Clear Sky Science · fr
Rejeu d'expérience adaptatif auto-organisé à double tampon (SODACER) pour l'apprentissage par renforcement sécurisé en contrôle optimal
Apprendre aux machines à apprendre en sécurité
Lorsque des ordinateurs apprennent à piloter des systèmes du monde réel, comme des traitements médicaux ou des robots, il faut qu'ils s'améliorent rapidement sans jamais mettre des personnes en danger. Cet article introduit une nouvelle manière pour les algorithmes d'apprentissage de s'entraîner sur des expériences passées, afin d'être à la fois plus rapides et plus sûrs, et montre comment cela peut aider à concevoir de meilleures stratégies pour limiter la propagation et le coût du virus du papillome humain (VPH).
Pourquoi il est difficile de contrôler des systèmes complexes
Les technologies modernes impliquent souvent des systèmes qui évoluent en continu dans le temps, de la propagation d'une maladie dans une population au mouvement d'un robot. Les ingénieurs cherchent à orienter ces systèmes vers des états sains ou efficaces tout en respectant des limites strictes, comme des règles de sécurité ou des contraintes de ressources. Les méthodes de contrôle traditionnelles peuvent buter lorsque le système est très complexe, incertain ou changeant. L'apprentissage par renforcement, où un agent artificiel apprend par essai-erreur, est séduisant dans ce contexte mais doit être conçu avec soin pour que le processus d'apprentissage lui-même n'explore pas des zones dangereuses.
Apprendre depuis la mémoire sans oublier la sécurité
Un ingrédient clé de nombreux systèmes d'apprentissage performants est une forme de mémoire appelée rejeu d'expérience, où l'algorithme stocke des interactions passées et les réutilise pour améliorer ses décisions. Les stratégies de rejeu classiques prélèvent des échantillons aléatoires dans cette mémoire, ce qui peut être inefficace et instable lorsque l'environnement évolue. Les auteurs proposent un nouveau cadre de rejeu nommé Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay, ou SODACER. Plutôt que de conserver une grande mémoire indifférenciée, SODACER la divise en un tampon rapide pour les expériences très récentes et un tampon lent qui organise les expériences plus anciennes en grappes, élaguant automatiquement les redondances pour économiser de l'espace tout en préservant la diversité. 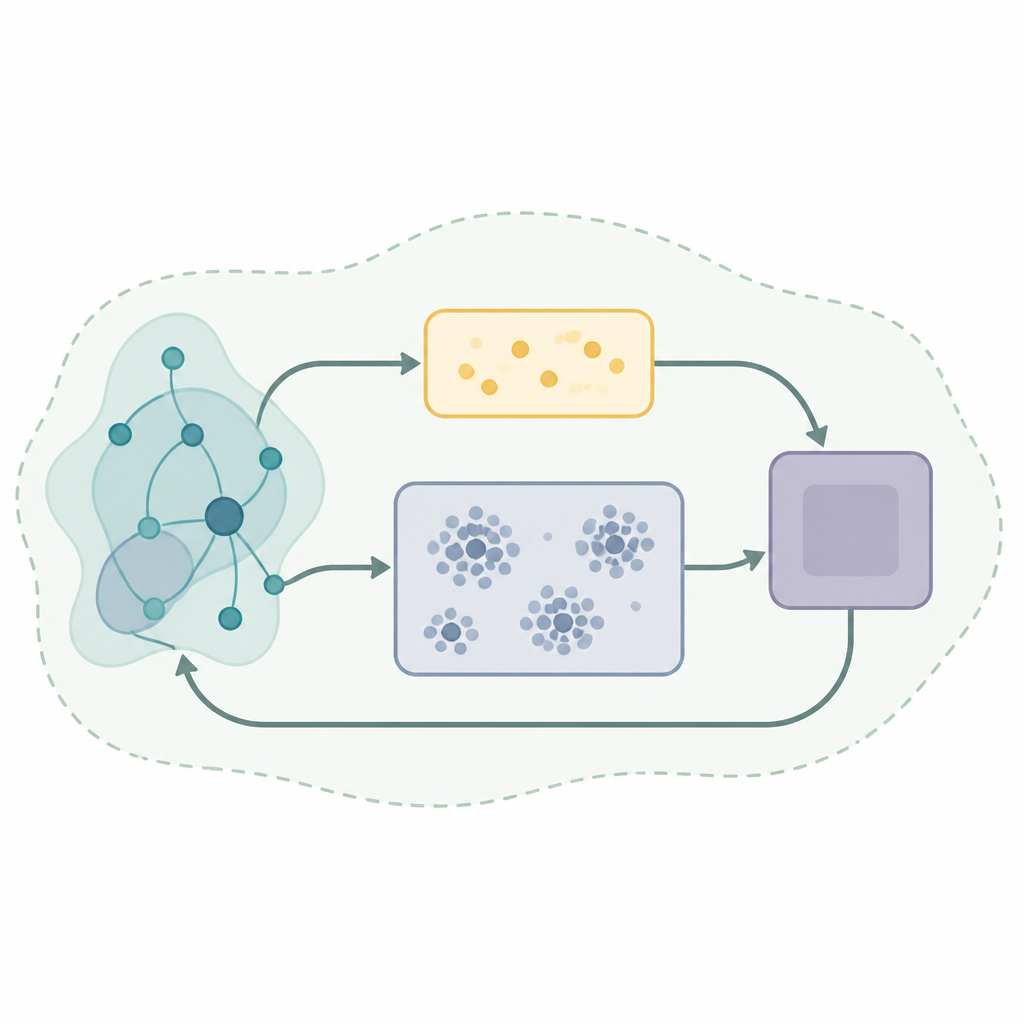
Comment la mémoire à deux tampons apprend
Dans SODACER, le tampon rapide capture le comportement le plus récent du système et de l'agent apprenant. Ces échantillons récents portent une information forte sur la situation actuelle, ce qui aide l'agent à s'adapter rapidement, même s'ils sont bruités. Au fil du temps, des expériences sélectionnées sont déplacées vers le tampon lent, où un mécanisme de clustering auto-organisé regroupe les situations similaires. Lorsque deux grappes se chevauchent fortement, elles sont fusionnées, et les grappes devenues trop étroites ou peu informatives sont supprimées. Cela maintient le tampon lent compact mais riche, offrant une vue large du comportement du système sous différentes conditions. L'algorithme d'apprentissage puise dans les deux tampons, équilibrant flexibilité à court terme et stabilité à long terme et réduisant le traditionnel compromis biais-variance en apprentissage statistique.
Maintenir l'apprentissage dans des limites sûres
Au-delà de l'apprentissage de stratégies de contrôle performantes, le cadre doit garantir que le système ne viole jamais les limites de sécurité. Pour cela, les auteurs combinent SODACER avec une couche de sécurité fondée sur des fonctions barrières de contrôle. En termes simples, la politique d'apprentissage par renforcement propose une action de contrôle, et un filtre de sécurité vérifie si cette action risquerait de pousser le système en dehors d'une région sûre prédéfinie. Si nécessaire, le filtre ajuste l'action au minimum pour que toutes les contraintes de sécurité restent satisfaites. Ce dispositif permet à l'agent d'apprentissage de se concentrer sur l'amélioration des performances, comme la réduction de la charge de maladie ou du coût, tandis que les fonctions barrières font respecter la sécurité à chaque étape.
Tester la méthode sur le contrôle du VPH
Pour démontrer l'approche, les chercheurs appliquent SODACER à un modèle détaillé de transmission du VPH incluant hommes et femmes, vaccination, dépistage et limites budgétaires. L'objectif est de réduire les infections et les coûts associés au fil du temps tout en respectant des contraintes réalistes sur les taux de vaccination et de dépistage. Ils comparent leur méthode à deux autres stratégies de rejeu : le rejeu aléatoire simple et un rejeu standard basé sur le clustering. Sur cinq scénarios d'intervention différents et 200 simulations répétées, SODACER associé à un optimiseur efficace appelé Sophia converge plus rapidement, utilise moins d'échantillons et atteint un coût final inférieur. Il montre aussi une variabilité plus faible entre les exécutions, indiquant un apprentissage plus fiable, et, grâce à la couche de sécurité, maintient un taux nul de violations de contraintes dans tous les cas testés. 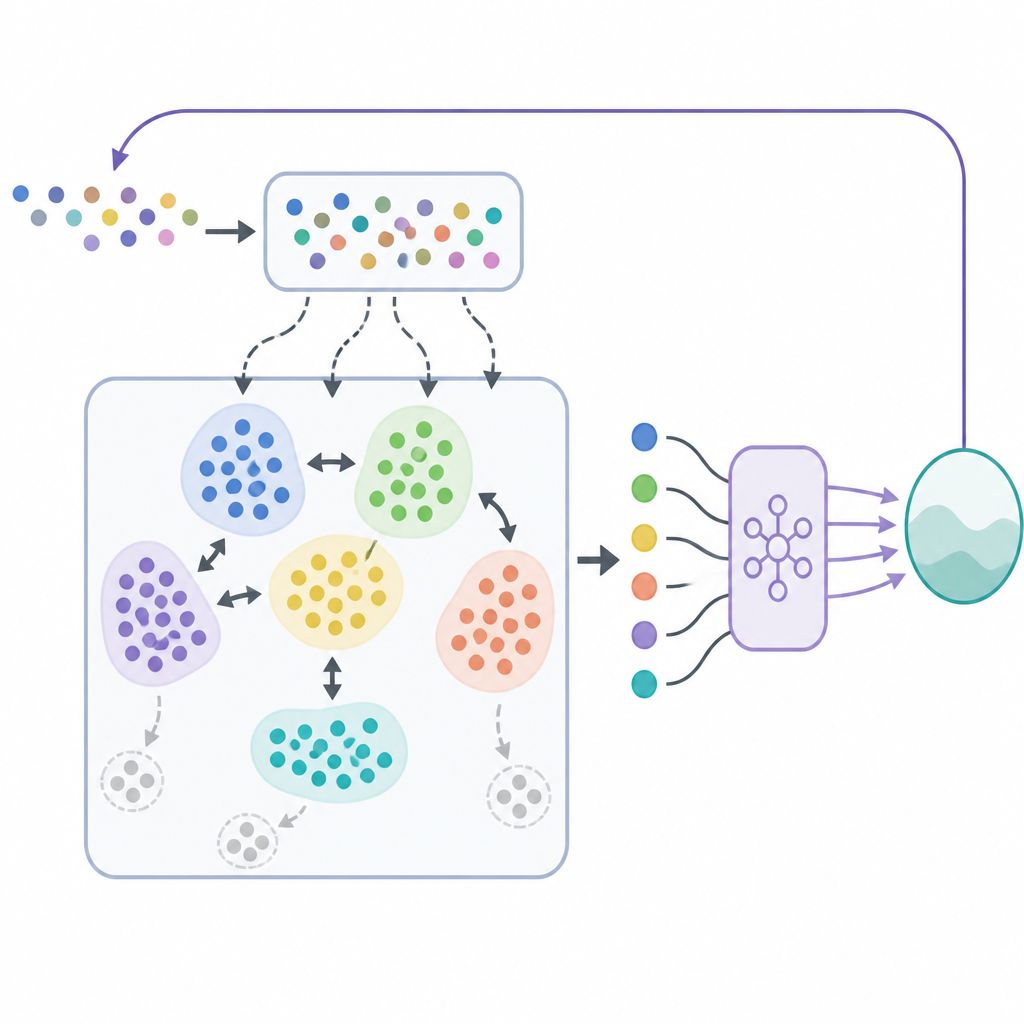
Ce que cela signifie pour le contrôle dans le monde réel
En termes clairs, ce travail montre comment fournir à un algorithme d'apprentissage une mémoire plus intelligente et un bouclier de sécurité permanent peut produire des stratégies de contrôle à la fois efficaces et dignes de confiance. Plutôt que d'explorer aveuglément, le système se souvient sélectivement des expériences les plus informatives et vérifie chaque action proposée par rapport à des frontières de sécurité explicites. Bien que l'étude de cas se concentre sur le VPH, les idées derrière SODACER et son intégration de la sécurité sont générales, ouvrant la voie à un contrôle fondé sur l'apprentissage plus sûr et plus efficace dans des domaines aussi variés que la robotique, la santé et les grandes infrastructures.
Citation: Khalili-Amirabadi, R., Jalaeian-Farimani, M. & Solaymani-Fard, O. Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay (SODACER) for safe reinforcement learning in optimal control. Sci Rep 16, 14960 (2026). https://doi.org/10.1038/s41598-026-44517-1
Mots-clés: apprentissage par renforcement sécurisé, rejeu d'expérience, mémoire à double tampon, contrôle du VPH, contrôle optimal