Clear Sky Science · pl
Samouczące się adaptacyjne odtwarzanie doświadczeń z podwójnym buforem (SODACER) do bezpiecznego uczenia ze wzmocnieniem w sterowaniu optymalnym
Nauczanie maszyn bez narażania bezpieczeństwa
Gdy komputery uczą się sterować systemami rzeczywistymi, takimi jak leczenie medyczne czy roboty, musimy sprawić, by poprawiały się szybko, nie narażając przy tym ludzi. W artykule zaproponowano nowy sposób, w jaki algorytmy uczące się mogą ćwiczyć na przeszłych doświadczeniach, aby stać się zarówno szybsze, jak i bezpieczniejsze, oraz pokazano, jak może on pomóc w projektowaniu lepszych strategii ograniczania rozprzestrzeniania się i kosztów wirusa brodawczaka ludzkiego (HPV).
Dlaczego kontrolowanie złożonych systemów jest trudne
Nowoczesne technologie często obejmują systemy zmieniające się ciągle w czasie — od rozprzestrzeniania się chorób po ruch robota. Inżynierowie chcą kierować tymi systemami ku stanom zdrowym lub efektywnym, jednocześnie przestrzegając surowych ograniczeń, takich jak zasady bezpieczeństwa czy limity zasobów. Tradycyjne metody sterowania zawodzą, gdy system jest bardzo złożony, niepewny lub ulega zmianom. Uczenie ze wzmocnieniem, w którym sztuczny agent uczy się metodą prób i błędów, wydaje się obiecujące, ale musi być zaprojektowane tak, by sam proces uczenia nie wszedł na teren niebezpieczny.
Uczenie z pamięci bez zapominania o bezpieczeństwie
Kluczowym składnikiem wielu skutecznych systemów uczących się jest rodzaj pamięci zwany odtwarzaniem doświadczeń, gdzie algorytm przechowuje przeszłe interakcje i ponownie z nich korzysta, by ulepszać decyzje. Podstawowe strategie odtwarzania losowo wybierają próbki z tej pamięci, co bywa nieekonomiczne i niestabilne, gdy świat się zmienia. Autorzy proponują nowy schemat odtwarzania nazwany Samoorganizujące się adaptacyjne odtwarzanie doświadczeń z podwójnym buforem, czyli SODACER. Zamiast jednej dużej, niepodzielonej pamięci, SODACER dzieli ją na szybki bufor dla bardzo świeżych doświadczeń oraz powolny bufor, który organizuje starsze doświadczenia w klastry, automatycznie pruningując zduplikowane przykłady, aby oszczędzać miejsce przy jednoczesnym zachowaniu różnorodności. 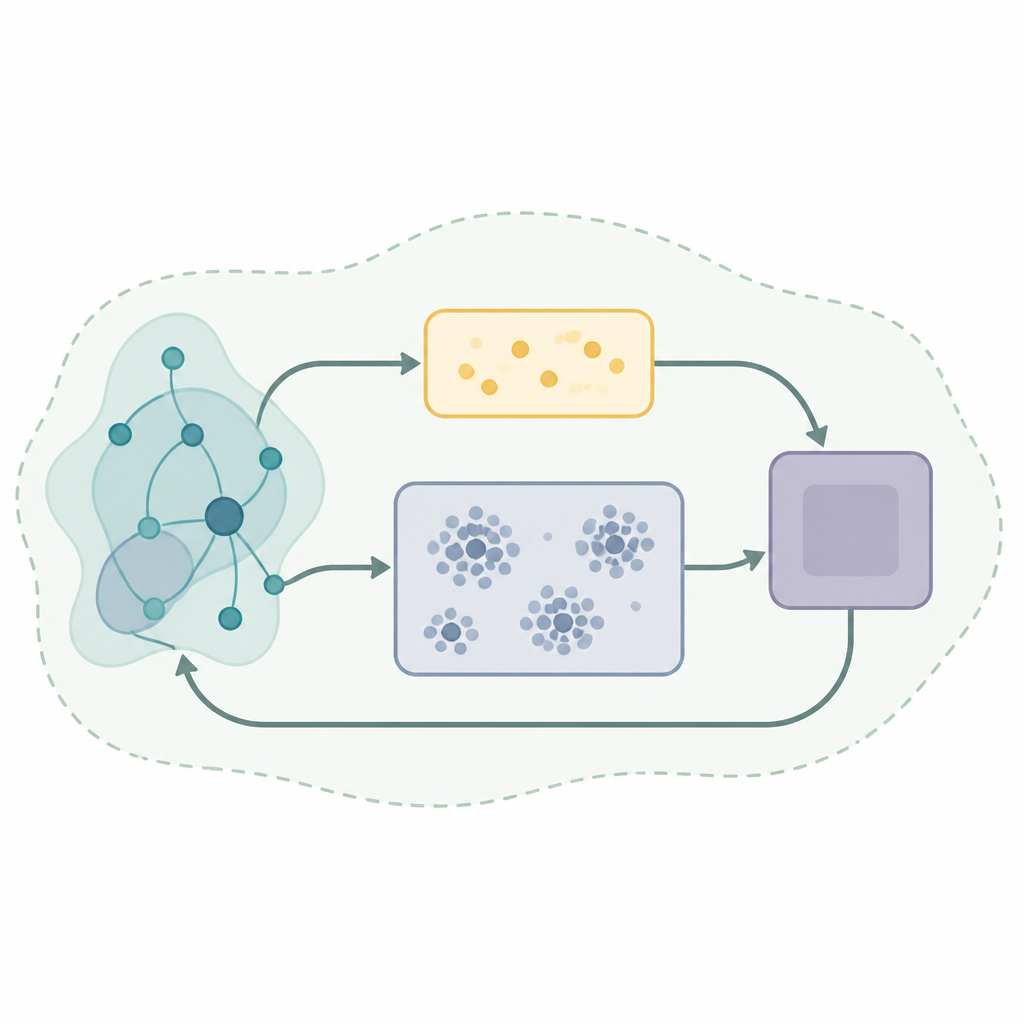
Jak działa pamięć z dwoma buforami
W SODACER szybki bufor rejestruje najnowsze zachowania systemu i agenta uczącego się. Te świeże próbki niosą silną informację o bieżącej sytuacji, pomagając agentowi szybko się dostosować, nawet jeśli są zaszumione. Z biegiem czasu wybrane doświadczenia przechodzą do powolnego bufora, gdzie mechanizm samoorganizującego się grupowania łączy podobne sytuacje. Gdy dwa klastry mocno pokrywają się, są scalane, a klastry stające się zbyt wąskie lub nieinformacyjne są usuwane. Dzięki temu powolny bufor pozostaje zwarty, lecz bogaty, oferując szerokie spojrzenie na zachowanie systemu w różnych warunkach. Algorytm uczenia pobiera próbki z obu buforów, równoważąc krótkoterminową elastyczność z długoterminową stabilnością i redukując typowe napięcie między obciążeniem a wariancją w uczeniu statystycznym.
Utrzymywanie uczenia w bezpiecznych granicach
Ponadto, poza nauką wysokiej jakości strategii sterowania, ramy muszą zapewnić, że system nigdy nie naruszy ograniczeń bezpieczeństwa. Aby to osiągnąć, autorzy łączą SODACER z warstwą bezpieczeństwa opartą na funkcjach bariery sterowania. W uproszczeniu: polityka uczenia proponuje działanie sterujące, a filtr bezpieczeństwa sprawdza, czy działanie to może wypchnąć system poza zdefiniowany region bezpieczny. W razie potrzeby filtr minimalnie koryguje działanie, aby wszystkie warunki bezpieczeństwa pozostały spełnione. Takie rozwiązanie pozwala agentowi skupić się na poprawie wydajności, np. zmniejszaniu obciążenia chorobowego lub kosztów, podczas gdy funkcje bariery egzekwują bezpieczeństwo na każdym kroku.
Testy metody na sterowaniu HPV
Aby zademonstrować podejście, badacze zastosowali SODACER do szczegółowego modelu transmisji HPV uwzględniającego zarówno mężczyzn, jak i kobiety, szczepienia, przesiewy oraz ograniczenia budżetowe. Celem było zmniejszenie zakażeń i związanych z nimi kosztów w czasie, przy jednoczesnym respektowaniu realistycznych ograniczeń dotyczących wskaźników szczepień i badań przesiewowych. Porównali swoją metodę z dwiema innymi strategiami odtwarzania: prostym losowym odtwarzaniem oraz standardowym odtwarzaniem opartym na grupowaniu. W pięciu różnych scenariuszach interwencji i 200 powtórzonych symulacjach SODACER w połączeniu z wydajnym optymalizatorem o nazwie Sophia zbiega szybciej, wykorzystuje mniej próbek i osiąga niższy koszt końcowy. Pokazuje też mniejszą zmienność między przebiegami, co wskazuje na bardziej niezawodne uczenie, a dzięki warstwie bezpieczeństwa utrzymuje zerowy odsetek naruszeń ograniczeń we wszystkich testowanych przypadkach. 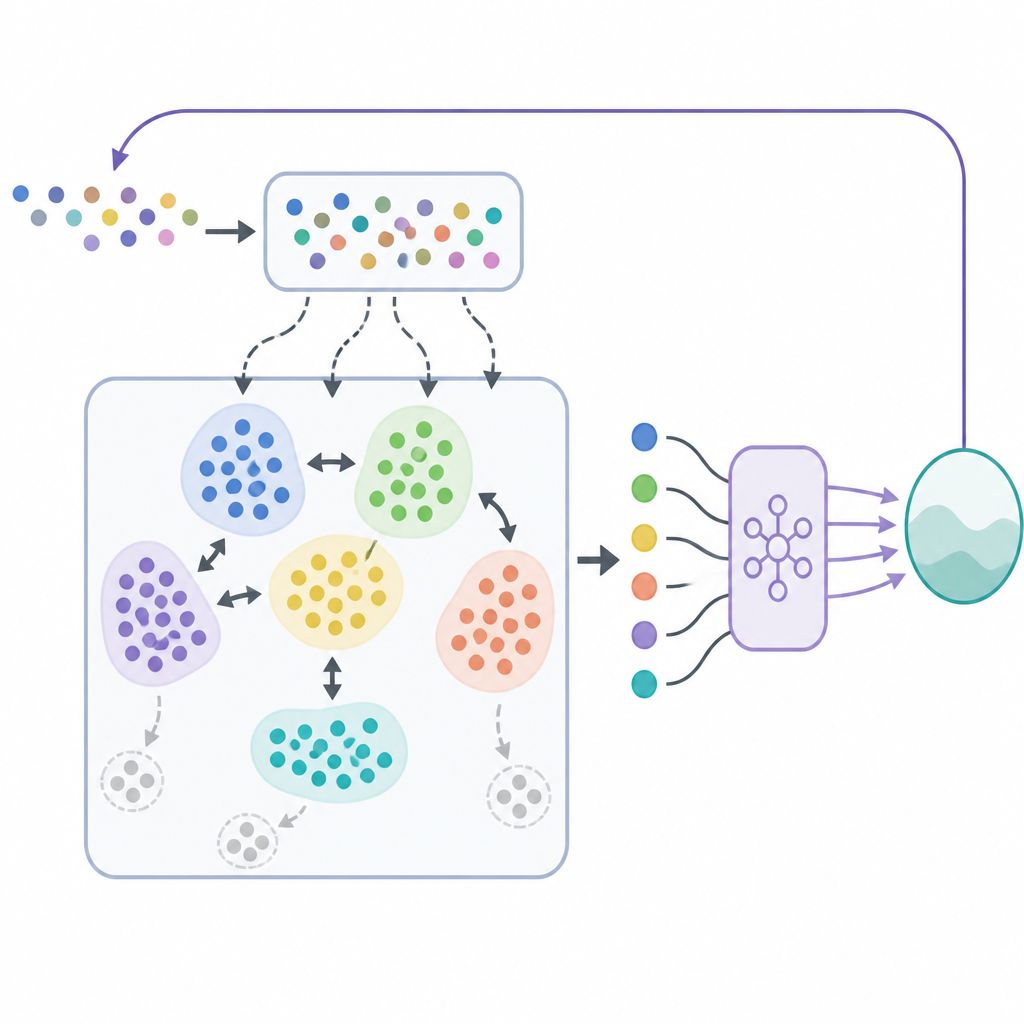
Co to oznacza dla kontroli w świecie rzeczywistym
Mówiąc wprost, praca ta pokazuje, jak inteligentniejsza pamięć dla algorytmu uczącego się oraz stała osłona bezpieczeństwa mogą dać strategie sterowania, które są jednocześnie skuteczne i godne zaufania. Zamiast ślepo eksplorować, system selektywnie zapamiętuje najbardziej informatywne doświadczenia i sprawdza każde proponowane działanie względem jasnych granic bezpieczeństwa. Chociaż studium przypadku koncentruje się na HPV, idee stojące za SODACER i jego integracją bezpieczeństwa są ogólne i wskazują drogę ku bezpieczniejszemu, efektywniejszemu sterowaniu opartemu na uczeniu w takich dziedzinach jak robotyka, opieka zdrowotna czy duże systemy infrastrukturalne.
Cytowanie: Khalili-Amirabadi, R., Jalaeian-Farimani, M. & Solaymani-Fard, O. Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay (SODACER) for safe reinforcement learning in optimal control. Sci Rep 16, 14960 (2026). https://doi.org/10.1038/s41598-026-44517-1
Słowa kluczowe: bezpieczne uczenie ze wzmocnieniem, odtwarzanie doświadczeń, pamięć z podwójnym buforem, kontrola HPV, sterowanie optymalne