Clear Sky Science · es
SODACER: Repetición de Experiencias con Agrupación Adaptativa y Doble Búfer Autoorganizado para aprendizaje por refuerzo seguro en control óptimo
Enseñar a las máquinas a aprender con seguridad
Cuando los ordenadores aprenden a controlar sistemas del mundo real, como tratamientos médicos o robots, necesitamos que mejoren con rapidez sin poner a las personas en riesgo. Este artículo presenta una nueva forma para que los algoritmos de aprendizaje practiquen con experiencias pasadas, de modo que sean a la vez más rápidos y más seguros, y muestra cómo puede ayudar a diseñar mejores estrategias para limitar la propagación y el coste del Virus del Papiloma Humano (VPH).
Por qué es difícil controlar sistemas complejos
Las tecnologías modernas suelen implicar sistemas que cambian continuamente en el tiempo, desde la propagación de una enfermedad en una población hasta el movimiento de un robot. Los ingenieros quieren dirigir estos sistemas hacia estados saludables o eficientes respetando límites estrictos, como normas de seguridad o restricciones de recursos. Los métodos de control tradicionales pueden tener dificultades cuando el sistema es muy complejo, incierto o cambia con el tiempo. El aprendizaje por refuerzo, en el que un agente artificial aprende por ensayo y error, resulta atractivo aquí, pero debe diseñarse con cuidado para que el propio proceso de aprendizaje no se desplace hacia territorios inseguros.
Aprender de la memoria sin olvidar la seguridad
Un ingrediente clave en muchos sistemas de aprendizaje exitosos es un tipo de memoria llamado repetición de experiencias, donde el algoritmo almacena interacciones pasadas y las reutiliza para mejorar sus decisiones. Las estrategias básicas de repetición toman muestras aleatorias de esta memoria, lo que puede ser ineficiente e inestable cuando el mundo cambia. Los autores proponen un nuevo marco de repetición llamado Repetición de Experiencias con Agrupación Adaptativa y Doble Búfer Autoorganizado, o SODACER. En lugar de mantener una memoria única e indiferenciada, SODACER la divide en un búfer rápido para experiencias muy recientes y un búfer lento que organiza las experiencias más antiguas en clústeres, podando automáticamente las redundantes para ahorrar espacio mientras preserva la variedad. 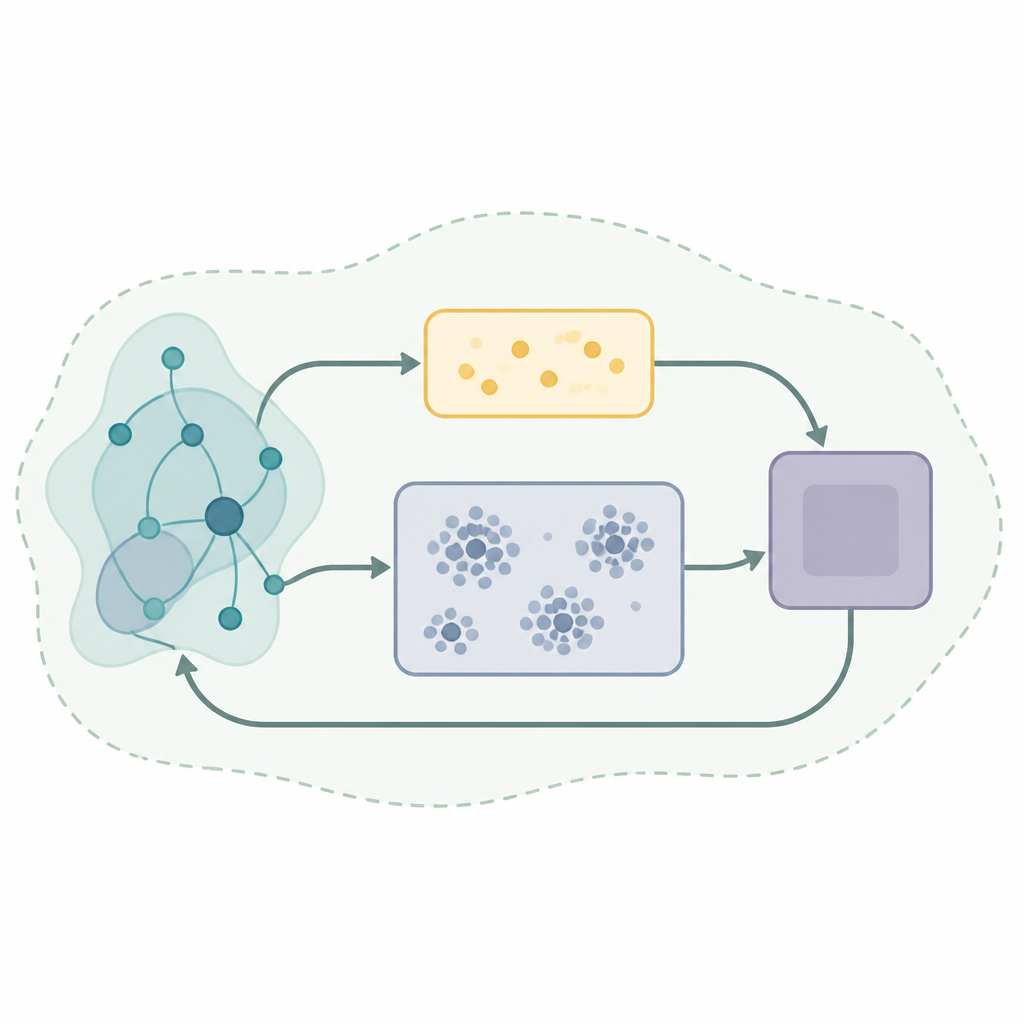
Cómo aprende la memoria de dos búferes
En SODACER, el búfer rápido captura el comportamiento más reciente del sistema y del agente de aprendizaje. Estas muestras frescas llevan información potente sobre la situación actual, por lo que ayudan al agente a ajustarse con rapidez, aunque sean ruidosas. Con el tiempo, experiencias seleccionadas pasan al búfer lento, donde un mecanismo de agrupación autoorganizado reúne situaciones similares. Cuando dos clústeres se solapan fuertemente, se fusionan, y los clústeres que se vuelven demasiado estrechos o poco informativos se eliminan. Esto mantiene el búfer lento compacto pero rico, ofreciendo una visión amplia de cómo se comporta el sistema bajo distintas condiciones. El algoritmo de aprendizaje extrae de ambos búferes, equilibrando la flexibilidad a corto plazo con la estabilidad a largo plazo y reduciendo la habitual tensión entre sesgo y varianza en el aprendizaje estadístico.
Mantener el aprendizaje dentro de límites seguros
Más allá de aprender estrategias de control de alta calidad, el marco debe garantizar que el sistema nunca viole los límites de seguridad. Para lograrlo, los autores combinan SODACER con una capa de seguridad basada en funciones barrera de control. En términos sencillos, la política de aprendizaje por refuerzo propone una acción de control y un filtro de seguridad comprueba si esa acción podría empujar al sistema fuera de una región segura predefinida. Si es necesario, el filtro ajusta la acción de la forma mínima para que se mantengan satisfechas todas las condiciones de seguridad. Este diseño permite que el agente de aprendizaje se concentre en mejorar el rendimiento, como reducir la carga de enfermedad o el coste, mientras las funciones barrera hacen cumplir la seguridad en cada paso.
Probar el método en el control del VPH
Para demostrar el enfoque, los investigadores aplican SODACER a un modelo detallado de transmisión del VPH que incluye tanto hombres como mujeres, vacunación, cribado y límites presupuestarios. El objetivo es reducir infecciones y costes asociados a lo largo del tiempo respetando restricciones realistas sobre las tasas de vacunación y cribado. Comparan su método con otras dos estrategias de repetición: repetición aleatoria simple y una repetición estándar basada en agrupación. En cinco escenarios de intervención distintos y 200 simulaciones repetidas, SODACER emparejado con un optimizador eficiente llamado Sophia converge más rápido, utiliza menos muestras y alcanza un coste final menor. También muestra una menor variabilidad entre ejecuciones, lo que indica un aprendizaje más fiable y, gracias a la capa de seguridad, mantiene una tasa cero de violaciones de las restricciones en todos los casos probados. 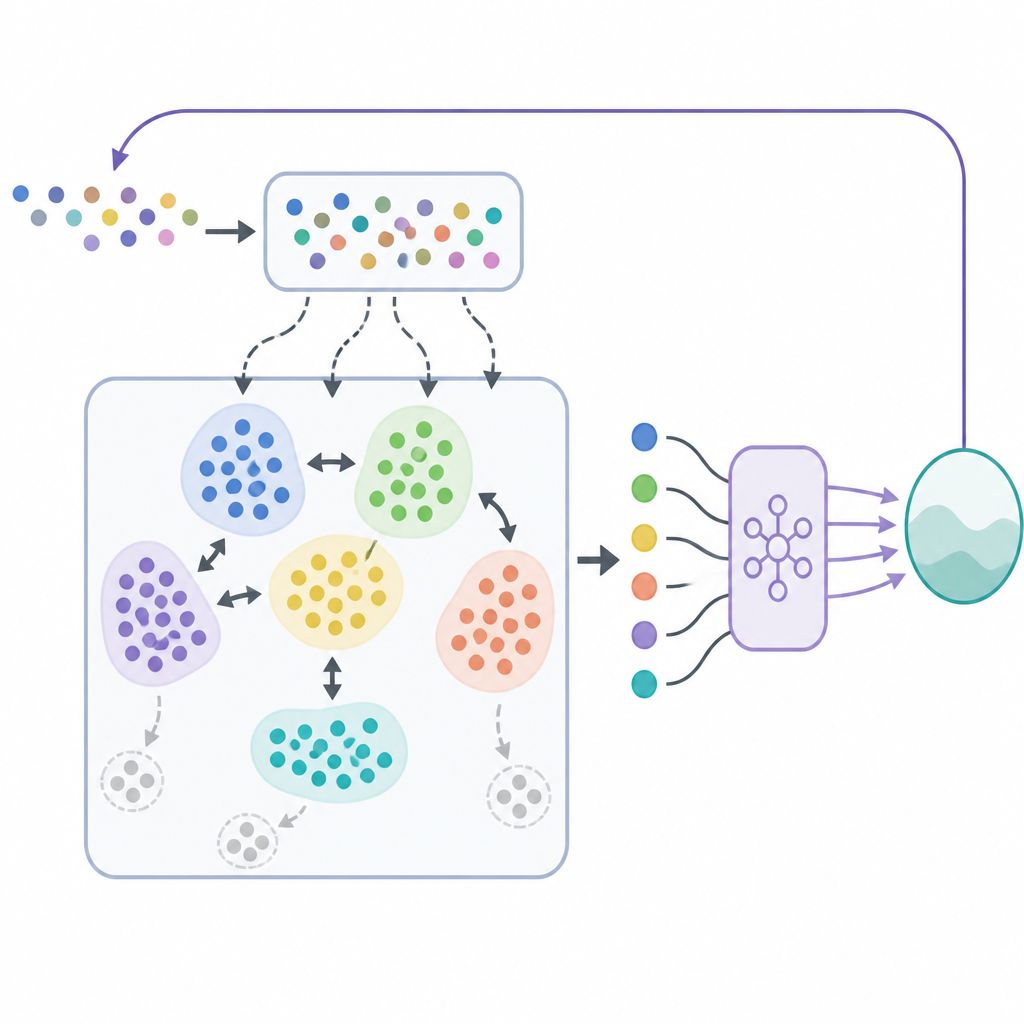
Qué significa esto para el control en el mundo real
En términos sencillos, este trabajo muestra cómo dotar a un algoritmo de aprendizaje de una memoria más inteligente y un escudo de seguridad permanente puede producir estrategias de control efectivas y confiables. En lugar de explorar a ciegas, el sistema recuerda selectivamente las experiencias más informativas y comprueba cada acción propuesta frente a límites de seguridad claros. Aunque el estudio de caso se centra en el VPH, las ideas detrás de SODACER y su integración de seguridad son generales, y apuntan hacia un control basado en aprendizaje más seguro y eficiente en ámbitos tan diversos como la robótica, la sanidad y los grandes sistemas de infraestructura.
Cita: Khalili-Amirabadi, R., Jalaeian-Farimani, M. & Solaymani-Fard, O. Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay (SODACER) for safe reinforcement learning in optimal control. Sci Rep 16, 14960 (2026). https://doi.org/10.1038/s41598-026-44517-1
Palabras clave: aprendizaje por refuerzo seguro, repetición de experiencias, memoria de doble búfer, control del VPH, control óptimo