Clear Sky Science · sv
Självorganiserande dubbelbuffert adaptiv klustrings-upplevelseuppspelning (SODACER) för säker förstärkningsinlärning i optimal styrning
Lära maskiner att lära sig säkert
När datorer lär sig styra verkliga system, såsom medicinska behandlingar eller robotar, behöver vi att de förbättras snabbt utan att någonsin utsätta människor för risk. Denna artikel introducerar ett nytt sätt för inlärningsalgoritmer att öva på tidigare erfarenheter, så att de blir både snabbare och säkrare, och visar hur det kan hjälpa till att utforma bättre strategier för att begränsa spridning och kostnader av humant papillomvirus (HPV).
Varför det är svårt att kontrollera komplexa system
Moderna tekniker involverar ofta system som förändras kontinuerligt över tid, från sjukdomsspridning i en population till rörelse i en robot. Ingenjörer vill styra dessa system mot hälsosamma eller effektiva tillstånd samtidigt som de följer strikta gränser, såsom säkerhetsregler eller resursbegränsningar. Traditionella styrmetoder kan ha svårt när systemet är mycket komplext, osäkert eller förändras över tid. Förstärkningsinlärning, där en artificiell agent lär sig genom trial-and-error, är attraktivt här men måste utformas noggrant så att själva inlärningsprocessen inte rör sig in i osäkra områden.
Lära från minnet utan att glömma säkerheten
En nyckelingrediens i många framgångsrika inlärningssystem är en typ av minne kallad experience replay, där algoritmen lagrar tidigare interaktioner och återanvänder dem för att förbättra sina beslut. Enkla uppspelningsstrategier plockar slumpmässiga prover från detta minne, vilket kan vara slösaktigt och instabilt när världen förändras. Författarna föreslår ett nytt uppspelningsramverk kallat Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay, eller SODACER. Istället för att behålla ett stort odifferentierat minne delar SODACER upp det i en snabb buffert för mycket senaste erfarenheter och en långsam buffert som organiserar äldre erfarenheter i kluster, automatiskt beskär redundanta poster för att spara utrymme samtidigt som variation bevaras. 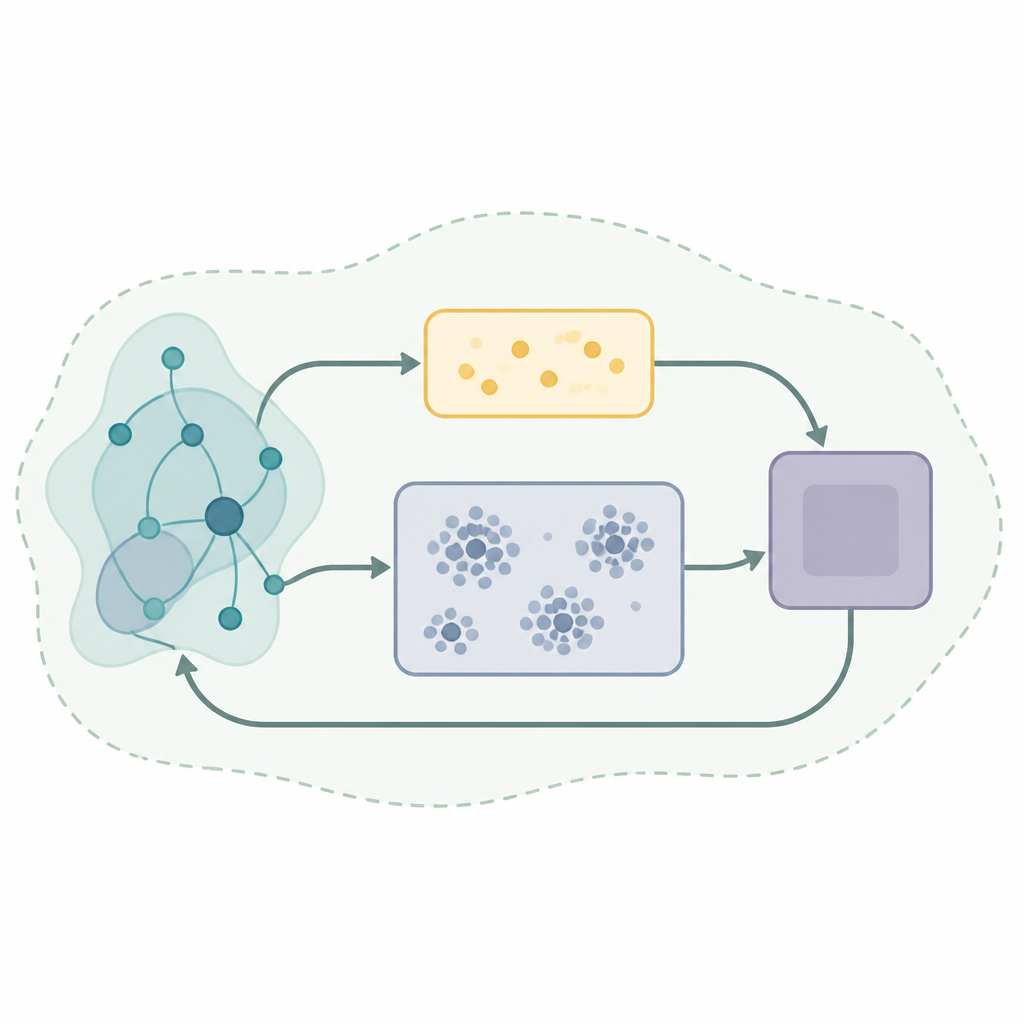
Hur tvåbuffertsminnet lär sig
I SODACER fångar den snabba bufferten upp systemets och agentens senaste beteende. Dessa färska prover bär stark information om den aktuella situationen, så de hjälper agenten att anpassa sig snabbt, även om de är brusiga. Med tiden flyttas utvalda erfarenheter till den långsamma bufferten, där en självorganiserande klustringsmekanism grupperar liknande situationer. När två kluster överlappar starkt slås de ihop, och kluster som blir för snäva eller ointressanta tas bort. Detta håller den långsamma bufferten kompakt men rik, och erbjuder en bred bild av hur systemet beter sig under många olika förhållanden. Inlärningsalgoritmen drar prover från båda buffertarna, vilket balanserar kortsiktig flexibilitet med långsiktig stabilitet och minskar den vanliga dragkampen mellan bias och varians i statistisk inlärning.
Hålla inlärningen inom säkra gränser
Förutom att lära högkvalitativa styrstrategier måste ramverket säkerställa att systemet aldrig bryter säkerhetsgränser. För att uppnå detta kombinerar författarna SODACER med ett säkerhetslager baserat på kontrollbarriärfunktioner. I enkla termer föreslår förstärkningsinlärningspolicyn en styråtgärd, och ett säkerhetsfilter kontrollerar om denna åtgärd kan pressa systemet utanför en fördefinierad säker region. Vid behov justerar filtret åtgärden minimalt så att alla säkerhetsvillkor förblir uppfyllda. Denna konstruktion tillåter inlärningsagenten att fokusera på att förbättra prestanda, såsom att minska sjukdomsbörda eller kostnad, medan barriärfunktionerna upprätthåller säkerhet vid varje steg.
Test av metoden på HPV-styrning
För att demonstrera tillvägagångssättet tillämpar forskarna SODACER på en detaljerad modell av HPV-överföring som inkluderar både män och kvinnor, vaccinering, screening och budgetbegränsningar. Målet är att minska infektioner och associerade kostnader över tid samtidigt som realistiska begränsningar för vaccinations- och screeningsnivåer respekteras. De jämför sin metod med två andra uppspelningsstrategier: enkel slumpmässig uppspelning och en standard klusterbaserad uppspelning. Över fem olika interventionsscenarier och 200 upprepade simuleringar konvergerar SODACER i kombination med en effektiv optimizer kallad Sophia snabbare, använder färre prover och uppnår lägre slutkostnad. Den visar också lägre variation mellan körningar, vilket indikerar mer pålitlig inlärning, och tack vare säkerhetslagret bibehåller den noll frekvens av begränsningsbrott i alla testade fall. 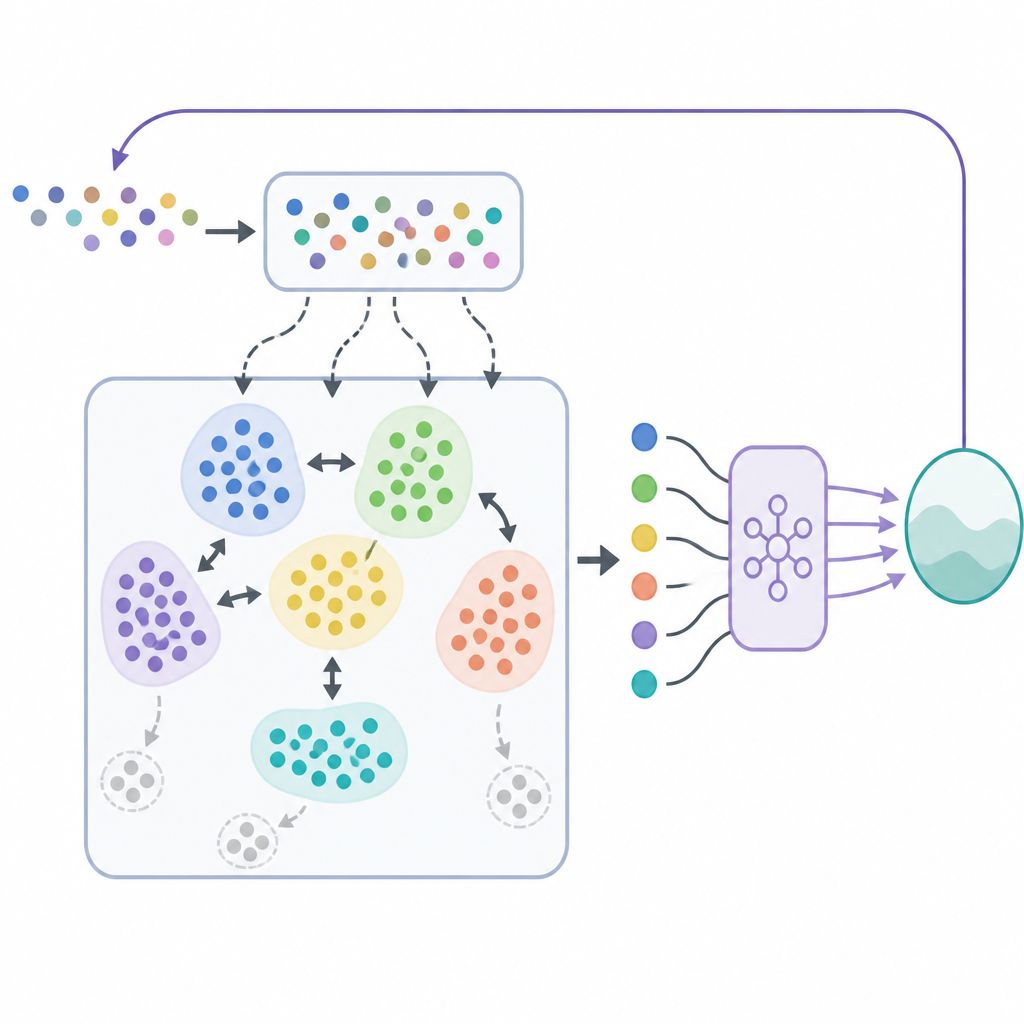
Vad detta betyder för styrning i verkliga världen
Enkelt uttryckt visar detta arbete hur man genom att ge en inlärningsalgoritm ett smartare minne och ett alltid aktivt säkerhetsskydd kan få styrstrategier som är både effektiva och pålitliga. Istället för att blint utforska minns systemet selektivt de mest informativa erfarenheterna och kontrollerar varje föreslagen åtgärd mot tydliga säkerhetsgränser. Medan fallstudien fokuserar på HPV är idéerna bakom SODACER och dess säkerhetsintegration allmängiltiga och pekar mot säkrare, mer effektiva inlärningsbaserade styrningar inom områden så skilda som robotik, sjukvård och stora infrastruktursystem.
Citering: Khalili-Amirabadi, R., Jalaeian-Farimani, M. & Solaymani-Fard, O. Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay (SODACER) for safe reinforcement learning in optimal control. Sci Rep 16, 14960 (2026). https://doi.org/10.1038/s41598-026-44517-1
Nyckelord: säker förstärkningsinlärning, experience replay, dubbelbuffertminne, HPV-styrning, optimal styrning