Clear Sky Science · nl
Zelforganiserende dubbelbuffer adaptieve clustering ervaringherhaling (SODACER) voor veilig reinforcement learning in optimale regeling
Machines leren veilig te handelen
Wanneer computers leren echte systemen te beheersen, zoals medische behandelingen of robots, moeten ze snel verbeteren zonder ooit mensen in gevaar te brengen. Dit artikel introduceert een nieuwe manier waarop leeralgoritmen kunnen oefenen met vroegere ervaringen, zodat ze zowel sneller als veiliger worden, en toont hoe dit kan helpen bij het ontwerpen van betere strategieën om de verspreiding en kosten van humaan papillomavirus (HPV) te beperken.
Waarom het beheersen van complexe systemen moeilijk is
Moderne technologieën omvatten vaak systemen die continu in de tijd veranderen, van de verspreiding van een ziekte in een bevolking tot beweging in een robot. Ingenieurs willen deze systemen sturen naar gezonde of efficiënte toestanden, terwijl ze strikte grenzen respecteren, zoals veiligheidsregels of schaarseresourcebeperkingen. Traditionele regelmethoden kunnen moeite hebben wanneer het systeem zeer complex is, onzekerheden kent of in de loop van de tijd verandert. Reinforcement learning, waarbij een artificiële agent leert door trial-and-error, is aantrekkelijk, maar moet zorgvuldig worden ontworpen zodat het leerproces zelf niet in onveilige gebieden terechtkomt.
Leren uit geheugen zonder veiligheid te vergeten
Een sleutelcomponent in veel succesvolle leersystemen is een soort geheugen dat ervaringherhaling wordt genoemd, waarbij het algoritme eerdere interacties opslaat en hergebruikt om betere beslissingen te nemen. Basisstrategieën voor replay trekken willekeurige monsters uit dit geheugen, wat inefficiënt en instabiel kan zijn wanneer de wereld verandert. De auteurs stellen een nieuw replay-kader voor, genaamd Zelforganiserende Dubbelbuffer Adaptieve Clustering Ervaringherhaling, of SODACER. In plaats van één grote ongestructureerde opslag te houden, splitst SODACER deze in een snelle buffer voor zeer recente ervaringen en een langzame buffer die oudere ervaringen organiseert in clusters, waarbij redundante voorbeelden automatisch worden verwijderd om ruimte te besparen terwijl variatie behouden blijft. 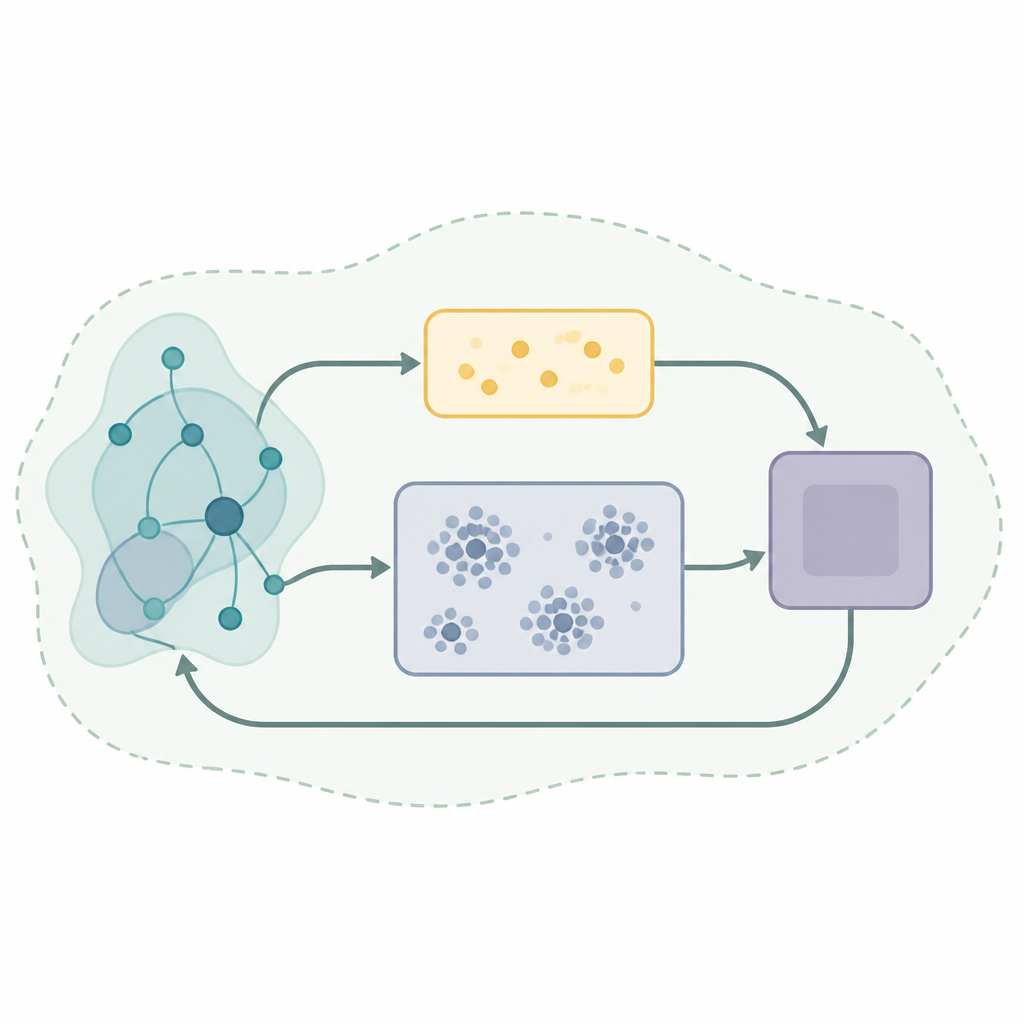
Hoe het tweebuffergeheugen leert
In SODACER vangt de snelle buffer het laatste gedrag van het systeem en de lerende agent op. Deze verse monsters bevatten sterke informatie over de actuele situatie, zodat ze de agent helpen snel bij te sturen, ook al zijn ze luidruchtig. Na verloop van tijd verhuizen geselecteerde ervaringen naar de langzame buffer, waar een zelforganiserend clusteringmechanisme vergelijkbare situaties groepeert. Wanneer twee clusters sterk overlappen, worden ze samengevoegd, en clusters die te smal of weinig informatief worden, worden verwijderd. Dit houdt de langzame buffer compact maar rijk, en biedt een breed beeld van hoe het systeem zich onder verschillende omstandigheden gedraagt. Het leeralgoritme trekt uit beide buffers en balanceert zo kortetermijnflexibiliteit met langetermijnstabiliteit, waardoor de gebruikelijke spanning tussen bias en variantie in statistisch leren wordt verminderd.
Het leerproces binnen veilige grenzen houden
Buiten het leren van hoogwaardige regelstrategieën moet het kader garanderen dat het systeem nooit veiligheidsgrenzen overschrijdt. Om dit te bereiken combineren de auteurs SODACER met een veiligheidslaag gebaseerd op control barrier functions. Simpel gezegd stelt het reinforcement learning-beleid een stuuractie voor en controleert een veiligheidsfilter of deze actie het systeem buiten een vooraf gedefinieerd veilig gebied kan duwen. Indien nodig past de filter de actie minimaal aan zodat alle veiligheidsvoorwaarden gehandhaafd blijven. Dit ontwerp stelt de lerende agent in staat zich te concentreren op prestatieverbetering, zoals het verlagen van ziektelast of kosten, terwijl de barrier functions veiligheid bij elke stap afdwingen.
De methode testen op HPV-beheersing
Om de aanpak te demonstreren passen de onderzoekers SODACER toe op een gedetailleerd model van HPV-transmissie dat zowel mannen als vrouwen, vaccinatie, screening en budgetbeperkingen omvat. Het doel is infecties en bijbehorende kosten in de tijd te verminderen, terwijl realistische beperkingen op vaccinatie- en screeningspercentages worden gerespecteerd. Ze vergelijken hun methode met twee andere replaystrategieën: eenvoudige willekeurige replay en een standaard op clustering gebaseerde replay. Over vijf verschillende interventiescenario's en 200 herhaalde simulaties convergeert SODACER, gecombineerd met een efficiënte optimizer genaamd Sophia, sneller, gebruikt minder monsters en bereikt lagere eindkosten. Het toont ook lagere variabiliteit tussen runs, wat betrouwbaarder leren aangeeft, en dankzij de veiligheidslaag blijft het aantal schendingen van constraints in alle geteste gevallen nul. 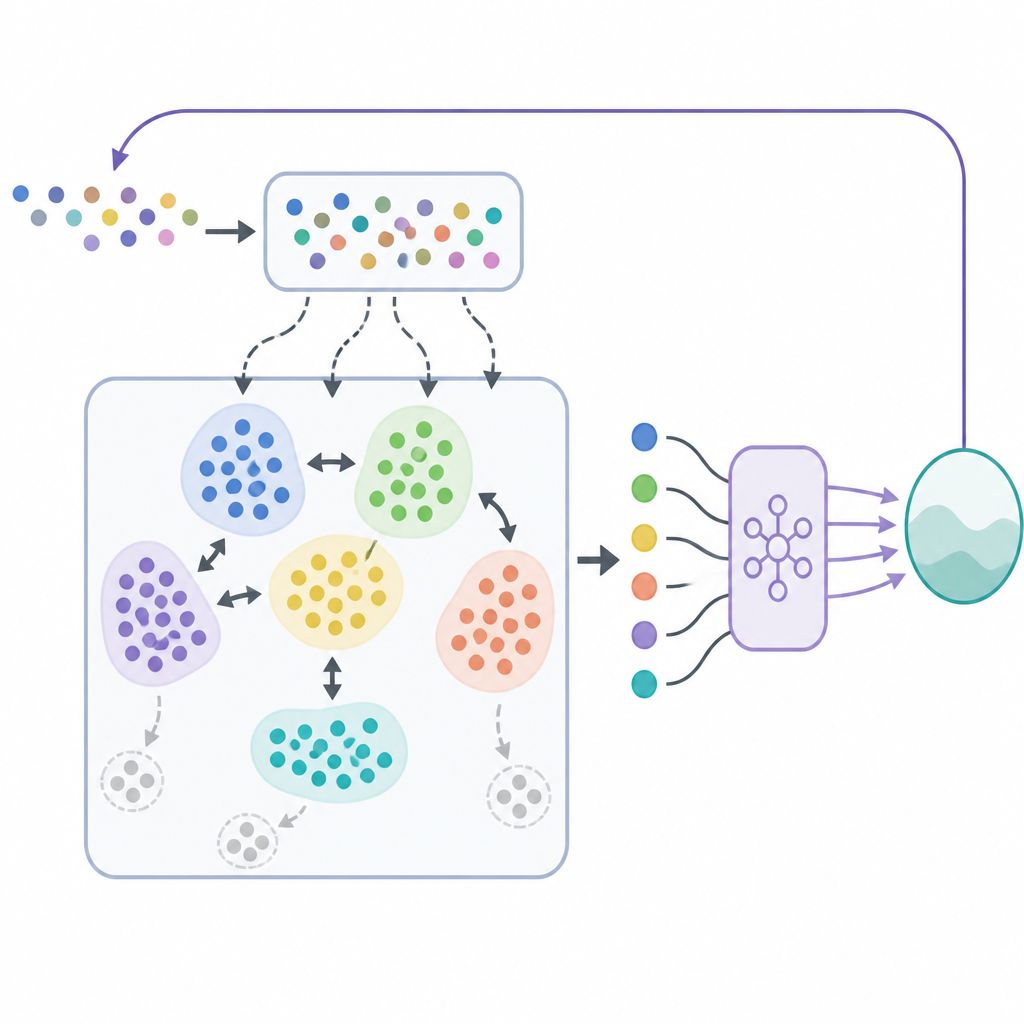
Wat dit betekent voor regeling in de echte wereld
Kort gezegd toont dit werk hoe het geven van een leeralgoritme een slimmer geheugen en een altijd-aan veiligheidsfilter kan leiden tot regelstrategieën die zowel effectief als betrouwbaar zijn. In plaats van blind te verkennen, onthoudt het systeem selectief de meest informatieve ervaringen en controleert het elke voorgestelde actie aan de hand van heldere veiligheidsgrenzen. Hoewel de casestudy zich richt op HPV, zijn de ideeën achter SODACER en de integratie van veiligheid algemeen toepasbaar en wijzen ze op veiliger, efficiënter leergebaseerd regelen in domeinen variërend van robotica en gezondheidszorg tot grote infrastructuursystemen.
Bronvermelding: Khalili-Amirabadi, R., Jalaeian-Farimani, M. & Solaymani-Fard, O. Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay (SODACER) for safe reinforcement learning in optimal control. Sci Rep 16, 14960 (2026). https://doi.org/10.1038/s41598-026-44517-1
Trefwoorden: veilig reinforcement learning, ervaringherhaling, dubbele-buffer geheugen, HPV-beheersing, optimale regeling