Clear Sky Science · de
Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay (SODACER) für sicheres Reinforcement Learning in der Optimalsteuerung
Maschinen beibringen, sicher zu lernen
Wenn Computer lernen, reale Systeme zu steuern — etwa medizinische Behandlungen oder Roboter — müssen sie sich schnell verbessern, ohne Menschen zu gefährden. Dieses Papier stellt eine neue Methode vor, mit der Lernalgorithmen aus früheren Erfahrungen üben können, sodass sie sowohl schneller als auch sicherer werden, und zeigt, wie dies helfen kann, bessere Strategien zur Eindämmung und Kostensenkung von Humanem Papillomvirus (HPV) zu entwickeln.
Warum die Steuerung komplexer Systeme schwierig ist
Moderne Technologien beinhalten oft Systeme, die sich kontinuierlich über die Zeit verändern — von der Ausbreitung einer Krankheit in einer Bevölkerung bis zur Bewegung eines Roboters. Ingenieure wollen diese Systeme in gesunde oder effiziente Zustände lenken und dabei strikte Grenzwerte einhalten, etwa Sicherheitsregeln oder Ressourcenbeschränkungen. Traditionelle Regelungsverfahren stoßen an ihre Grenzen, wenn das System sehr komplex, unsicher oder zeitlich veränderlich ist. Reinforcement Learning ist hier attraktiv, weil ein künstlicher Agent durch Versuch und Irrtum lernt, doch muss der Lernprozess so gestaltet sein, dass er nicht selbst in unsichere Zustände abgleitet.
Aus dem Gedächtnis lernen, ohne die Sicherheit zu vergessen
Ein Schlüsselelement vieler erfolgreicher Lernsysteme ist ein Gedächtnismechanismus namens Experience Replay, bei dem der Algorithmus vergangene Interaktionen speichert und wiederverwendet, um seine Entscheidungen zu verbessern. Einfache Replay-Strategien ziehen zufällige Stichproben aus diesem Speicher, was verschwenderisch und instabil sein kann, wenn sich die Welt verändert. Die Autorinnen und Autoren schlagen ein neues Replay-Framework namens Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay, kurz SODACER, vor. Anstatt einen großen, undifferenzierten Speicher zu führen, teilt SODACER ihn in einen schnellen Puffer für sehr aktuelle Erfahrungen und einen langsamen Puffer, der ältere Erfahrungen in Cluster organisiert und automatisch redundante Einträge kürzt, um Platz zu sparen und gleichzeitig Vielfalt zu erhalten. 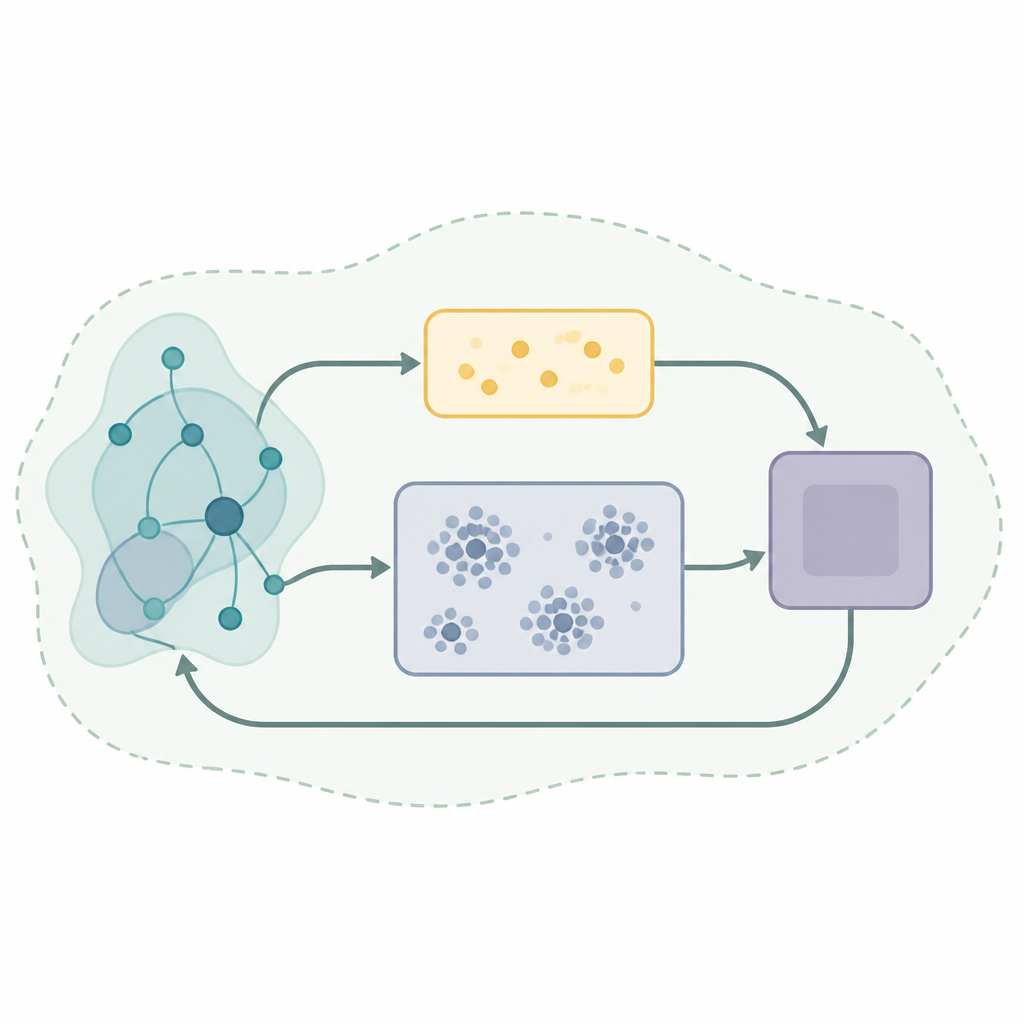
Wie der Zwei-Puffer-Speicher lernt
Im SODACER erfasst der schnelle Puffer das jüngste Verhalten des Systems und des Lernagents. Diese frischen Stichproben enthalten starke Informationen über die aktuelle Lage und helfen dem Agenten, sich schnell anzupassen, auch wenn sie verrauscht sind. Mit der Zeit wandern ausgewählte Erfahrungen in den langsamen Puffer, wo ein selbstorganisierender Clustering-Mechanismus ähnliche Situationen zusammenfasst. Wenn sich zwei Cluster stark überlappen, werden sie zusammengeführt, und Cluster, die zu eng oder uninformativ werden, werden entfernt. So bleibt der langsame Puffer kompakt, aber reichhaltig und bietet einen breiten Überblick darüber, wie sich das System unter vielen Bedingungen verhält. Der Lernalgorithmus zieht aus beiden Puffern, wodurch kurzfristige Flexibilität und langfristige Stabilität ausbalanciert werden und der übliche Zielkonflikt zwischen Verzerrung und Varianz in statistischem Lernen reduziert wird.
Lernen innerhalb sicherer Grenzen halten
Über das Erlernen qualitativ hochwertiger Steuerungsstrategien hinaus muss das Framework sicherstellen, dass das System niemals Sicherheitsgrenzen überschreitet. Dazu kombinieren die Autorinnen und Autoren SODACER mit einer Sicherheitslage, die auf Control Barrier Functions basiert. Vereinfacht ausgedrückt schlägt die Reinforcement-Learning-Policy eine Steueraktion vor, und ein Sicherheitsfilter prüft, ob diese Aktion das System aus einem vordefinierten sicheren Bereich herausdrücken könnte. Falls nötig, passt der Filter die Aktion minimal an, sodass alle Sicherheitsbedingungen weiterhin erfüllt sind. Dieses Design erlaubt es dem Lernagenten, sich auf Leistungsverbesserungen zu konzentrieren, etwa die Krankheitslast oder Kosten zu senken, während die Barrierfunktionen die Sicherheit in jedem Schritt durchsetzen.
Methodenprüfung an der HPV-Steuerung
Zur Demonstration wenden die Forschenden SODACER auf ein detailliertes Modell der HPV-Übertragung an, das Männer und Frauen, Impfung, Screening und Budgetgrenzen umfasst. Ziel ist es, Infektionen und die damit verbundenen Kosten im Laufe der Zeit zu reduzieren und gleichzeitig realistische Beschränkungen bei Impf- und Screeningraten einzuhalten. Sie vergleichen ihre Methode mit zwei anderen Replay-Strategien: einfachem zufälligem Replay und einem Standard-Cluster-basierten Replay. Über fünf verschiedene Interventionsszenarien und 200 wiederholte Simulationen konvergiert SODACER in Verbindung mit einem effizienten Optimierer namens Sophia schneller, benötigt weniger Stichproben und erzielt geringere Endkosten. Es zeigt außerdem weniger Variabilität zwischen den Läufen, was auf zuverlässigeres Lernen hindeutet, und dank der Sicherheitsschicht bleibt die Rate der Verletzungen von Beschränkungen in allen getesteten Fällen bei null. 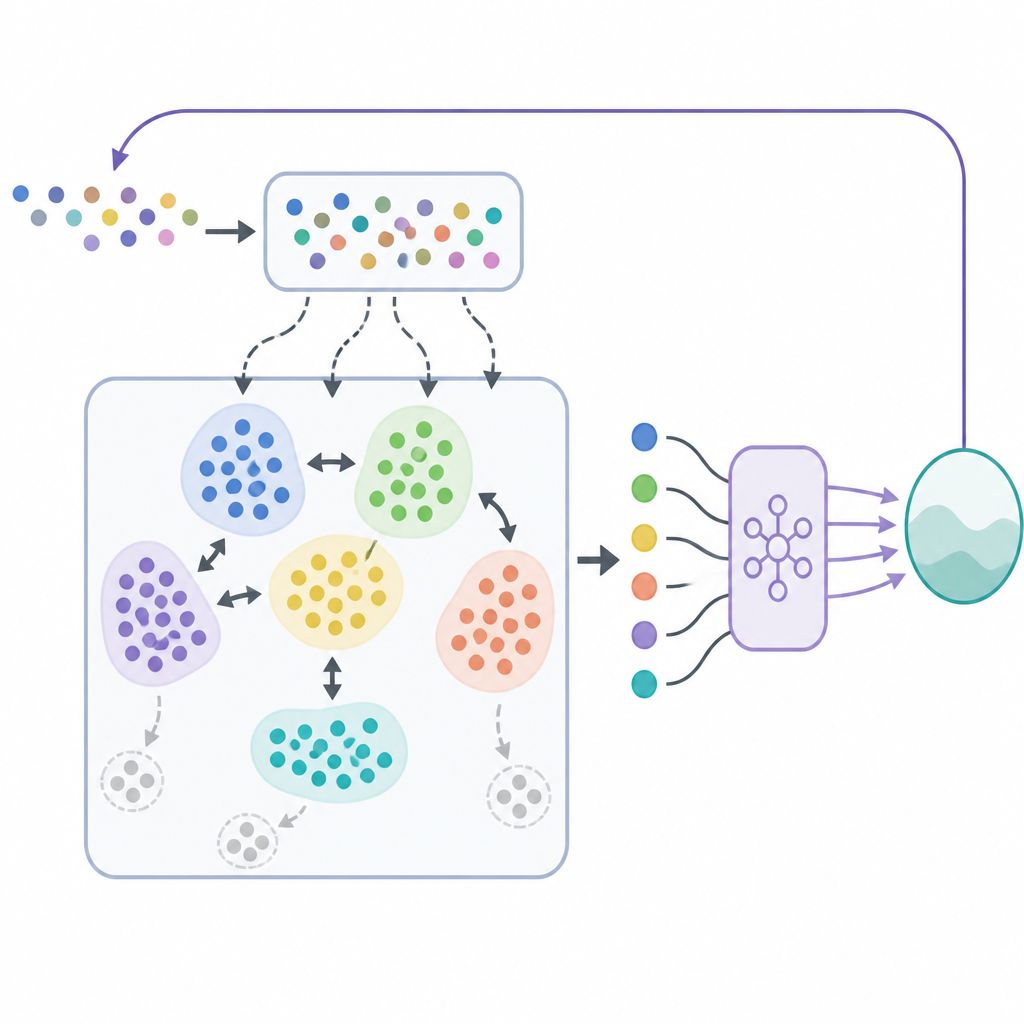
Was das für die Steuerung in der Praxis bedeutet
Einfach gesagt zeigt diese Arbeit, wie ein Lernalgorithmus mit einem intelligenteren Gedächtnis und einem permanent aktiven Sicherheitsschutz Steuerungsstrategien hervorbringen kann, die sowohl wirksam als auch vertrauenswürdig sind. Anstatt blind zu explorieren, merkt sich das System selektiv die informativsten Erfahrungen und prüft jede vorgeschlagene Aktion an klaren Sicherheitsgrenzen. Obwohl die Fallstudie auf HPV fokussiert, sind die Ideen hinter SODACER und seiner Sicherheitsintegration allgemein anwendbar und weisen den Weg zu sichererem, effizienterem lernbasiertem Steuern in Bereichen wie Robotik, Gesundheitswesen und großen Infrastruktursystemen.
Zitation: Khalili-Amirabadi, R., Jalaeian-Farimani, M. & Solaymani-Fard, O. Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay (SODACER) for safe reinforcement learning in optimal control. Sci Rep 16, 14960 (2026). https://doi.org/10.1038/s41598-026-44517-1
Schlüsselwörter: sicheres Reinforcement Learning, Experience Replay, Dual-Buffer-Speicher, HPV-Steuerung, Optimalsteuerung