Clear Sky Science · it
Replay adattivo a doppio buffer auto-organizzante per l’apprendimento per rinforzo sicuro nel controllo ottimo (SODACER)
Insegnare alle macchine a imparare in sicurezza
Quando i computer imparano a governare sistemi del mondo reale, come terapie mediche o robot, è fondamentale che migliorino in fretta senza mettere mai a rischio le persone. Questo articolo introduce un nuovo modo per gli algoritmi di apprendere dalla esperienza passata, così da diventare contemporaneamente più rapidi e più sicuri, e mostra come possa aiutare a progettare strategie migliori per limitare la diffusione e i costi del Papillomavirus umano (HPV).
Perché è difficile controllare sistemi complessi
Le tecnologie moderne spesso coinvolgono sistemi che evolvono continuamente nel tempo, dalla diffusione di una malattia in una popolazione al movimento di un robot. Gli ingegneri vogliono guidare questi sistemi verso stati sani o efficienti rispettando limiti stringenti, come regole di sicurezza o vincoli di risorse. I metodi di controllo tradizionali possono faticare quando il sistema è altamente complesso, incerto o variabile nel tempo. L’apprendimento per rinforzo, in cui un agente artificiale apprende per tentativi ed errori, è attraente in questi casi, ma deve essere progettato con cura affinché il processo di apprendimento non entri in zone insicure.
Imparare dalla memoria senza dimenticare la sicurezza
Un elemento chiave in molti sistemi di apprendimento di successo è una sorta di memoria chiamata experience replay, in cui l’algoritmo conserva interazioni passate e le riutilizza per migliorare le decisioni. Le strategie di replay di base estraggono campioni casuali da questa memoria, cosa che può risultare inefficiente e instabile quando il mondo cambia. Gli autori propongono un nuovo framework di replay chiamato Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay, o SODACER. Anziché mantenere una singola grande memoria indifferenziata, SODACER la suddivide in un buffer veloce per le esperienze più recenti e un buffer lento che organizza le esperienze più vecchie in cluster, potando automaticamente quelle ridondanti per risparmiare spazio preservando però la varietà. 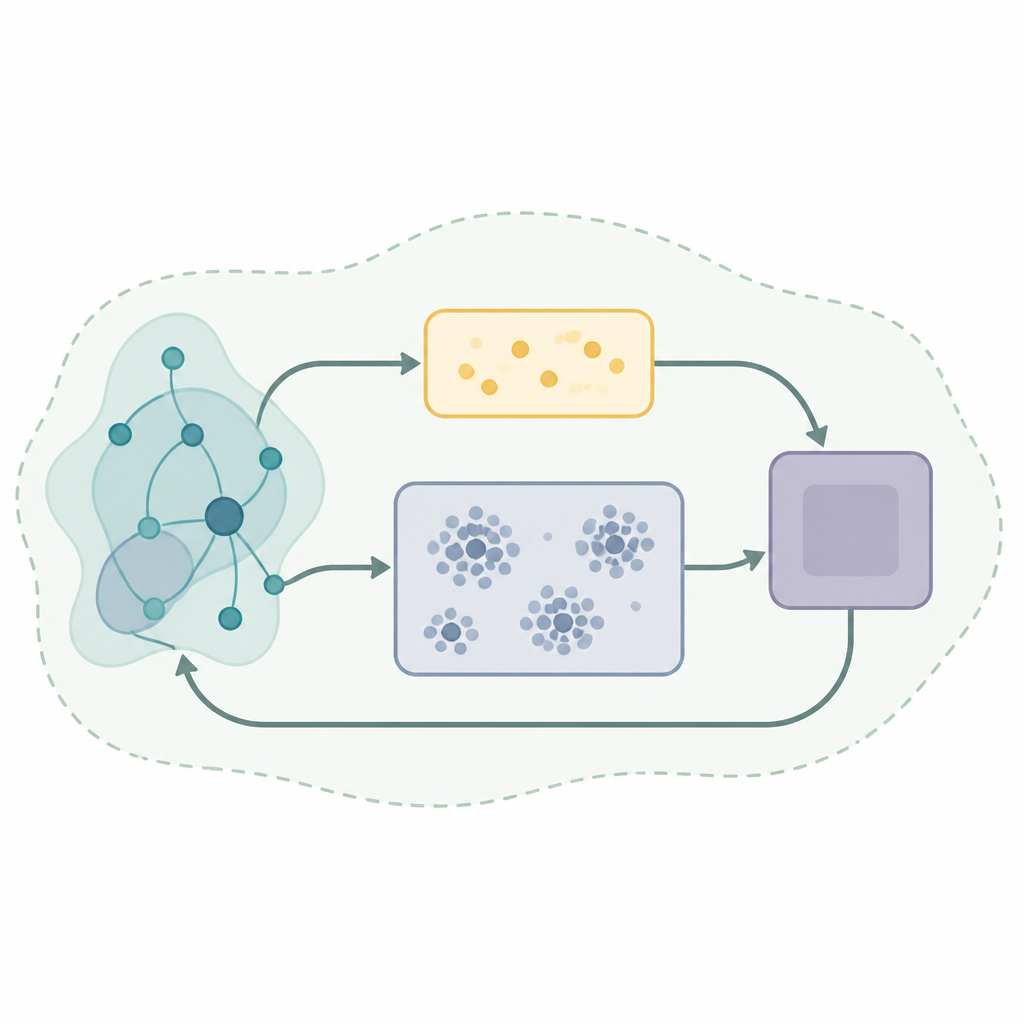
Come apprende la memoria a due buffer
In SODACER, il buffer veloce cattura il comportamento più recente del sistema e dell’agente che impara. Questi campioni freschi contengono informazioni preziose sulla situazione attuale, quindi aiutano l’agente ad adattarsi rapidamente, anche se sono rumorosi. Nel tempo, esperienze selezionate vengono trasferite nel buffer lento, dove un meccanismo di clustering auto-organizzante raggruppa situazioni simili. Quando due cluster si sovrappongono in modo significativo, vengono uniti, e i cluster che diventano troppo ristretti o poco informativi vengono rimossi. Questo mantiene il buffer lento compatto ma ricco, offrendo una visione ampia del comportamento del sistema sotto molte condizioni diverse. L’algoritmo di apprendimento estrae da entrambi i buffer, bilanciando flessibilità a breve termine con stabilità a lungo termine e riducendo la solita tensione tra bias e varianza nell’apprendimento statistico.
Mantenere l’apprendimento entro limiti di sicurezza
Oltre a imparare strategie di controllo di qualità, il framework deve garantire che il sistema non violi mai i limiti di sicurezza. Per ottenere ciò, gli autori combinano SODACER con uno strato di sicurezza basato su funzioni barriera di controllo. In termini semplici, la politica di apprendimento propone un’azione di controllo e un filtro di sicurezza verifica se quell’azione potrebbe spingere il sistema fuori da una regione predefinita sicura. Se necessario, il filtro modifica l’azione in modo minimale affinché tutte le condizioni di sicurezza rimangano soddisfatte. Questa architettura permette all’agente di concentrarsi sul miglioramento della performance, per esempio riducendo l’onere della malattia o i costi, mentre le funzioni barriera fanno rispettare la sicurezza a ogni passo.
Testare il metodo sul controllo dell’HPV
Per dimostrare l’approccio, i ricercatori applicano SODACER a un modello dettagliato della trasmissione dell’HPV che include uomini e donne, vaccinazione, screening e vincoli di budget. L’obiettivo è ridurre le infezioni e i costi associati nel tempo rispettando limiti realistici sui tassi di vaccinazione e screening. Confrontano il loro metodo con due altre strategie di replay: il replay casuale semplice e un replay basato su clustering standard. In cinque scenari d’intervento diversi e con 200 simulazioni ripetute, SODACER abbinato a un ottimizzatore efficiente chiamato Sophia converge più rapidamente, usa meno campioni e raggiunge un costo finale inferiore. Mostra inoltre minore variabilità tra le run, indicando un apprendimento più affidabile, e, grazie allo strato di sicurezza, mantiene un tasso zero di violazioni dei vincoli in tutti i casi testati. 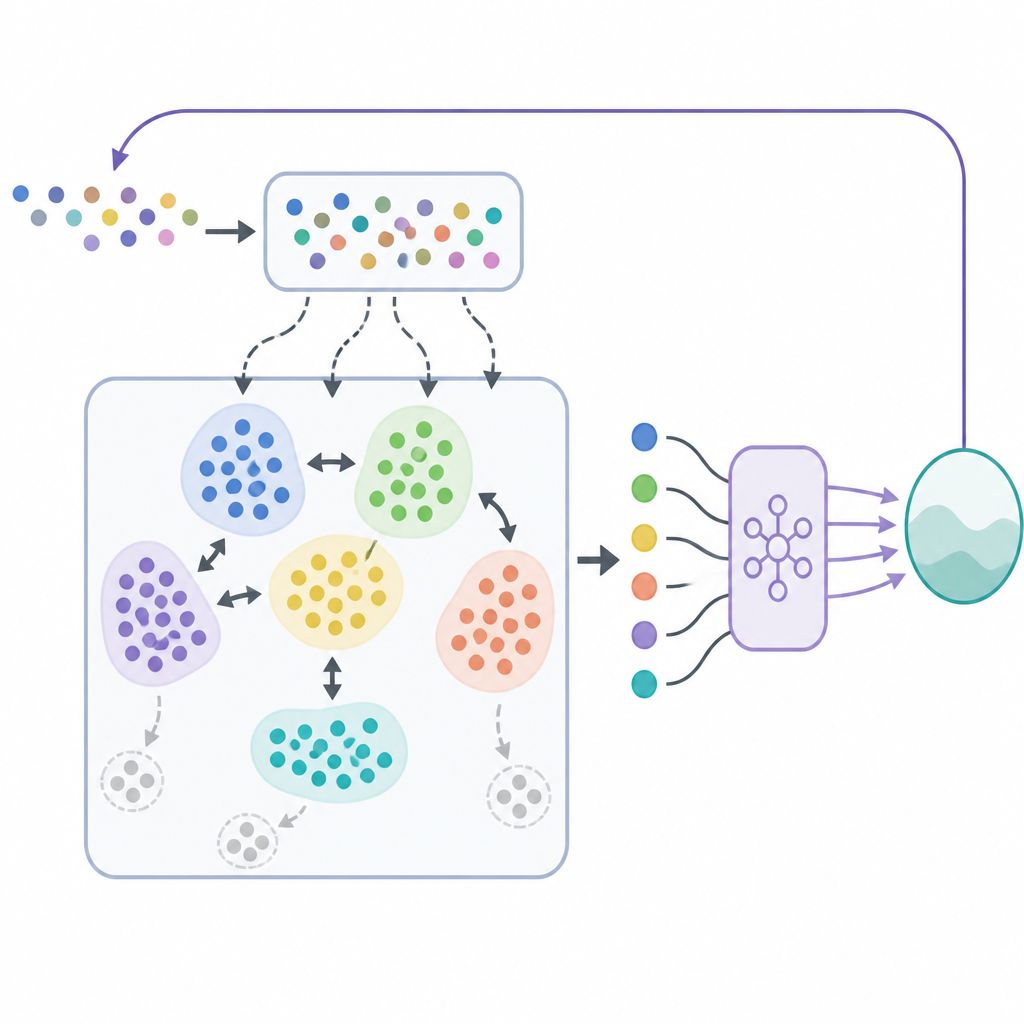
Cosa significa per il controllo nel mondo reale
In termini concreti, questo lavoro mostra come dotare un algoritmo di apprendimento di una memoria più intelligente e di uno scudo di sicurezza sempre attivo possa produrre strategie di controllo efficaci e affidabili. Invece di esplorare alla cieca, il sistema ricorda selettivamente le esperienze più informative e verifica ogni azione proposta rispetto a confini di sicurezza ben definiti. Pur se il caso di studio è centrato sull’HPV, le idee alla base di SODACER e della sua integrazione della sicurezza sono generali, e indicano la strada verso controlli basati sull’apprendimento più sicuri ed efficienti in ambiti come la robotica, la sanità e grandi infrastrutture.
Citazione: Khalili-Amirabadi, R., Jalaeian-Farimani, M. & Solaymani-Fard, O. Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay (SODACER) for safe reinforcement learning in optimal control. Sci Rep 16, 14960 (2026). https://doi.org/10.1038/s41598-026-44517-1
Parole chiave: apprendimento per rinforzo sicuro, experience replay, memoria a doppio buffer, controllo HPV, controllo ottimo