Clear Sky Science · en
Multiscale object detection model based on pyramid vision transformer
Why tiny cracks matter
From bridges and tunnels to apartment towers, many modern structures are made of concrete. Tiny cracks or hidden defects in that concrete can grow into sinkholes, falling debris, or even collapse. Inspectors still rely heavily on human eyesight, which is slow, costly, and can miss small but dangerous flaws. This paper presents a new artificial intelligence (AI) system designed to spot concrete defects of many different sizes more accurately, helping keep buildings and infrastructure safer.
Seeing defects at many sizes
The core challenge is that defects do not come in one convenient size. A wide crack is easy for cameras and algorithms to catch, but a hairline fracture or a speck of rust can be just as important and far harder to detect. Classic object-detection systems, such as earlier versions of the widely used YOLO family of models, work well for bigger, well-defined objects but often struggle with small, overlapping, or faint ones. This is especially risky in construction, manufacturing, and healthcare, where a missed flaw can affect human safety. The authors aim to build a detector that can see both large and tiny problems within a single image, without becoming too slow for use in the field. 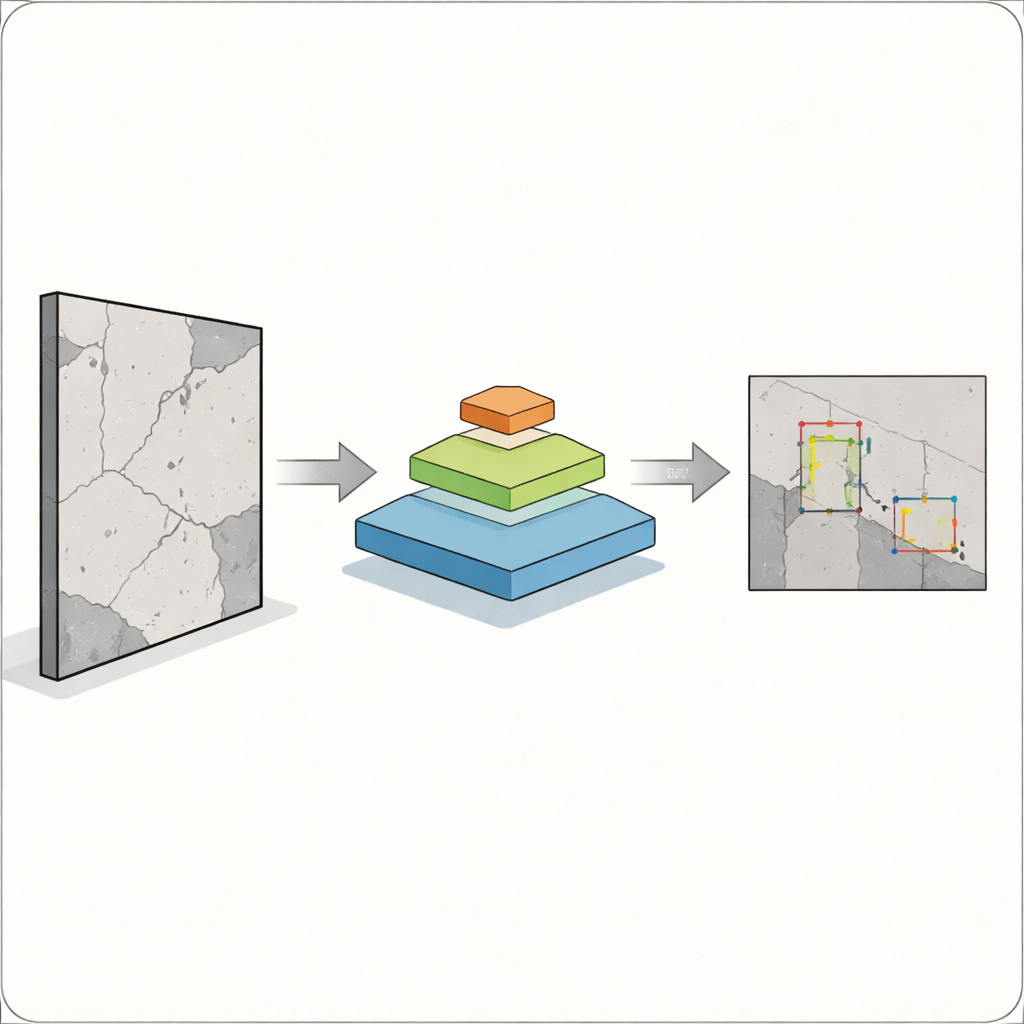
Combining fast vision with a smart pyramid
To do this, the researchers fuse two powerful ideas. They keep the latest YOLOv12 “detection head,” which is good at turning visual features into bounding boxes around objects, and replace its traditional backbone with a pyramid vision transformer. Instead of scanning only small neighborhoods of pixels, this transformer looks at the entire image and learns how distant regions relate to each other through a process called self-attention. At the same time, it builds a pyramid of feature maps at different resolutions—from coarse overviews to fine details—so that small cracks and large patches of damage can be represented together. These multi-scale feature maps are then fed into YOLOv12, which decides where and what the defects are.
Cleaning and enriching the training images
A clever model needs equally clever training data. Real-world concrete photos are messy, with shadows, uneven lighting, and rough textures that can hide flaws. The authors design an eight-step pre-processing pipeline to carve out clear “masks” of defects from raw images. They convert images to grayscale, remove noise, locally enhance contrast to reveal faint cracks, invert brightness so defects stand out, and use shape-based operations to connect broken crack fragments and remove tiny specks that are not true damage. The result is a clean outline of each defect.
Creating realistic synthetic defects
Because dangerous defects are rarer than intact surfaces, the training data are unbalanced: the model might otherwise learn that “no defect” is the safe bet. To fix this, the team builds a library of isolated defect masks and pastes them onto clean concrete backgrounds in many random positions, angles, and sizes. Rather than simply cutting and pasting, they use smooth blending so the edges of the defect merge naturally with the new surface. This produces realistic synthetic images that preserve the look of real cracks, rust, spalling, and other damage types, while greatly increasing the variety of examples the model sees during training. 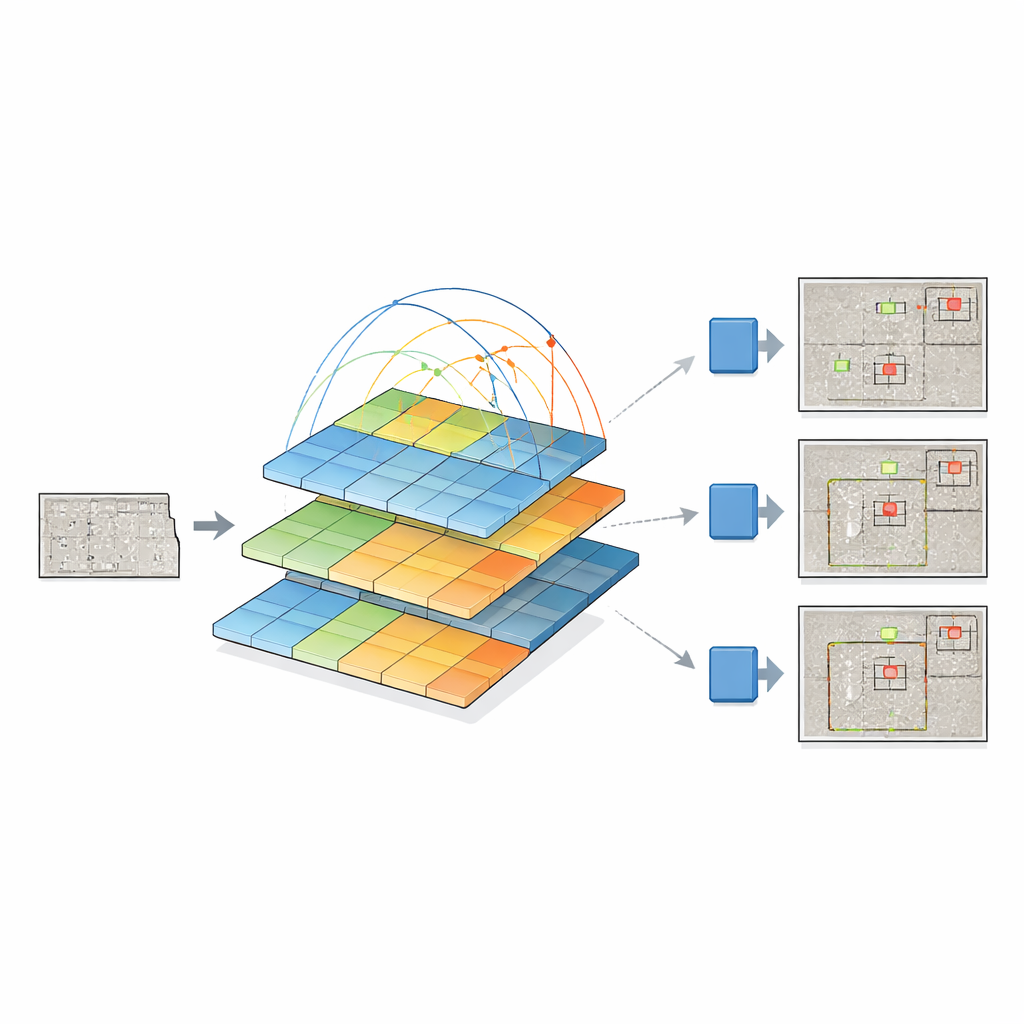
How well does it work?
The authors thoroughly compare their pyramid-transformer-plus-YOLO system with several families of detectors, including older YOLO versions, classic two-stage models like Faster R-CNN, and recent transformer-based designs such as DETR and DINO. Their model consistently improves detection of small defects, where the safety stakes are highest, and competes well on medium and large ones. It also outperforms a related design that uses a different transformer (Swin) as the backbone, while using fewer parameters and slightly less computation. Although the transformer backbone makes each prediction slower than the lightest YOLO variants, the gain in accuracy—especially on subtle defects in noisy concrete textures—is substantial.
Safer structures through sharper digital eyes
In practical terms, this research shows that pairing a pyramid vision transformer with a modern detector like YOLO can make AI much better at spotting tiny flaws without drowning engineers in false alarms. The model turns raw, cluttered inspection photos into multi-scale, globally informed representations that highlight cracks, rust, and spalling across a range of sizes. With improved data preparation and synthetic training images, it learns to tell real defects from harmless surface patterns. While there is still a trade-off between speed and accuracy, this approach moves automated inspection closer to reliable, real-world use—offering a sharper set of digital eyes to help prevent costly and dangerous failures in our built environment.
Citation: Baek, JW., Suh, D. & Chung, K. Multiscale object detection model based on pyramid vision transformer. Sci Rep 16, 13307 (2026). https://doi.org/10.1038/s41598-026-43522-8
Keywords: concrete defect detection, pyramid vision transformer, YOLO object detection, multiscale vision, infrastructure safety