Clear Sky Science · ru
Многомасштабная модель обнаружения объектов на основе пирамидного визуального трансформера
Почему важны мелкие трещины
От мостов и туннелей до жилых высоток — многие современные конструкции выполнены из бетона. Мелкие трещины или скрытые дефекты в бетоне могут перерасти в провалы, падение обломков или даже обрушение. Инспекторы по-прежнему во многом полагаются на человеческий взгляд, который медленен, дорог и может пропустить небольшие, но опасные дефекты. В этой статье представлен новый искусственный интеллект (ИИ), который разработан для более точного выявления дефектов бетона разных размеров, что помогает повысить безопасность зданий и инфраструктуры.
Видеть дефекты на разных масштабах
Ключевая проблема в том, что дефекты бывают не одного удобного размера. Широкую трещину камерой и алгоритмами поймать проще, а микрощель или пятно ржавчины могут быть столь же значимы и намного труднее обнаружимы. Классические системы обнаружения объектов, такие как ранние версии популярных моделей семейства YOLO, хорошо работают для крупных, четко очерченных объектов, но часто испытывают трудности с малыми, накладывающимися или едва заметными объектами. Это особенно рискованно в строительстве, производстве и здравоохранении, где пропущенный дефект может повлиять на безопасность людей. Авторы ставят задачу создать детектор, который видит и крупные, и крошечные проблемы на одном изображении, не становясь при этом слишком медленным для полевого применения. 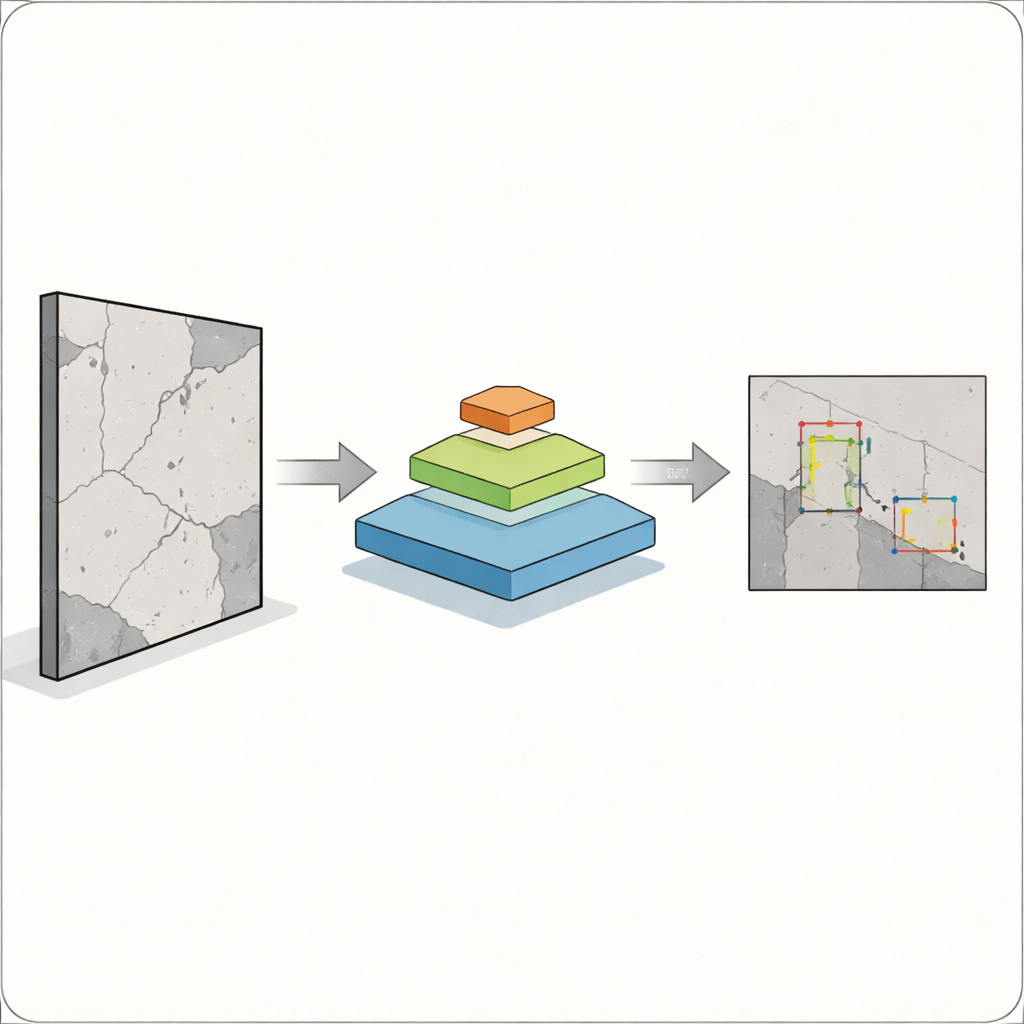
Сочетание быстрой обработки и умной пирамиды
Для этого исследователи объединяют две мощные идеи. Они сохраняют современную «голову» обнаружения YOLOv12, которая хорошо превращает визуальные признаки в ограничивающие рамки вокруг объектов, и заменяют её традиционный бэкбон на пирамидный визуальный трансформер. Вместо просмотра только соседних областей пикселей этот трансформер смотрит на всё изображение и учится тому, как удалённые регионы связаны между собой через механизм самовнимания. Одновременно он строит пирамиду карт признаков на разных разрешениях — от грубых обзоров до тонких деталей — чтобы мелкие трещины и крупные участки повреждений могли быть представлены совместно. Эти многомасштабные карты признаков затем подаются в YOLOv12, который определяет, где и какие дефекты присутствуют.
Очистка и обогащение обучающих изображений
Хитрой модели нужны соответствующе продуманные данные для обучения. Фотографии бетона в реальном мире шумны: тени, неравномерное освещение и грубая фактура могут скрывать дефекты. Авторы разрабатывают восьмиступенчатый конвейер предобработки, чтобы выделить чёткие «маски» дефектов из исходных изображений. Они переводят изображения в оттенки серого, удаляют шум, локально усиливают контраст, чтобы проявить слабые трещины, инвертируют яркость, чтобы дефекты выделялись, и применяют операции, основанные на форме, чтобы соединять разорванные фрагменты трещин и удалять мелкие пятна, не являющиеся реальными повреждениями. В результате получается чистый контур каждого дефекта.
Создание реалистичных синтетических дефектов
Поскольку опасные дефекты встречаются реже, чем неповреждённые поверхности, данные для обучения оказываются несбалансированными: модель в противном случае может сделать ставку на «дефекта нет». Чтобы это исправить, команда создала библиотеку изолированных масок дефектов и вставляет их на чистые бетонные фоны в разных случайных позициях, под углами и в различных масштабах. Вместо простого вырезания и вставки они используют плавное смешивание краёв, чтобы дефект естественно сливался с новой поверхностью. Это даёт реалистичные синтетические изображения, сохраняющие вид настоящих трещин, ржавчины, отслаивания и других типов повреждений, при значительном увеличении разнообразия примеров, с которыми модель встречается в обучении. 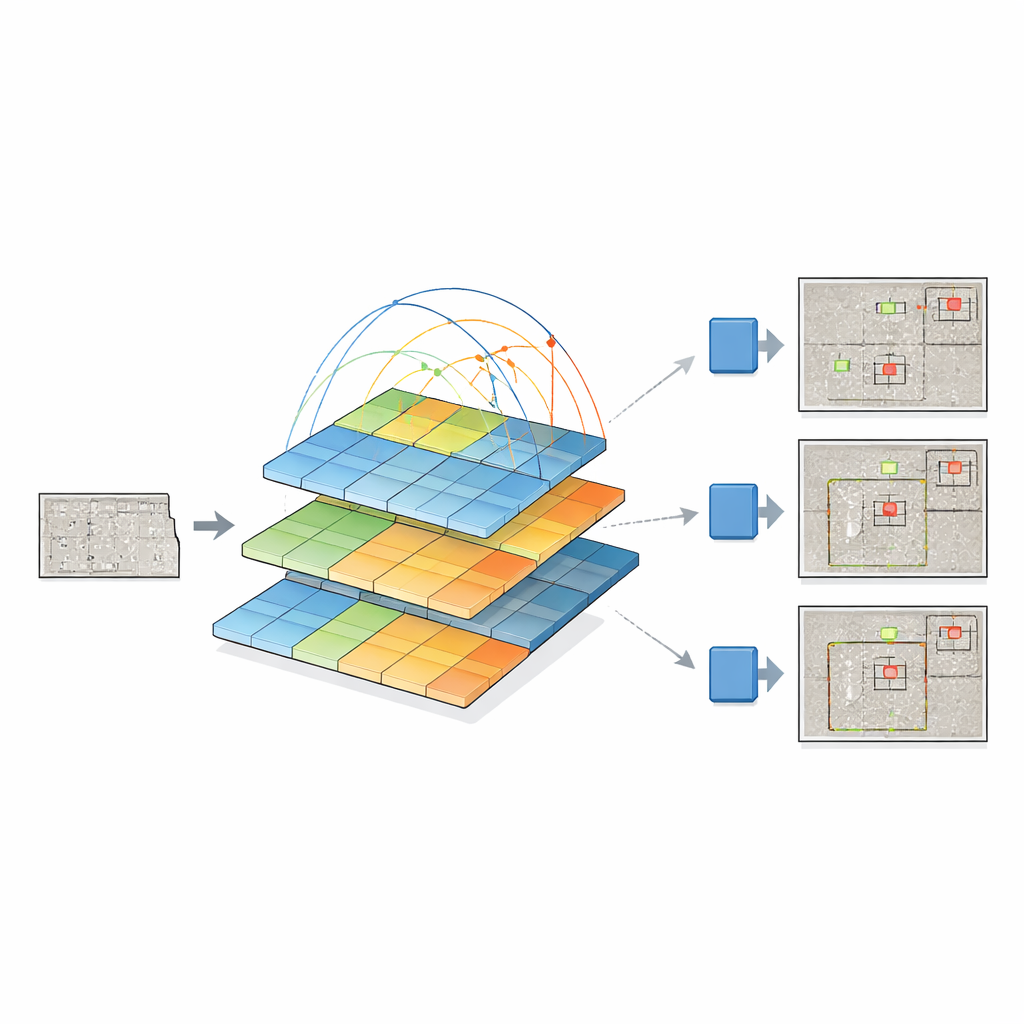
Насколько хорошо это работает?
Авторы тщательно сравнивают свою систему «пирамидный трансформер + YOLO» с несколькими семействами детекторов, включая старые версии YOLO, классические двухэтапные модели вроде Faster R-CNN и современные трансформерные конструкции, такие как DETR и DINO. Их модель последовательно улучшает обнаружение мелких дефектов, где ставки по безопасности наиболее высоки, и показывает конкурентоспособные результаты для средних и крупных дефектов. Она также превосходит связанный вариант с другим трансформером (Swin) в роли бэкбона, при этом использует меньше параметров и немного меньше вычислений. Хотя трансформерный бэкбон делает каждое предсказание медленнее по сравнению с самыми лёгкими вариантами YOLO, выигрыш в точности — особенно для тонких дефектов на шумных бетонных текстурах — существенен.
Безопаснее конструкции благодаря острому цифровому зрению
С практической точки зрения это исследование показывает, что сочетание пирамидного визуального трансформера с современным детектором вроде YOLO может значительно улучшить способность ИИ замечать мелкие дефекты без наводнения инженеров ложными срабатываниями. Модель превращает сырые, загромождённые инспекционные фотографии в многомасштабные, глобально информированные представления, которые выделяют трещины, ржавчину и отслаивание разных размеров. С улучшенной подготовкой данных и синтетическими тренировочными изображениями она учится отличать реальные дефекты от безвредных поверхностных узоров. Хотя компромисс между скоростью и точностью остаётся, этот подход приближает автоматизированную инспекцию к надёжному использованию в реальном мире — предлагая более острое цифровое зрение для предотвращения дорогостоящих и опасных отказов в нашей застроенной среде.
Цитирование: Baek, JW., Suh, D. & Chung, K. Multiscale object detection model based on pyramid vision transformer. Sci Rep 16, 13307 (2026). https://doi.org/10.1038/s41598-026-43522-8
Ключевые слова: обнаружение дефектов бетона, пирамидный визуальный трансформер, обнаружение объектов YOLO, многомасштабное зрение, безопасность инфраструктуры