Clear Sky Science · de
Multiskalen-Objekterkennungsmodell basierend auf Pyramid Vision Transformer
Warum winzige Risse wichtig sind
Von Brücken und Tunneln bis zu Wohnhochhäusern bestehen viele moderne Bauwerke aus Beton. Kleine Risse oder verborgene Defekte im Beton können sich zu Hohlräumen, herabfallenden Trümmern oder gar Einstürzen auswachsen. Prüfer verlassen sich weiterhin stark auf das menschliche Auge, das langsam, teuer ist und kleine, aber gefährliche Fehler übersehen kann. Dieses Paper stellt ein neues System der künstlichen Intelligenz (KI) vor, das Betondefekte in verschiedenen Größen genauer erkennen soll, um Gebäude und Infrastruktur sicherer zu machen.
Defekte in vielen Größen erkennen
Die zentrale Herausforderung ist, dass Defekte nicht in einer praktischen Einheitsgröße auftreten. Ein breiter Riss ist für Kameras und Algorithmen leicht zu erfassen, aber ein Haarriß oder ein Rostfleck kann ebenso wichtig und deutlich schwerer zu entdecken sein. Klassische Objekterkennungssysteme, etwa frühere Versionen der weit verbreiteten YOLO-Modelle, funktionieren gut für größere, klar abgegrenzte Objekte, haben jedoch oft Probleme mit kleinen, überlappenden oder schwachen Objekten. Das ist besonders riskant in Bauwesen, Fertigung und Gesundheitswesen, wo ein übersehener Fehler die Sicherheit beeinträchtigen kann. Die Autorinnen und Autoren wollen einen Detektor entwickeln, der sowohl große als auch winzige Probleme in einem einzelnen Bild erkennt, ohne dabei für den Einsatz vor Ort zu langsam zu werden. 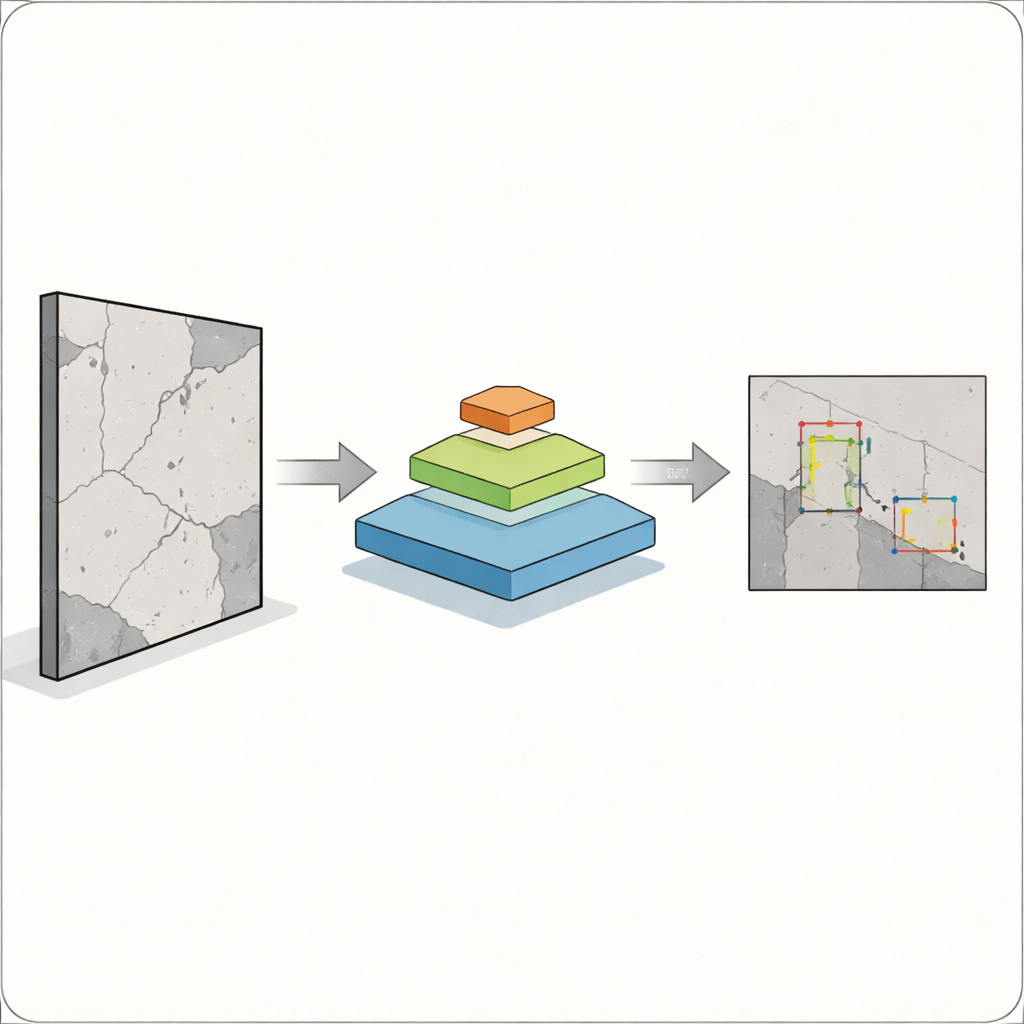
Schnelles Sehen mit einer intelligenten Pyramide verbinden
Dazu kombinieren die Forschenden zwei leistungsfähige Ideen. Sie behalten den aktuellen YOLOv12-„Detection Head“, der gut darin ist, visuelle Merkmale in Begrenzungsrahmen um Objekte zu übersetzen, und ersetzen das traditionelle Backbone durch einen Pyramid Vision Transformer. Statt nur kleine Pixelumgebungen abzusuchen, betrachtet dieser Transformer das gesamte Bild und lernt über einen Prozess namens Self-Attention, wie weit auseinanderliegende Regionen zusammenhängen. Gleichzeitig erstellt er eine Pyramide von Merkmalskarten in verschiedenen Auflösungen – von groben Übersichten bis zu feinen Details – sodass sowohl kleine Risse als auch große Schadstellen gemeinsam dargestellt werden können. Diese multiskaligen Merkmalskarten werden dann an YOLOv12 übergeben, das entscheidet, wo sich Defekte befinden und um welche Art von Schaden es sich handelt.
Trainingsbilder säubern und anreichern
Ein cleveres Modell braucht ebenso clevere Trainingsdaten. Fotos von echtem Beton sind unordentlich, mit Schatten, ungleichmäßiger Beleuchtung und rauen Texturen, die Fehler verbergen können. Die Autorinnen und Autoren entwerfen eine achtstufige Vorverarbeitungs-Pipeline, um aus Rohbildern klare „Masken“ der Defekte herauszuarbeiten. Sie wandeln Bilder in Graustufen um, entfernen Rauschen, verstärken lokal den Kontrast, um schwache Risse sichtbar zu machen, invertieren die Helligkeit, damit Defekte hervorstechen, und verwenden formbasierte Operationen, um gebrochene Rissfragmente zu verbinden und winzige Punkte zu entfernen, die keine echten Schäden sind. Das Ergebnis ist eine saubere Kontur jedes Defekts.
Realistische synthetische Defekte erzeugen
Da gefährliche Defekte seltener sind als intakte Flächen, sind die Trainingsdaten unausgewogen: Das Modell könnte sonst lernen, dass „kein Defekt“ die sichere Voraussage ist. Um das zu beheben, baut das Team eine Bibliothek isolierter Defektmasken auf und fügt diese an vielen zufälligen Positionen, Winkeln und Größen auf saubere Betonhintergründe ein. Anstatt einfach auszuschneiden und einzufügen, verwenden sie sanftes Blending, sodass die Ränder des Defekts natürlich mit der neuen Oberfläche verschmelzen. So entstehen realistische synthetische Bilder, die das Aussehen echter Risse, Rost, Abplatzungen und anderer Schadensarten bewahren und gleichzeitig die Vielfalt der Beispiele im Training deutlich erhöhen. 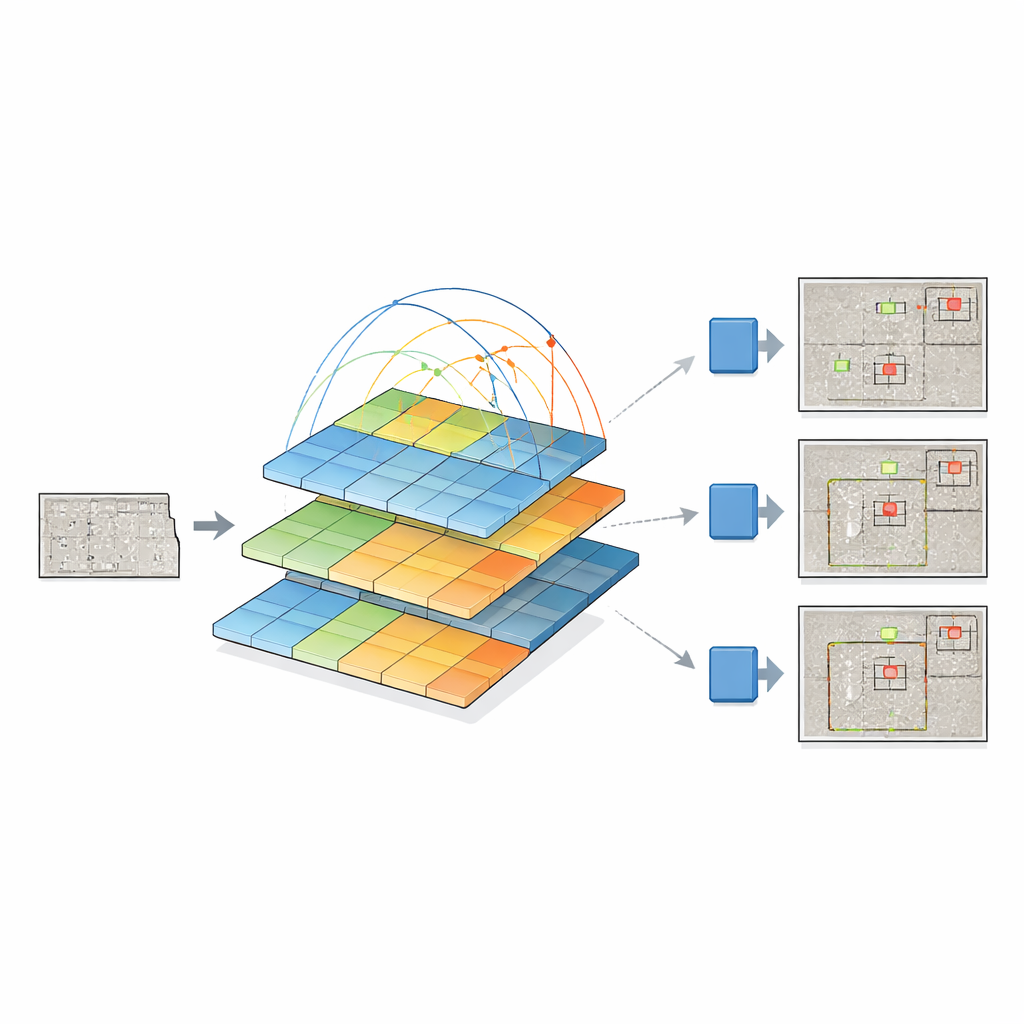
Wie gut funktioniert es?
Die Autorinnen und Autoren vergleichen ihr Pyramid-Transformer-plus-YOLO-System ausführlich mit mehreren Detektor-Familien, darunter ältere YOLO-Versionen, klassische Zwei-Stufen-Modelle wie Faster R-CNN und neuere transformerbasierte Entwürfe wie DETR und DINO. Ihr Modell verbessert durchgehend die Erkennung kleiner Defekte, bei denen die Sicherheitsrelevanz am höchsten ist, und schlägt sich auch bei mittleren und großen Defekten gut. Es übertrifft außerdem ein verwandtes Design, das einen anderen Transformer (Swin) als Backbone nutzt, bei gleichzeitig weniger Parametern und leicht geringerem Rechenaufwand. Obwohl das Transformer-Backbone jede Vorhersage langsamer macht als die leichtesten YOLO-Varianten, ist der Gewinn an Genauigkeit – insbesondere bei subtilen Defekten in verrauschten Betonstrukturen – beträchtlich.
Sicherere Bauwerke durch schärfere digitale Augen
Praktisch zeigt diese Forschung, dass die Kombination eines Pyramid Vision Transformer mit einem modernen Detektor wie YOLO die KI deutlich besser darin machen kann, winzige Fehler zu erkennen, ohne Ingenieurinnen und Ingenieure mit Fehlalarmen zu überfluten. Das Modell wandelt rohe, unübersichtliche Inspektionsfotos in multiskalige, global informierte Darstellungen um, die Risse, Rost und Abplatzungen über eine Bandbreite von Größen hervorheben. Mit verbesserter Datenvorbereitung und synthetischen Trainingsbildern lernt es, echte Defekte von harmlosen Oberflächenmustern zu unterscheiden. Auch wenn weiterhin ein Kompromiss zwischen Geschwindigkeit und Genauigkeit besteht, rückt dieser Ansatz die automatisierte Inspektion näher an einen zuverlässigen Einsatz in der Praxis – er bietet schärfere digitale Augen, die helfen können, teure und gefährliche Ausfälle in unserer gebauten Umwelt zu verhindern.
Zitation: Baek, JW., Suh, D. & Chung, K. Multiscale object detection model based on pyramid vision transformer. Sci Rep 16, 13307 (2026). https://doi.org/10.1038/s41598-026-43522-8
Schlüsselwörter: Betonschadensdetektion, Pyramid Vision Transformer, YOLO Objekterkennung, multiskalige Sicht, Infrastruktursicherheit