Clear Sky Science · it
Modello di rilevamento multiscala basato su pyramid vision transformer
Perché le microfessure sono importanti
Dai ponti e tunnel ai palazzi, molte strutture moderne sono realizzate in calcestruzzo. Microfessure o difetti nascosti in quel materiale possono evolvere in cedimenti, caduta di detriti o persino crolli. Gli ispettori si affidano ancora molto alla vista umana, che è lenta, costosa e può trascurare difetti piccoli ma pericolosi. Questo articolo presenta un nuovo sistema di intelligenza artificiale (IA) progettato per individuare difetti del calcestruzzo di dimensioni molto diverse con maggiore accuratezza, aiutando a mantenere edifici e infrastrutture più sicuri.
Individuare difetti a molte scale
La sfida principale è che i difetti non hanno una dimensione unica e comoda. Una crepa larga è facile da catturare per telecamere e algoritmi, ma una frattura capillare o una macchia di ruggine possono essere altrettanto importanti e molto più difficili da rilevare. I classici sistemi di rilevamento oggetti, come versioni precedenti della famiglia YOLO ampiamente usata, funzionano bene per oggetti più grandi e ben definiti ma spesso faticano con quelli piccoli, sovrapposti o sfumati. Questo è particolarmente rischioso in edilizia, produzione e sanità, dove un difetto non rilevato può compromettere la sicurezza. Gli autori mirano a costruire un rilevatore in grado di vedere contemporaneamente problemi grandi e minuscoli all’interno della stessa immagine, senza diventare troppo lento per l’uso sul campo. 
Combinare visione veloce con una piramide intelligente
Per farlo, i ricercatori fondono due idee potenti. Mantengono il più recente “detection head” di YOLOv12, efficace nel trasformare caratteristiche visive in box intorno agli oggetti, e sostituiscono il backbone tradizionale con un pyramid vision transformer. Invece di esaminare solo piccoli intorni di pixel, questo transformer osserva l’intera immagine e apprende come regioni distanti si relazionano tra loro tramite un processo chiamato self-attention. Allo stesso tempo costruisce una piramide di mappe di caratteristiche a diverse risoluzioni — dalle viste panoramiche ai dettagli fini — così che microfessure e ampie aree danneggiate possano essere rappresentate insieme. Queste mappe multiscala vengono poi alimentate in YOLOv12, che decide dove si trovano i difetti e di che tipo sono.
Pulire e arricchire le immagini di addestramento
Un modello intelligente richiede dati di addestramento altrettanto raffinati. Le foto reali del calcestruzzo sono disordinate, con ombre, illuminazione irregolare e trame ruvide che possono nascondere i difetti. Gli autori progettano una pipeline di pre-elaborazione in otto passaggi per estrarre chiare “maschere” dei difetti dalle immagini grezze. Convertono le immagini in scala di grigi, rimuovono il rumore, migliorano localmente il contrasto per rivelare crepe faticose da vedere, inverttono la luminosità in modo che i difetti risaltino e usano operazioni basate sulla forma per collegare frammenti di crepa spezzati e rimuovere piccole macchie che non sono veri danni. Il risultato è il contorno pulito di ogni difetto.
Creare difetti sintetici realistici
Poiché i difetti pericolosi sono più rari delle superfici intatte, i dati di addestramento sono sbilanciati: altrimenti il modello potrebbe imparare che “nessun difetto” è l’opzione più sicura. Per risolvere questo problema, il team costruisce una libreria di maschere di difetto isolate e le incolla su sfondi di calcestruzzo puliti in molte posizioni, angolazioni e dimensioni casuali. Anziché limitarsi a ritagliare e incollare, usano una fusione morbida così i bordi del difetto si integrano naturalmente con la nuova superficie. Questo produce immagini sintetiche realistiche che preservano l’aspetto di crepe, ruggine, scrostature e altri tipi di danno, aumentando notevolmente la varietà di esempi che il modello vede durante l’addestramento. 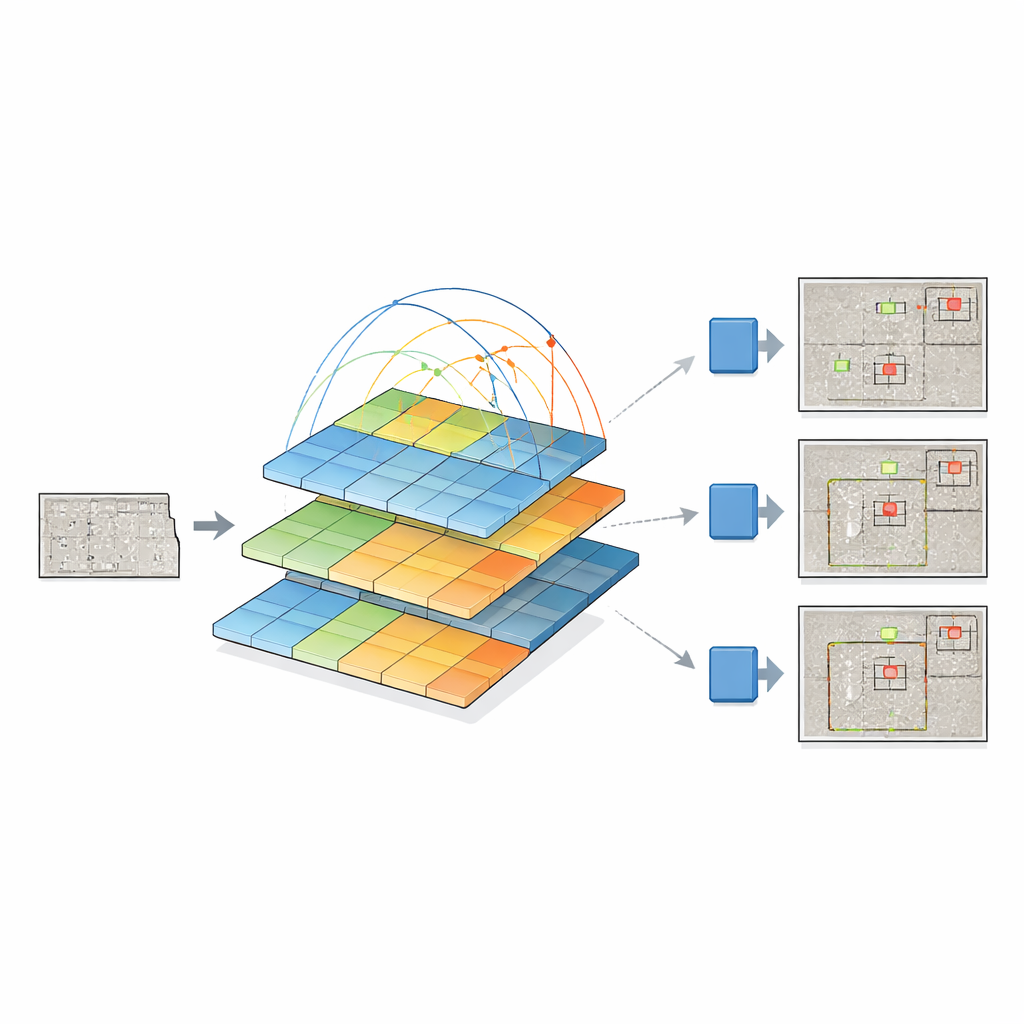
Che efficacia ha?
Gli autori confrontano approfonditamente il loro sistema pyramid-transformer-più-YOLO con diverse famiglie di rivelatori, incluse versioni più vecchie di YOLO, modelli classici a due stadi come Faster R-CNN e recenti architetture basate su transformer come DETR e DINO. Il loro modello migliora costantemente la rilevazione di difetti piccoli, dove sono maggiori i rischi per la sicurezza, e si comporta bene anche su quelli medi e grandi. Supera inoltre un progetto correlato che usa un diverso transformer (Swin) come backbone, pur impiegando meno parametri e leggermente meno calcolo. Sebbene il backbone transformer renda ogni predizione più lenta rispetto alle varianti YOLO più leggere, il guadagno in accuratezza — specialmente sui difetti sottili in texture di calcestruzzo rumorose — è sostanziale.
Strutture più sicure grazie a occhi digitali più acuti
In termini pratici, questa ricerca dimostra che accoppiare un pyramid vision transformer con un rilevatore moderno come YOLO può rendere l’IA molto migliore nel rilevare piccoli difetti senza sommergere gli ingegneri con falsi allarmi. Il modello trasforma foto d’ispezione grezze e disordinate in rappresentazioni multiscala e globalmente informate che evidenziano crepe, ruggine e scrostature in un ampio spettro di dimensioni. Con una migliore preparazione dei dati e immagini sintetiche di addestramento, impara a distinguere i difetti reali da pattern superficiali innocui. Pur rimanendo un compromesso tra velocità e accuratezza, questo approccio avvicina l’ispezione automatizzata a un uso reale e affidabile — offrendo un set di occhi digitali più acuti per aiutare a prevenire guasti costosi e pericolosi nel nostro ambiente costruito.
Citazione: Baek, JW., Suh, D. & Chung, K. Multiscale object detection model based on pyramid vision transformer. Sci Rep 16, 13307 (2026). https://doi.org/10.1038/s41598-026-43522-8
Parole chiave: rilevamento difetti nel calcestruzzo, pyramid vision transformer, rilevamento oggetti YOLO, visione multiscala, sicurezza delle infrastrutture