-on safety shield can produce control strategies that are both effective and trustworthy. Rather than blindly exploring, the system selectively remembers the most informative experiences and checks each proposed action against clear safety boundaries. While the case study focuses on HPV, the ideas behind SODACER and its safety integration are general, pointing toward safer, more efficient learning-based control in areas as varied as robotics, healthcare, and large infrastructure systems.
Citation: Khalili-Amirabadi, R., Jalaeian-Farimani, M. & Solaymani-Fard, O. Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay (SODACER) for safe reinforcement learning in optimal control. Sci Rep 16, 14960 (2026). https://doi.org/10.1038/s41598-026-44517-1
Keywords: safe reinforcement learning, experience replay, dual-buffer memory, HPV control, optimal control