Clear Sky Science · he
מודל גילוי עצמים ברב-קנה מידה המבוסס על Pyramid Vision Transformer
מדוע סדקים זעירים חשובים
גשרים, מנהרות ומגדלי דירות — מבנים מודרניים רבים בנויים מבטון. סדקים זעירים או פגמים חבויים בבטון עלולים להתפתח לבורות שקיעה, נפילת שברים ואפילו קריסה. בודקים עדיין מסתמכים במידה רבה על הראייה האנושית, שהיא איטית, יקרה ועלולה לפספס ליקויים קטנים אך מסוכנים. מאמר זה מציג מערכת בינה מלאכותית חדשה שתוכננה לזהות פגמים בבטון בגדלים שונים בצורה מדויקת יותר, ובכך לסייע בהגברת הבטיחות של מבנים ותשתיות.
לראות פגמים במגוון גדלים
האתגר המרכזי הוא שהפגמים אינם באים בגודל אחד נוח. סדק רחב קל לזיהוי על ידי מצלמות ואלגוריתמים, אך סדק קו דק או כתם חלודה יכולים להיות חשובים באותו המידה וקשה בהרבה לזהותם. מערכות זיהוי עצמים קלאסיות, כמו גרסאות מוקדמות של משפחת המודלים המפורסמת YOLO, עובדות היטב עבור עצמים גדולים ומוגדרים היטב אך מתקשות לעתים עם עצמים קטנים, חופפים או בלתי ברורים. זה מסוכן במיוחד בבנייה, ייצור ובריאות, שבהם טעות בזיהוי עלולה לסכן אנשים. המחברים מבקשים לבנות_detector_ שיכול לראות גם בעיות גדולות וגם זעירות בתוך תמונה אחת, מבלי להפוך לאיטי מדי לשימוש בשטח. 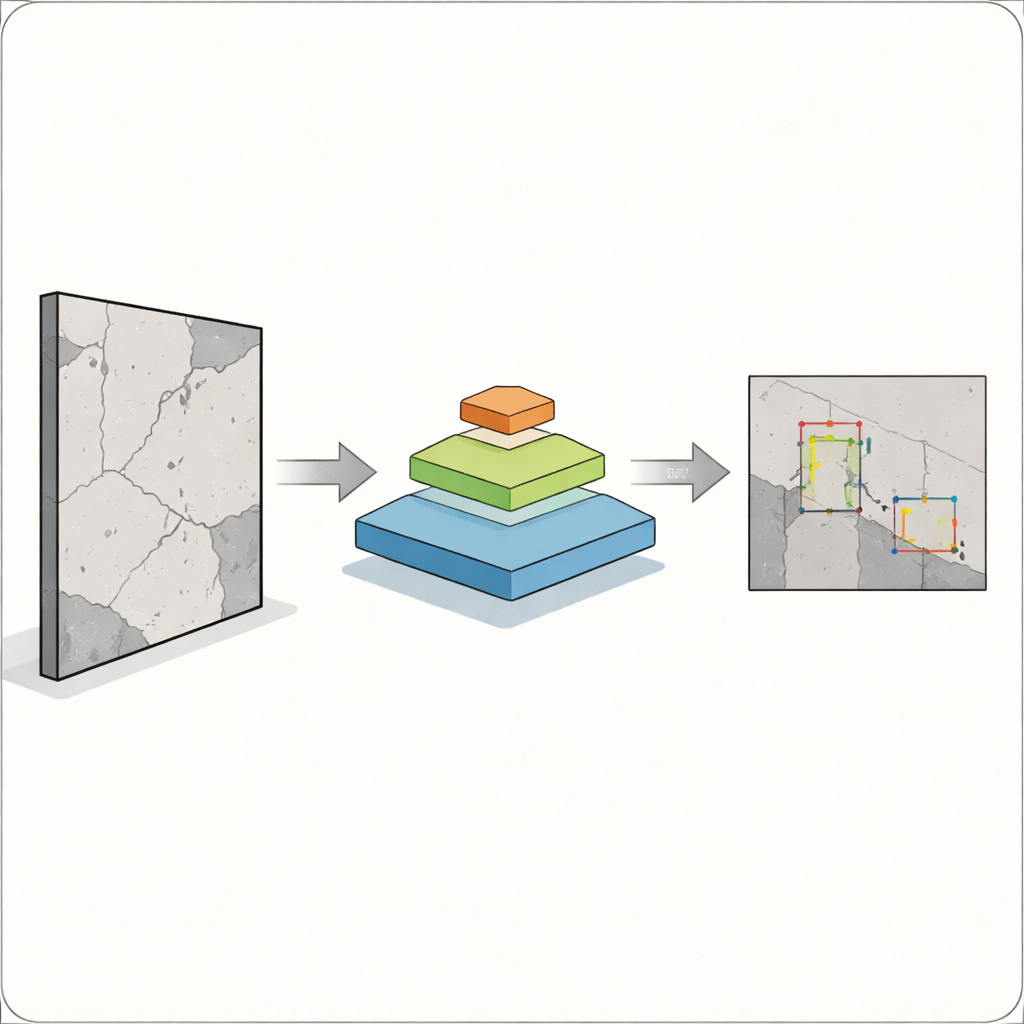
שילוב חזון מהיר עם פירמידה חכמה
לשם כך, החוקרים מאחדים שתי רעיונות עוצמתיים. הם שומרים על "ראש הגילוי" של YOLOv12 העדכנית, שהוא טוב בהפיכת תכונות חזותיות לתיבות מקיפות עצמים, ומחליפים את ה-backbone המסורתי ב-Pyramid Vision Transformer. במקום לסרוק רק שכנות קטנות של פיקסלים, הטרנספורמר הזה בוחן את התמונה כולה ולומד כיצד אזורים מרוחקים קשורים זה לזה באמצעות תהליך הקרוי self-attention. במקביל הוא בונה פירמידת מפות תכונה ברזולוציות שונות — מתצוגות גסות ועד לפרטים דקים — כך שסדקים זעירים וכתמי נזק גדולים יוכלו להיות מיוצגים יחד. מפות התכונה הרב-קנה-מידתיות הללו מוזנות לאחר מכן ל-YOLOv12, שמחליט היכן ומהם הפגמים.
ניקוי והעשרת תמונות האימון
מודל חכם צריך נתוני אימון המחוכמים באותו מידה. תמונות בטון מעולם המציאות הן מבולגנות, עם צללים, תאורה לא אחידה ומרקמים מחוספסים שעלולים להסתיר ליקויים. המחברים מפתחים צינור עיבוד מקדים בן שמונה שלבים כדי להביא למיסוך ברור של הפגמים מתוך התמונות הגולמיות. הם ממירים תמונות לאפור-לבן, מסירים רעש, מחלישרים באופן מקומי קונטרסט כדי לגלות סדקים חלשים, מהפכים בהירות כך שהפגמים בולטים, ומשתמשים בפעולות מבוססות צורה כדי לחבר קטעי סדק מפוצלים ולהסיר כתמים זעירים שאינם נזק אמיתי. התוצאה היא מתאר נקי של כל פגם.
יצירת פגמים סינתטיים ריאליסטיים
מכיוון שמפגמים מסוכנים נדירים יותר מפני שטחים שלמים, נתוני האימון אינם מאוזנים: אחרת המודל עלול ללמוד ש"אין פגם" היא האפשרות הבטוחה. כדי לתקן זאת, הצוות בונה ספריית מסכות פגם מבודדות ומדביק אותן על רקעים נקיים של בטון בעמדות, זוויות וגדלים אקראיים רבים. במקום פשוט לחתוך ולהדביק, הם משתמשים במיזוג חלק כך שגבולות הפגם משתלבים באופן טבעי עם המשטח החדש. זה מייצר תמונות סינתטיות ריאליסטיות שמשמרות את המראה של סדקים, חלודה, יבלות והצטלקויות אחרות, תוך הגדלה ניכרת של המגוון בדוגמאות שהמודל רואה במהלך האימון. 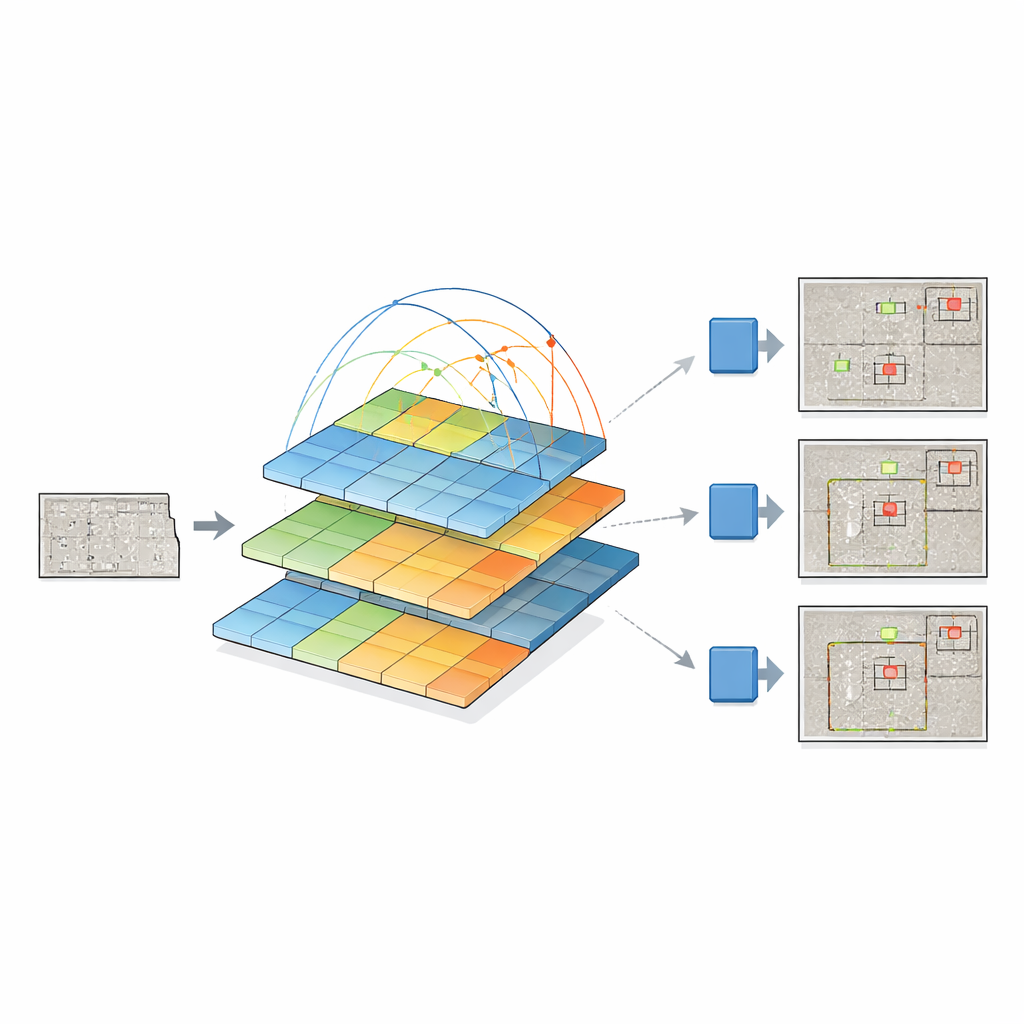
כמה טוב זה עובד?
המחברים משווים באופן יסודי את מערכת ה-pyramid-transformer-plus-YOLO שלהם עם כמה משפחות של גלאים, כולל גרסאות YOLO ישנות יותר, מודלים קלאסיים דו-שלביים כמו Faster R-CNN, ועיצובים מבוססי טרנספורמר עכשוויים כגון DETR ו-DINO. המודל שלהם משפר בעקביות את גילוי הפגמים הקטנים, שם עומדות ההימורים הגבוהים ביותר מבחינת בטיחות, ומתחרה היטב בגילוי פגמים בינוניים וגדולים. הוא גם עולה על עיצוב קרוב המשתמש בטרנספורמר שונה (Swin) כ-backbone, תוך שימוש בפחות פרמטרים וקצת פחות חישוב. אף על פי ש-backbone הטרנספורמר הופך כל חיזוי לאיטי יותר מאשר הגרסאות הקלות ביותר של YOLO, העלייה בדיוק — במיוחד בפגמים עדינים במרקמי בטון רעשניים — משמעותית.
מבנים בטוחים יותר בעיניים דיגיטליות חדות יותר
ברמה הפרקטית, מחקר זה מראה ששילוב Pyramid Vision Transformer עם גלאי מודרני כמו YOLO יכול לשפר משמעותית את היכולת של בינה מלאכותית לזהות ליקויים זעירים בלי להציף את המהנדסים באיתותי שווא. המודל הופך תמונות בדיקה גולמיות ומבולגנות לייצוגים רב-קנה-מידתיים ומאוחסנים עולמית שמדגישים סדקים, חלודה והצטלקויות במגוון גדלים. עם שיפור בהכנת הנתונים ותמונות אימון סינתטיות, הוא לומד להבחין בין פגמים אמיתיים לתבניות משטח בלתי מזיקות. למרות שעדיין מתקיים פיצוי בין מהירות לדיוק, הגישה מקרבת את הבדיקה האוטומטית לשימוש אמין במציאות — ומציעה סט חד יותר של עיניים דיגיטליות שיסייעו למנוע כשלים יקרים ומסוכנים בסביבה הבנויה שלנו.
ציטוט: Baek, JW., Suh, D. & Chung, K. Multiscale object detection model based on pyramid vision transformer. Sci Rep 16, 13307 (2026). https://doi.org/10.1038/s41598-026-43522-8
מילות מפתח: זיהוי פגמים בבטון, pyramid vision transformer, זיהוי עצמים YOLO, חזון רב-קנה מידה, בטיחות תשתיות