Clear Sky Science · pt
SODACER (Replay de Experiência com Agrupamento Adaptativo e Duplo Buffer Auto-Organizante) para aprendizado por reforço seguro em controle ótimo
Ensinar Máquinas a Aprender com Segurança
Quando computadores aprendem a controlar sistemas do mundo real, como tratamentos médicos ou robôs, precisamos que melhorem rapidamente sem jamais colocar pessoas em risco. Este trabalho apresenta uma nova forma de os algoritmos praticarem com base em experiências passadas, tornando-os mais rápidos e seguros, e mostra como isso pode ajudar a projetar estratégias melhores para limitar a disseminação e o custo do Papilomavírus Humano (HPV).
Por Que Controlar Sistemas Complexos é Difícil
Tecnologias modernas frequentemente envolvem sistemas que mudam continuamente ao longo do tempo, desde a propagação de uma doença em uma população até o movimento de um robô. Engenheiros desejam conduzir esses sistemas para estados saudáveis ou eficientes enquanto obedecem limites rígidos, como regras de segurança ou restrições de recursos. Métodos de controle tradicionais podem falhar quando o sistema é altamente complexo, incerto ou muda com o tempo. O aprendizado por reforço, em que um agente artificial aprende por tentativa e erro, é atraente aqui, mas deve ser projetado com cuidado para que o próprio processo de aprendizado não transite por territórios inseguros.
Aprender a Partir da Memória Sem Esquecer a Segurança
Um ingrediente chave em muitos sistemas de aprendizado bem-sucedidos é um tipo de memória chamado replay de experiência, em que o algoritmo armazena interações passadas e as reutiliza para melhorar suas decisões. Estratégias básicas de replay retiram amostras aleatórias dessa memória, o que pode ser ineficiente e instável quando o mundo está mudando. Os autores propõem uma nova estrutura de replay chamada Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay, ou SODACER. Em vez de manter uma única memória grande e indiferenciada, o SODACER a divide em um buffer rápido para experiências muito recentes e um buffer lento que organiza experiências mais antigas em clusters, podando automaticamente as redundantes para economizar espaço enquanto preserva variedade. 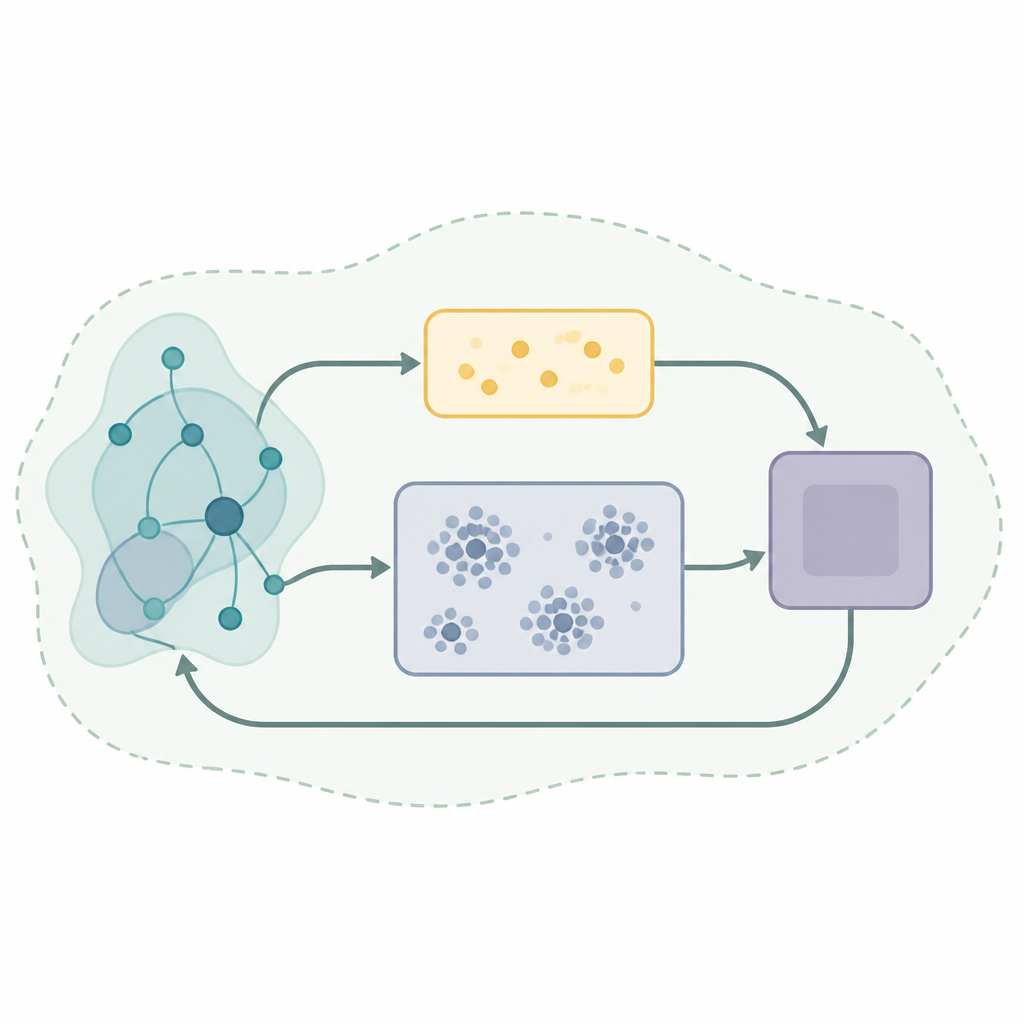
Como a Memória de Dois Buffers Aprende
No SODACER, o buffer rápido captura o comportamento mais recente do sistema e do agente de aprendizado. Essas amostras frescas carregam forte informação sobre a situação atual, ajudando o agente a ajustar-se rapidamente, mesmo que sejam ruidosas. Com o tempo, experiências selecionadas migram para o buffer lento, onde um mecanismo de agrupamento auto-organizante agrupa situações semelhantes. Quando dois clusters se sobrepõem fortemente, são fundidos, e clusters que se tornam muito estreitos ou pouco informativos são removidos. Isso mantém o buffer lento compacto porém rico, oferecendo uma visão ampla de como o sistema se comporta sob muitas condições diferentes. O algoritmo de aprendizado amostra de ambos os buffers, equilibrando flexibilidade de curto prazo com estabilidade de longo prazo e reduzindo o habitual conflito entre viés e variância no aprendizado estatístico.
Manter o Aprendizado Dentro de Limites Seguros
Além de aprender estratégias de controle de alta qualidade, a estrutura deve garantir que o sistema nunca viole limites de segurança. Para isso, os autores combinam o SODACER com uma camada de segurança baseada em funções barreira de controle. Em termos simples, a política de aprendizado por reforço propõe uma ação de controle e um filtro de segurança verifica se essa ação pode empurrar o sistema para fora de uma região segura predefinida. Se necessário, o filtro ajusta minimamente a ação para que todas as condições de segurança permaneçam satisfeitas. Esse desenho permite que o agente foque em melhorar o desempenho, como reduzir a carga da doença ou o custo, enquanto as funções barreira aplicam a segurança a cada passo.
Testando o Método no Controle do HPV
Para demonstrar a abordagem, os pesquisadores aplicam o SODACER a um modelo detalhado de transmissão do HPV que inclui homens e mulheres, vacinação, rastreamento e limites orçamentários. O objetivo é reduzir infecções e custos associados ao longo do tempo, respeitando restrições realistas sobre taxas de vacinação e rastreamento. Eles comparam seu método com duas outras estratégias de replay: replay aleatório simples e um replay padrão baseado em clustering. Em cinco cenários de intervenção diferentes e 200 simulações repetidas, o SODACER emparelhado com um otimizador eficiente chamado Sophia converge mais rápido, usa menos amostras e atinge custo final menor. Também mostra menor variabilidade entre as execuções, indicando aprendizado mais confiável e, graças à camada de segurança, mantém taxa zero de violações de restrições em todos os casos testados. 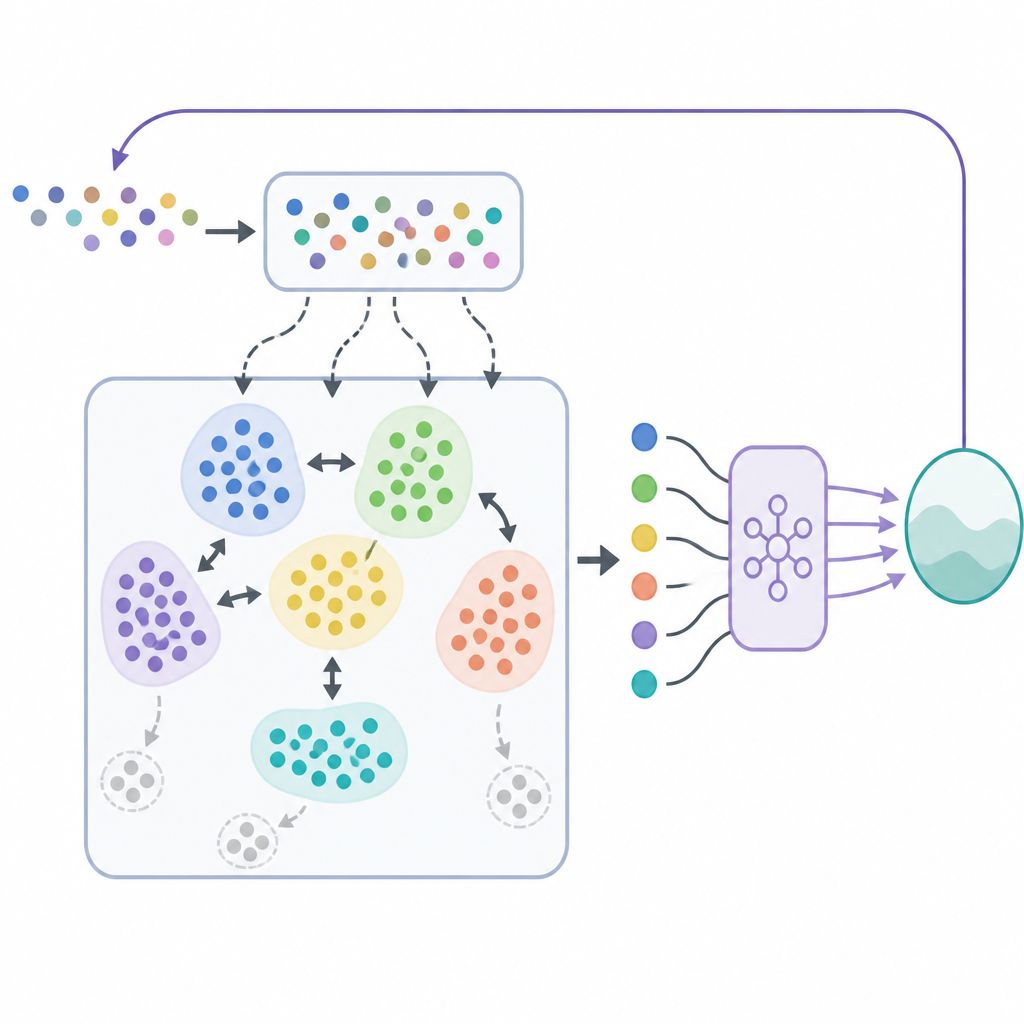
O Que Isso Significa para o Controle do Mundo Real
Em termos práticos, este trabalho demonstra como dar a um algoritmo de aprendizado uma memória mais inteligente e um escudo de segurança sempre ativo pode produzir estratégias de controle eficazes e confiáveis. Em vez de explorar às cegas, o sistema lembra seletivamente as experiências mais informativas e verifica cada ação proposta contra limites de segurança claros. Embora o estudo de caso foque no HPV, as ideias por trás do SODACER e sua integração com segurança são gerais, apontando para um aprendizado baseado em controle mais seguro e eficiente em áreas tão diversas quanto robótica, saúde e grandes sistemas de infraestrutura.
Citação: Khalili-Amirabadi, R., Jalaeian-Farimani, M. & Solaymani-Fard, O. Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay (SODACER) for safe reinforcement learning in optimal control. Sci Rep 16, 14960 (2026). https://doi.org/10.1038/s41598-026-44517-1
Palavras-chave: aprendizado por reforço seguro, replay de experiência, memória com duplo buffer, controle de HPV, controle ótimo