Clear Sky Science · sv
Multiskaligt objektdetekteringsmodell baserad på pyramid-vision-transformer
Varför små sprickor spelar roll
Från broar och tunnlar till bostadshus är många moderna konstruktioner gjorda av betong. Små sprickor eller dolda defekter i betongen kan växa till håligheter, fallande skräp eller till och med kollaps. Inspektörer förlitar sig fortfarande i hög grad på mänsklig syn, vilket är långsamt, kostsamt och kan missa små men farliga fel. Denna artikel presenterar ett nytt artificiellt intelligens (AI)-system utformat för att upptäcka betongdefekter i många olika storlekar mer exakt, vilket bidrar till att göra byggnader och infrastruktur säkrare.
Upptäcka defekter i många skalor
Den centrala utmaningen är att defekter inte kommer i en bekväm, enhetlig storlek. En bred spricka är lätt för kameror och algoritmer att fånga, men en hårfin spricka eller en rostfläck kan vara lika viktig och mycket svårare att upptäcka. Klassiska objektdetekteringssystem, såsom tidigare versioner av den väl använda YOLO-familjen, fungerar väl för större, välavgränsade objekt men har ofta svårt med små, överlappande eller svaga objekt. Det är särskilt riskabelt inom bygg, tillverkning och sjukvård, där ett missat fel kan påverka människors säkerhet. Författarna vill bygga en detektor som kan se både stora och små problem i samma bild, utan att bli för långsam för användning på fältet. 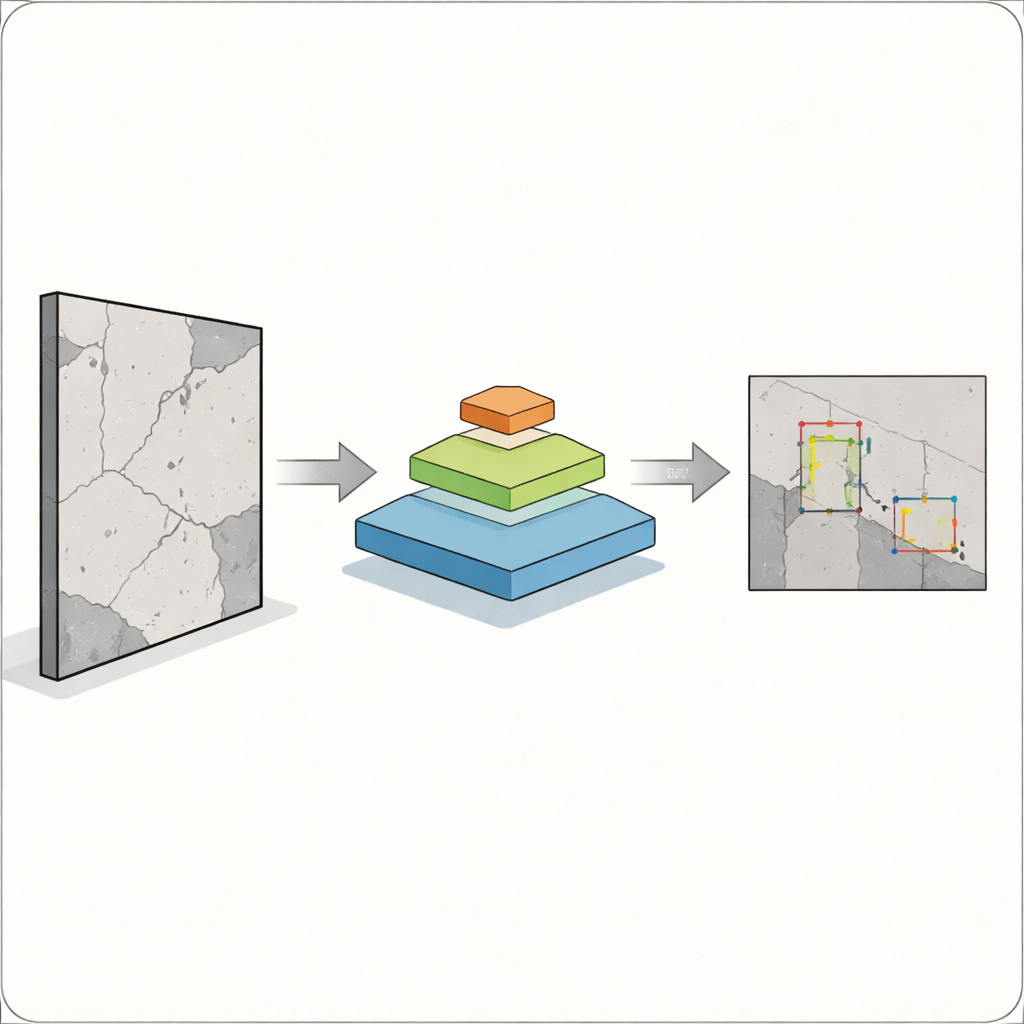
Kombinera snabb vision med en smart pyramid
För att göra detta förenar forskarna två kraftfulla idéer. De behåller den senaste YOLOv12 “detection head”, som är bra på att omvandla visuella kännetecken till avgränsningsrutor runt objekt, och ersätter dess traditionella backbone med en pyramid vision transformer. Istället för att bara undersöka små pixelgrannskap ser denna transformer hela bilden och lär sig hur avlägsna områden relaterar till varandra genom en process som kallas self-attention. Samtidigt bygger den en pyramid av feature-maps i olika upplösningar — från grova översikter till fina detaljer — så att små sprickor och stora skador kan representeras tillsammans. Dessa multiskaliga feature-maps matas sedan in i YOLOv12, som avgör var defekterna finns och vad de är.
Rensa och berika träningsbilderna
En smart modell behöver lika smarta träningsdata. Verkliga foton av betong är röriga, med skuggor, ojämnt ljus och grov textur som kan dölja fel. Författarna utformar en åttastegs förbehandlingspipeline för att karva ut tydliga ”masker” av defekter från råa bilder. De konverterar bilder till gråskala, tar bort brus, förbättrar kontrasten lokalt för att avslöja svaga sprickor, inverterar ljusstyrkan så att defekter framträder, och använder formbaserade operationer för att sammanfoga brutna sprickfragment och ta bort små fläckar som inte är verkliga skador. Resultatet är en ren kontur av varje defekt.
Skapa realistiska syntetiska defekter
Eftersom farliga defekter är mer sällsynta än intakta ytor är träningsdata obalanserade: modellen kan annars lära sig att ”ingen defekt” är det säkra valet. För att åtgärda detta bygger teamet ett bibliotek av isolerade defektmasker och klistrar in dem på rena betongbakgrunder i många slumpmässiga positioner, vinklar och storlekar. Istället för att bara klippa och klistra använder de mjuk blandning så att defektens kanter smälter naturligt med den nya ytan. Detta producerar realistiska syntetiska bilder som bevarar utseendet hos verkliga sprickor, rost, avskalning och andra skadetyper, samtidigt som det kraftigt ökar variationen av exempel som modellen ser under träningen. 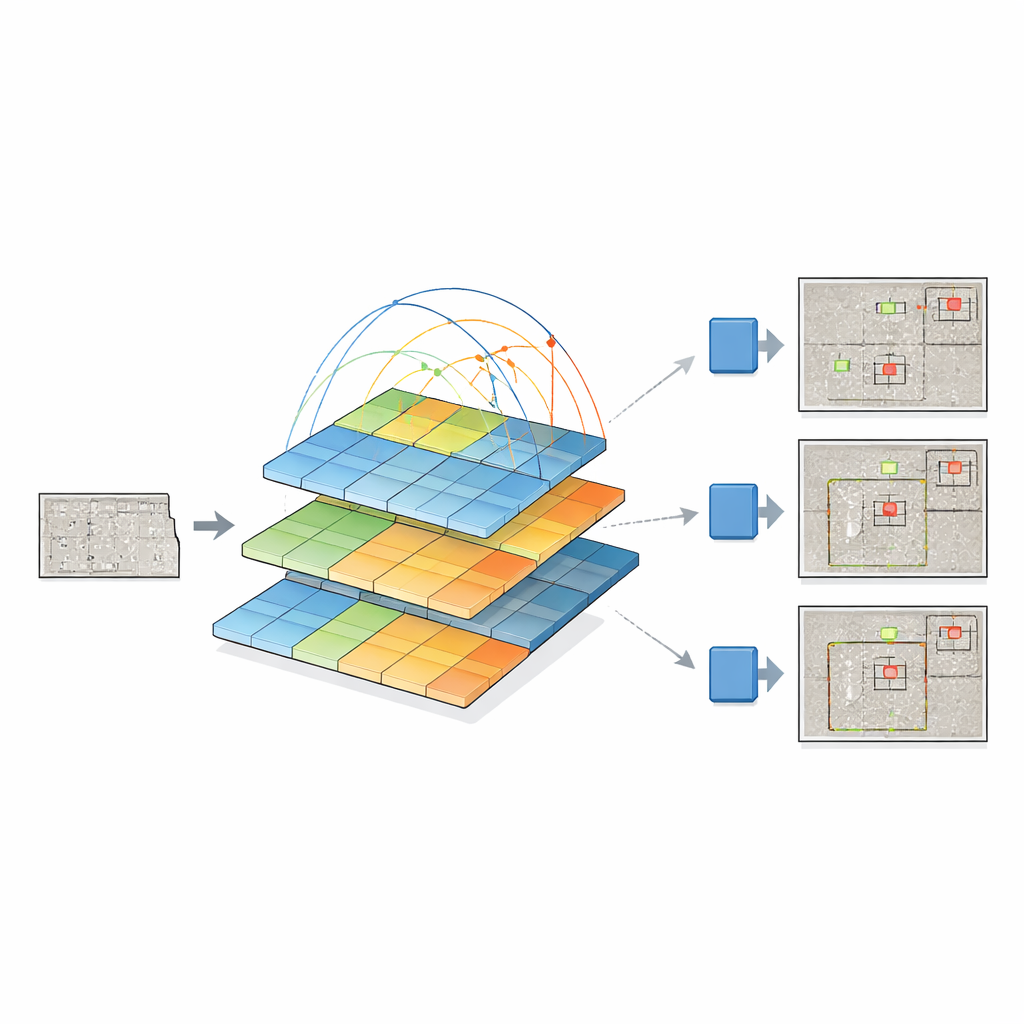
Hur bra fungerar det?
Författarna jämför noggrant sitt pyramid-transformer-plus-YOLO-system med flera familjer av detektorer, inklusive äldre YOLO-versioner, klassiska tvåstegsmodeller som Faster R-CNN och nyare transformerbaserade designer som DETR och DINO. Deras modell förbättrar konsekvent detekteringen av små defekter, där säkerhetskonsekvenserna är störst, och konkurrerar väl på medelstora och stora defekter. Den överträffar också en närbesläktad design som använder en annan transformer (Swin) som backbone, samtidigt som den använder färre parametrar och något mindre beräkningsresurser. Även om transformer-backbonen gör varje prediktion långsammare än de lättaste YOLO-varianterna är förbättringen i noggrannhet — särskilt på subtila defekter i brusiga betongtexturer — betydande.
Säkrare konstruktioner genom skarpare digitala ögon
I praktiska termer visar denna forskning att parning av en pyramid vision transformer med en modern detektor som YOLO kan göra AI mycket bättre på att upptäcka små fel utan att dränka ingenjörer i falska larm. Modellen förvandlar råa, röriga inspektionsfoton till multiskaliga, globalt informerade representationer som lyfter fram sprickor, rost och avskalning i olika storlekar. Med förbättrad datapreparation och syntetiska träningsbilder lär den sig skilja verkliga defekter från ofarliga ytstrukturer. Även om det fortfarande finns en avvägning mellan hastighet och noggrannhet förflyttar detta angreppssätt automatisk inspektion närmare tillförlitlig användning i verkliga miljöer — och erbjuder ett skarpare digitalt öga för att hjälpa till att förhindra kostsamma och farliga fel i vår byggda miljö.
Citering: Baek, JW., Suh, D. & Chung, K. Multiscale object detection model based on pyramid vision transformer. Sci Rep 16, 13307 (2026). https://doi.org/10.1038/s41598-026-43522-8
Nyckelord: betongfelavkänning, pyramid vision transformer, YOLO objektdetektering, multiskalig vision, infrastrukturens säkerhet