Clear Sky Science · pt
Modelo de detecção de objetos multiescala baseado em transformer de visão em pirâmide
Por que fissuras minúsculas importam
De pontes e túneis a torres residenciais, muitas estruturas modernas são feitas de concreto. Fissuras minúsculas ou defeitos ocultos nesse concreto podem crescer e provocar crateras, queda de detritos ou até colapso. Inspetores ainda dependem muito do olhar humano, que é lento, caro e pode deixar passar falhas pequenas, porém perigosas. Este artigo apresenta um novo sistema de inteligência artificial (IA) projetado para identificar defeitos no concreto em várias escalas com maior precisão, ajudando a manter edifícios e infraestruturas mais seguros.
Ver defeitos em diferentes escalas
O desafio central é que os defeitos não têm um tamanho único conveniente. Uma fissura larga é fácil de captar por câmeras e algoritmos, mas uma ranhura fina ou uma pintinha de ferrugem pode ser igualmente importante e muito mais difícil de detectar. Sistemas clássicos de detecção de objetos, como versões anteriores da família YOLO amplamente utilizada, funcionam bem para objetos maiores e bem definidos, mas frequentemente têm dificuldades com objetos pequenos, sobrepostos ou tênues. Isso é especialmente arriscado em construção, manufatura e saúde, onde um defeito não detectado pode afetar a segurança humana. Os autores buscam construir um detector capaz de enxergar problemas grandes e minúsculos em uma única imagem, sem ficar lento demais para uso em campo. 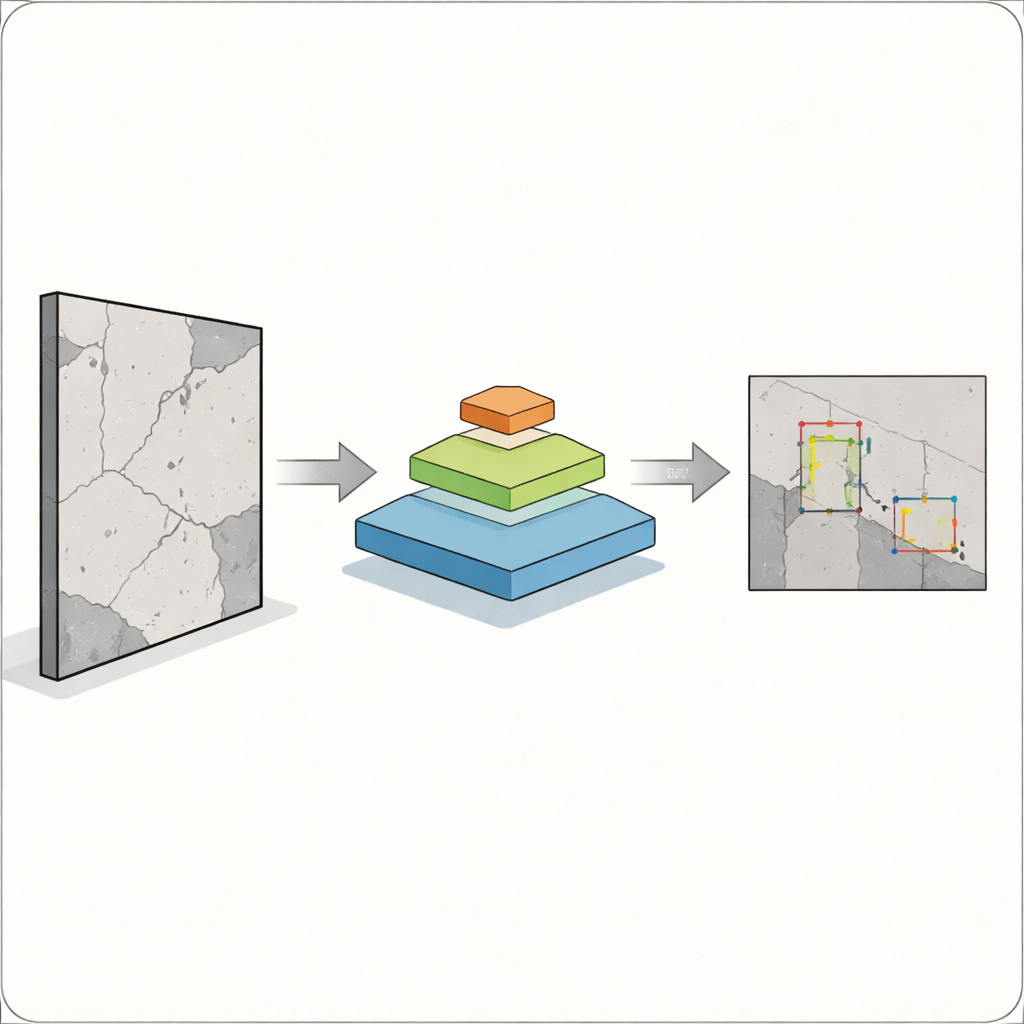
Combinando visão rápida com uma pirâmide inteligente
Para isso, os pesquisadores fundem duas ideias poderosas. Eles mantêm o mais recente “detection head” do YOLOv12, que é bom em transformar características visuais em caixas delimitadoras ao redor dos objetos, e substituem sua espinha dorsal tradicional por um transformer de visão em pirâmide. Em vez de varrer apenas pequenos vizinhanças de pixels, esse transformer observa a imagem inteira e aprende como regiões distantes se relacionam por meio de um processo chamado self-attention. Ao mesmo tempo, ele constrói uma pirâmide de mapas de características em diferentes resoluções — de visões gerais grosseiras a detalhes finos — de modo que fissuras pequenas e grandes áreas danificadas possam ser representadas conjuntamente. Esses mapas multiescala são então alimentados ao YOLOv12, que decide onde e o que são os defeitos.
Limpeza e enriquecimento das imagens de treinamento
Um modelo inteligente precisa de dados de treinamento igualmente inteligentes. Fotos reais de concreto são bagunçadas, com sombras, iluminação desigual e texturas ásperas que podem esconder falhas. Os autores projetam um pipeline de pré-processamento em oito etapas para esculpir “máscaras” nítidas de defeitos a partir das imagens brutas. Eles convertem as imagens para tons de cinza, removem ruído, realçam localmente o contraste para revelar fissuras tênues, invertem o brilho para que os defeitos sobressaiam e usam operações baseadas em forma para conectar fragmentos de fissuras quebradas e eliminar pequenas manchas que não são danos reais. O resultado é o contorno limpo de cada defeito.
Criando defeitos sintéticos realistas
Como defeitos perigosos são mais raros que superfícies intactas, os dados de treinamento ficam desbalanceados: o modelo poderia aprender que “sem defeito” é a opção segura. Para corrigir isso, a equipe constrói uma biblioteca de máscaras de defeitos isoladas e as cola sobre fundos limpos de concreto em muitas posições, ângulos e tamanhos aleatórios. Em vez de simplesmente recortar e colar, eles usam blendagem suave para que as bordas do defeito se integrem naturalmente à nova superfície. Isso produz imagens sintéticas realistas que preservam a aparência de fissuras reais, ferrugem, desagregação e outros tipos de dano, ao mesmo tempo em que aumentam muito a variedade de exemplos que o modelo vê durante o treinamento. 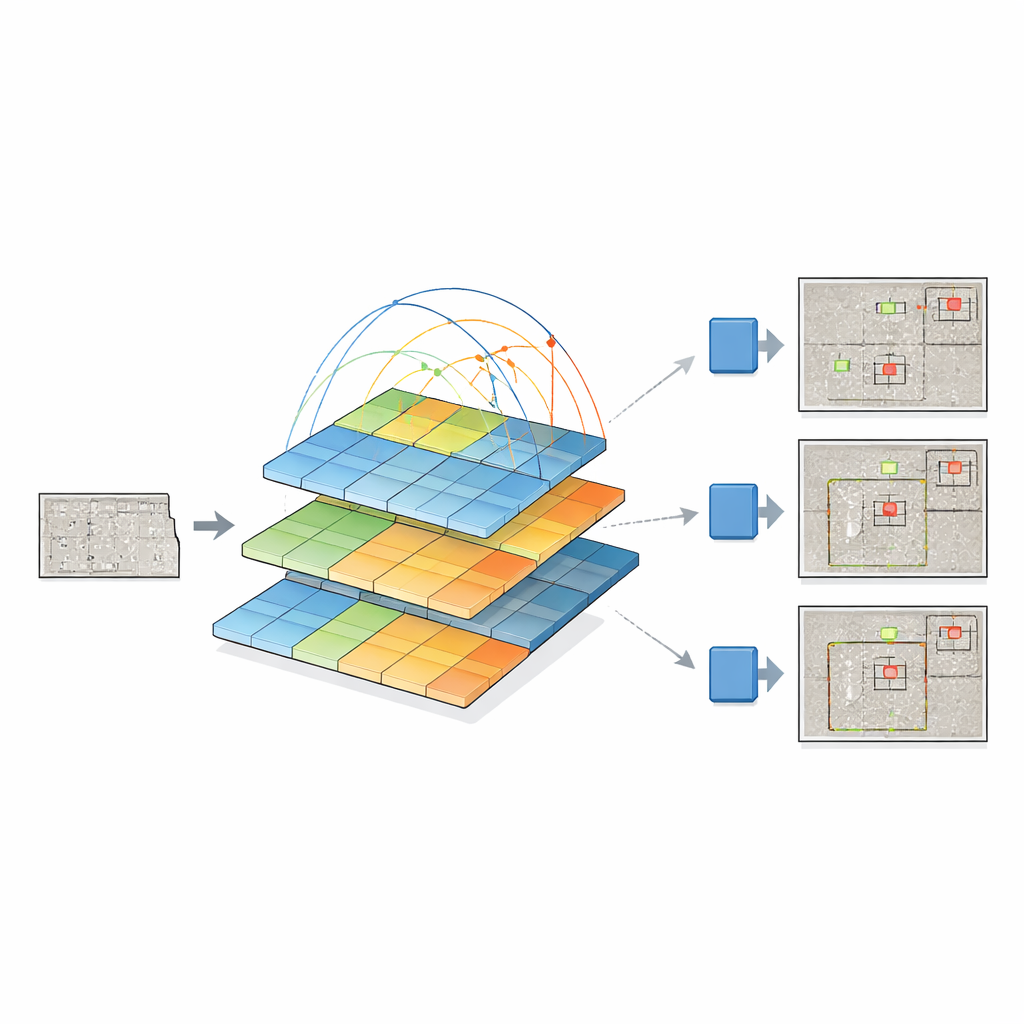
Qual o desempenho?
Os autores comparam exaustivamente seu sistema que combina transformer em pirâmide com YOLO a várias famílias de detectores, incluindo versões antigas do YOLO, modelos clássicos em duas etapas como o Faster R-CNN e projetos recentes baseados em transformer como DETR e DINO. Seu modelo melhora consistentemente a detecção de pequenos defeitos, onde os riscos para a segurança são maiores, e disputa bem em defeitos médios e grandes. Ele também supera um projeto relacionado que usa um transformer diferente (Swin) como backbone, usando menos parâmetros e ligeiramente menos computação. Embora a espinha dorsal baseada em transformer torne cada predição mais lenta que as variantes YOLO mais leves, o ganho em precisão — especialmente em defeitos sutis sobre texturas de concreto ruidosas — é substancial.
Estruturas mais seguras por olhos digitais mais aguçados
Em termos práticos, esta pesquisa mostra que combinar um transformer de visão em pirâmide com um detector moderno como o YOLO pode tornar a IA muito melhor em detectar falhas minúsculas sem sobrecarregar engenheiros com falsos positivos. O modelo transforma fotos de inspeção brutas e desordenadas em representações multiescala e globalmente informadas que destacam fissuras, ferrugem e desagregação em várias dimensões. Com preparação de dados aprimorada e imagens sintéticas no treinamento, ele aprende a diferenciar defeitos reais de padrões superficiais inofensivos. Ainda há um compromisso entre velocidade e precisão, mas essa abordagem aproxima a inspeção automatizada de um uso real e confiável — oferecendo um par de olhos digitais mais nítidos para ajudar a prevenir falhas dispendiosas e perigosas no ambiente construído.
Citação: Baek, JW., Suh, D. & Chung, K. Multiscale object detection model based on pyramid vision transformer. Sci Rep 16, 13307 (2026). https://doi.org/10.1038/s41598-026-43522-8
Palavras-chave: detecção de defeitos em concreto, transformer de visão em pirâmide, detecção de objetos YOLO, visão multiescala, segurança de infraestrutura