Clear Sky Science · fr
Modèle de détection d'objets multiscale basé sur le pyramid vision transformer
Pourquoi les microfissures comptent
Des ponts et tunnels aux tours d'appartements, de nombreuses structures modernes sont en béton. De petites fissures ou défauts cachés dans ce béton peuvent évoluer en affaissements, chutes de débris, voire en effondrements. Les inspecteurs s'appuient encore largement sur la vue humaine, ce qui est lent, coûteux et susceptible de manquer de petits défauts pourtant dangereux. Cet article présente un nouveau système d'intelligence artificielle conçu pour repérer les défauts du béton de tailles très variées avec plus de précision, contribuant ainsi à améliorer la sécurité des bâtiments et des infrastructures.
Voir les défauts à plusieurs échelles
Le défi central est que les défauts n'apparaissent pas à une taille unique commode. Une large fissure est facile à capter pour les caméras et les algorithmes, mais une microfissure ou une tache de rouille peut être tout aussi importante et beaucoup plus difficile à détecter. Les systèmes classiques de détection d'objets, comme les versions antérieures de la famille YOLO largement utilisée, fonctionnent bien pour des objets plus grands et bien définis mais peinent souvent avec les petits objets, ceux qui se chevauchent ou qui sont peu contrastés. C'est particulièrement critique dans la construction, l'industrie ou la santé, où un défaut manqué peut compromettre la sécurité. Les auteurs visent à construire un détecteur capable de voir à la fois les problèmes larges et minuscules dans une même image, sans devenir trop lent pour une utilisation sur le terrain. 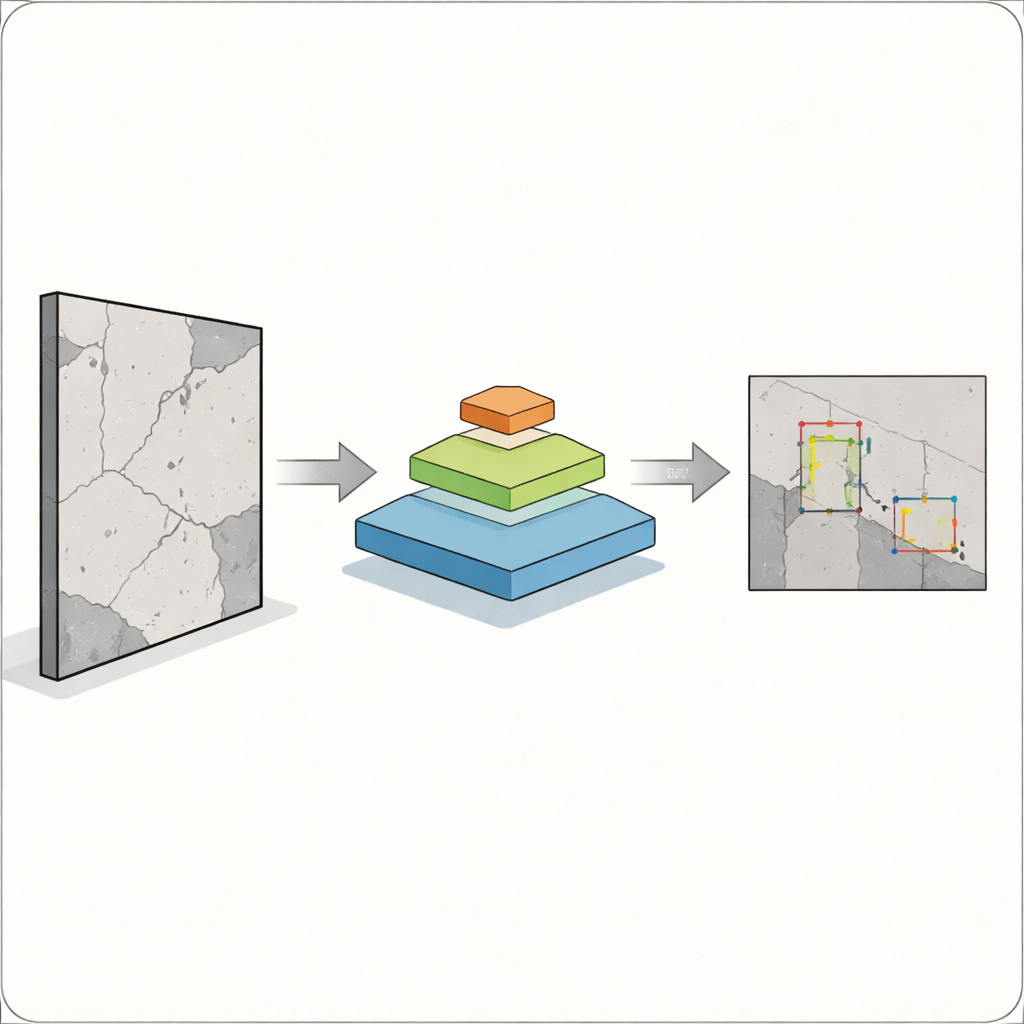
Allier vision rapide et pyramide intelligente
Pour y parvenir, les chercheurs combinent deux idées puissantes. Ils conservent la « detection head » de la dernière version YOLOv12, efficace pour transformer des caractéristiques visuelles en boîtes englobantes, et remplacent son backbone traditionnel par un pyramid vision transformer. Au lieu d'examiner uniquement de petits voisinages de pixels, ce transformeur analyse l'image dans son ensemble et apprend comment les régions éloignées se relient entre elles via un mécanisme d'attention. Parallèlement, il construit une pyramide de cartes de caractéristiques à différentes résolutions — des vues d'ensemble grossières aux détails fins — de sorte que les microfissures et les larges zones endommagées puissent être représentées simultanément. Ces cartes multi-échelle sont ensuite transmises à YOLOv12, qui décide où se trouvent les défauts et de quel type ils sont.
Nettoyer et enrichir les images d'entraînement
Un modèle ingénieux a besoin de données d'entraînement tout aussi soignées. Les photos réelles de béton sont encombrées : ombres, éclairage inégal et textures rugueuses peuvent masquer les défauts. Les auteurs conçoivent un pipeline de prétraitement en huit étapes pour extraire des « masques » nets des défauts à partir des images brutes. Ils convertissent les images en niveaux de gris, suppriment le bruit, améliorent localement le contraste pour révéler les fissures faibles, inversent la luminosité pour faire ressortir les défauts, et utilisent des opérations basées sur la forme pour connecter des fragments de fissures brisés et éliminer de petits points qui ne sont pas de vrais dommages. Le résultat est le contour propre de chaque défaut.
Créer des défauts synthétiques réalistes
Comme les défauts dangereux sont plus rares que les surfaces intactes, les données d'entraînement sont déséquilibrées : autrement, le modèle pourrait apprendre que « pas de défaut » est l'option sûre. Pour corriger cela, l'équipe construit une bibliothèque de masques de défauts isolés et les colle sur des fonds de béton propre à de nombreuses positions, angles et tailles aléatoires. Plutôt que de simplement découper-coller, ils utilisent un fondu lisse pour que les bords du défaut se fondent naturellement dans la surface. Cela produit des images synthétiques réalistes qui conservent l'apparence des fissures, de la rouille, de l'éclatement et d'autres types d'endommagement, tout en augmentant fortement la variété d'exemples présentés au modèle pendant l'entraînement. 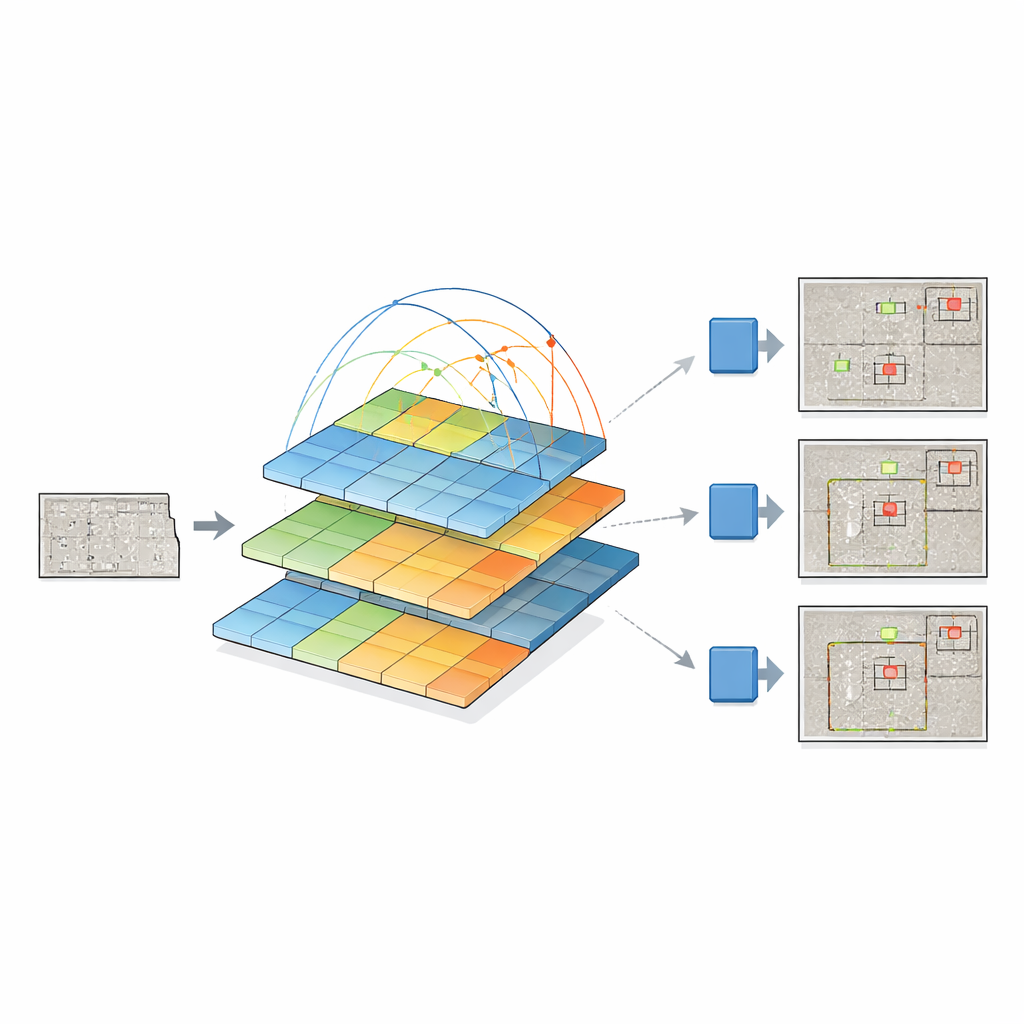
Quelle est son efficacité ?
Les auteurs comparent en profondeur leur système pyramide-transformer + YOLO à plusieurs familles de détecteurs, incluant des versions plus anciennes de YOLO, des modèles classiques en deux étapes comme Faster R-CNN, et des architectures récentes à base de transformeurs telles que DETR et DINO. Leur modèle améliore systématiquement la détection des petits défauts — où les enjeux de sécurité sont les plus élevés — et se montre compétitif sur les défauts de taille moyenne et grande. Il surpasse aussi une conception apparentée utilisant un autre transformeur (Swin) comme backbone, tout en employant moins de paramètres et un coût de calcul légèrement inférieur. Bien que le backbone transformeur ralentisse chaque prédiction par rapport aux variantes YOLO les plus légères, le gain en précision — notamment sur les défauts subtils dans des textures de béton bruitées — est substantiel.
Des structures plus sûres grâce à des yeux numériques plus précis
Concrètement, cette recherche montre que l’association d’un pyramid vision transformer avec un détecteur moderne comme YOLO peut grandement améliorer la capacité de l'IA à repérer de minuscules défauts sans submerger les ingénieurs de fausses alertes. Le modèle transforme des photos d'inspection brutes et encombrées en représentations multi-échelle et globales qui mettent en évidence fissures, rouille et éclatements sur une gamme de tailles. Avec une préparation des données améliorée et des images synthétiques d'entraînement, il apprend à distinguer de vrais défauts des motifs de surface inoffensifs. S'il subsiste un compromis entre vitesse et précision, cette approche rapproche l'inspection automatisée d'une utilisation fiable en conditions réelles — offrant une vision numérique plus acérée pour aider à prévenir des défaillances coûteuses et dangereuses dans notre environnement bâti.
Citation: Baek, JW., Suh, D. & Chung, K. Multiscale object detection model based on pyramid vision transformer. Sci Rep 16, 13307 (2026). https://doi.org/10.1038/s41598-026-43522-8
Mots-clés: détection de défauts du béton, pyramid vision transformer, détection d'objets YOLO, vision multi-échelle, sécurité des infrastructures