Clear Sky Science · zh
基于金字塔视觉变换器的多尺度目标检测模型
为什么微小裂缝很重要
从桥梁和隧道到公寓高楼,许多现代结构由混凝土构成。混凝土中的微小裂缝或隐蔽缺陷可能发展成塌陷、坠落碎片,甚至结构倒塌。检查人员仍然在很大程度上依赖人工视觉,这既慢又昂贵,而且可能漏掉小而危险的缺陷。本文提出了一种新的人工智能(AI)系统,旨在更准确地发现不同尺寸的混凝土缺陷,从而帮助提高建筑和基础设施的安全性。
在多种尺度上识别缺陷
核心难题在于缺陷并不只有一种方便的尺寸。宽大的裂缝对相机和算法来说容易捕捉,但毛细裂缝或一点锈斑可能同样重要却更难检测。经典的目标检测系统,例如早期版本的广泛使用的 YOLO 系列模型,对于较大、轮廓清晰的目标表现良好,但常常在检测小型、重叠或微弱的目标时困难重重。在建筑、制造和医疗等领域,错过一个缺陷可能影响人身安全,风险尤其明显。作者的目标是构建一个能够在单张图像中同时识别大尺度和微小问题的检测器,同时仍保持在现场使用时的可接受速度。 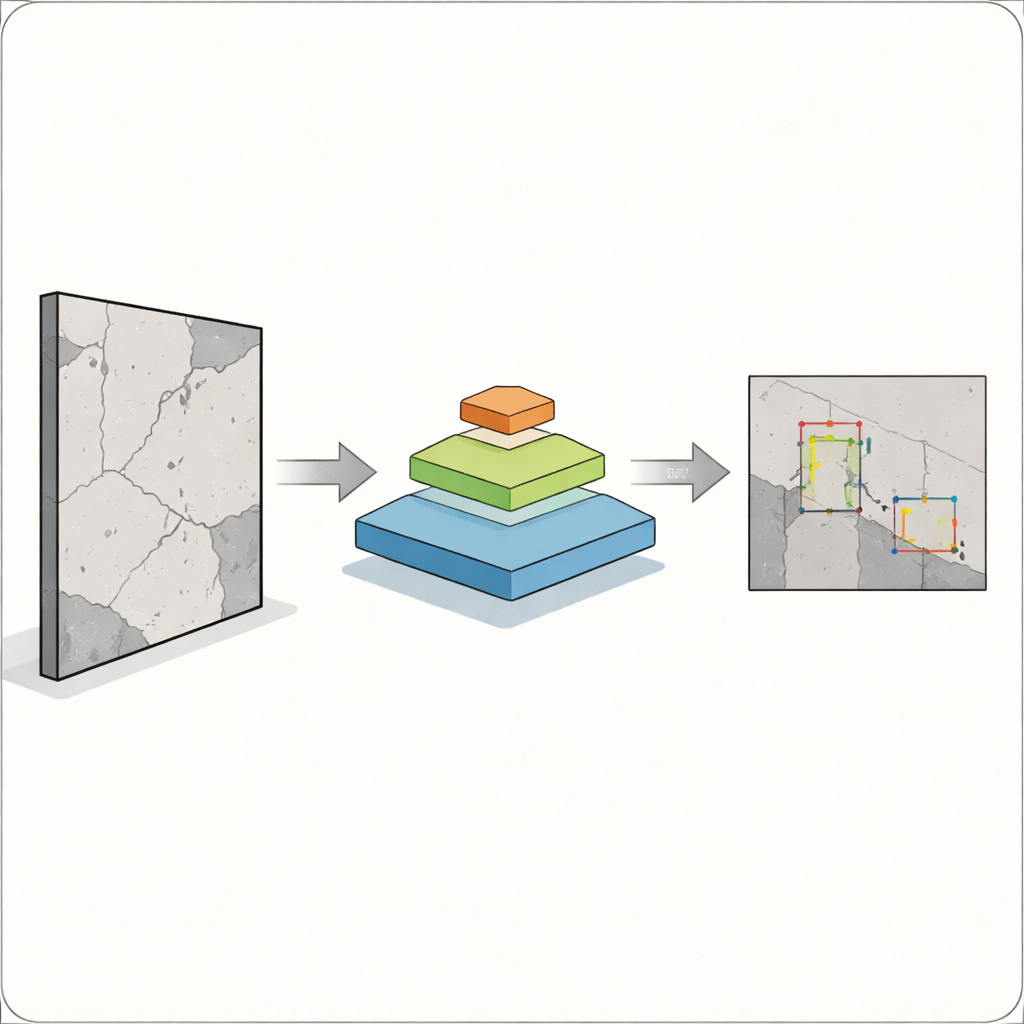
将快速视觉与智能金字塔相结合
为此,研究人员融合了两种强大的思想。他们保留了最新的 YOLOv12“检测头”,该检测头擅长将视觉特征转换为目标的边界框,并用一种金字塔视觉变换器替换其传统骨干网络。该变换器不再只扫描像素的局部邻域,而是通过自注意力机制观察整张图像并学习远距离区域之间的联系。与此同时,它构建了不同分辨率的特征金字塔——从粗略概览到精细细节——从而使微小裂缝和大面积损伤能够在同一表示中并存。这些多尺度特征图随后被送入 YOLOv12,由其判断缺陷的位置和类别。
清理并丰富训练图像
一个聪明的模型需要同样聪明的训练数据。真实世界的混凝土照片往往很混乱,伴有阴影、不均匀光照和粗糙纹理,这些都会掩盖缺陷。作者设计了一个八步预处理流程,从原始图像中提取出清晰的缺陷“掩码”。他们将图像转为灰度、去噪、局部增强对比以揭示微弱裂缝、反转亮度以使缺陷更突出,并使用基于形状的操作连接断裂的裂缝片段并去除非真实损伤的小斑点。最终得到的是每个缺陷的干净轮廓。
创建逼真的合成缺陷
因为危险性缺陷比完好表面少,训练数据存在类别不平衡:否则模型可能学会“无缺陷”是更安全的预测。为了解决这一问题,团队构建了孤立缺陷掩码库,并将这些掩码以随机的位置、角度和尺度粘贴到干净的混凝土背景上。与其简单地剪切粘贴,他们采用平滑融合,使缺陷边缘与新表面自然过渡。这产生了保留真实裂缝、锈蚀、剥落等损伤外观的逼真合成图像,同时大幅增加了模型训练时看到的示例多样性。 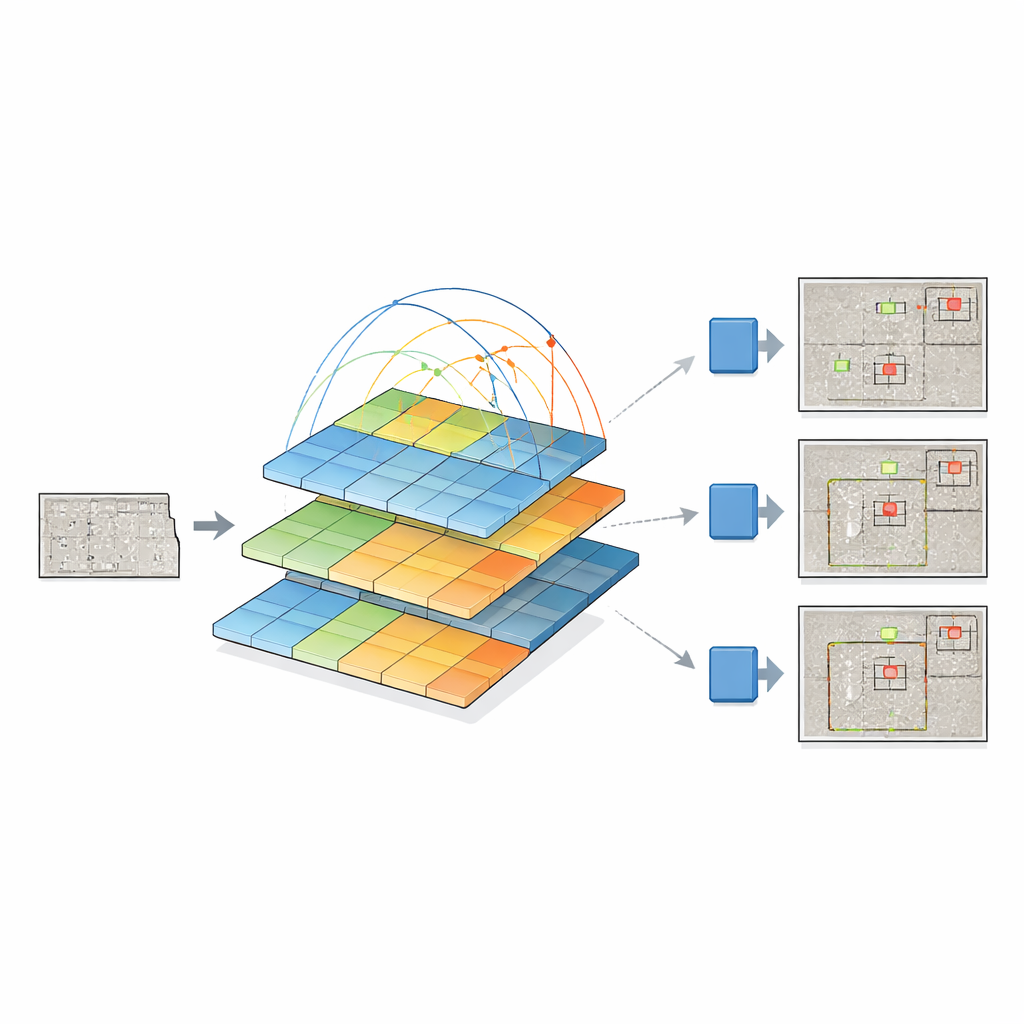
效果如何?
作者将他们的金字塔变换器加 YOLO 系统与多类检测器进行了全面比较,包括较早的 YOLO 版本、像 Faster R-CNN 这样的经典两阶段模型,以及诸如 DETR 和 DINO 的最新基于变换器的设计。他们的模型在小尺度缺陷检测上持续取得改进——这是安全风险最高的部分——在中等和大尺度缺陷上也表现良好。该模型还优于使用另一种变换器(Swin)作为骨干的相关设计,同时使用更少的参数和略低的计算量。尽管变换器骨干使得每次预测比最轻量的 YOLO 变体更慢,但在噪声多变的混凝土纹理上对微妙缺陷的准确性提升是显著的。
通过更精准的数字之眼让结构更安全
从实际意义上看,这项研究表明,将金字塔视觉变换器与像 YOLO 这样的现代检测器配对,可以显著提升 AI 对微小缺陷的识别能力,同时不会让工程师被大量误报淹没。该模型将原始、杂乱的检测照片转化为多尺度、具有全局信息的表示,突出不同尺寸范围内的裂缝、锈蚀和剥落。通过改进的数据准备和合成训练图像,它学会区分真实缺陷与无害的表面花纹。虽然速度与准确性之间仍存在折衷,但这种方法推动了自动化检测更接近可靠的实际应用——为防止我们建成环境中的昂贵且危险的失效提供了更敏锐的数字之眼。
引用: Baek, JW., Suh, D. & Chung, K. Multiscale object detection model based on pyramid vision transformer. Sci Rep 16, 13307 (2026). https://doi.org/10.1038/s41598-026-43522-8
关键词: 混凝土缺陷检测, 金字塔视觉变换器, YOLO 目标检测, 多尺度视觉, 基础设施安全