Clear Sky Science · pl
Wieloskalowy model detekcji obiektów oparty na pyramid vision transformer
Dlaczego drobne rysy mają znaczenie
Od mostów i tuneli po wieżowce mieszkalne — wiele współczesnych konstrukcji wykonano z betonu. Drobne pęknięcia lub ukryte wady w tym materiale mogą rozwijać się w zapadliska, odrywające się elementy lub nawet doprowadzić do zawalenia. Inspektorzy wciąż w dużej mierze polegają na ludzkim wzroku, który jest powolny, kosztowny i może przeoczyć małe, lecz niebezpieczne defekty. W artykule przedstawiono nowy system sztucznej inteligencji zaprojektowany do dokładniejszego wykrywania wad betonu o różnych rozmiarach, co pomaga zwiększyć bezpieczeństwo budynków i infrastruktury.
Wykrywanie wad w różnych skalach
Głównym wyzwaniem jest to, że wady nie występują w jednej wygodnej wielkości. Szerokie pęknięcie jest łatwe do wychwycenia przez kamery i algorytmy, ale włosowata szczelina czy plamka rdzy mogą być równie istotne i znacznie trudniejsze do wykrycia. Klasyczne systemy detekcji obiektów, takie jak wcześniejsze wersje popularnej rodziny modeli YOLO, dobrze radzą sobie z większymi, wyraźnymi obiektami, lecz często mają trudności z małymi, nakładającymi się lub słabo widocznymi defektami. Jest to szczególnie ryzykowne w budownictwie, produkcji i opiece zdrowotnej, gdzie przeoczenie wady może wpłynąć na bezpieczeństwo ludzi. Autorzy dążą do stworzenia detektora, który potrafi dostrzec zarówno duże, jak i drobne problemy na jednym obrazie, nie stając się przy tym zbyt wolny do zastosowań terenowych. 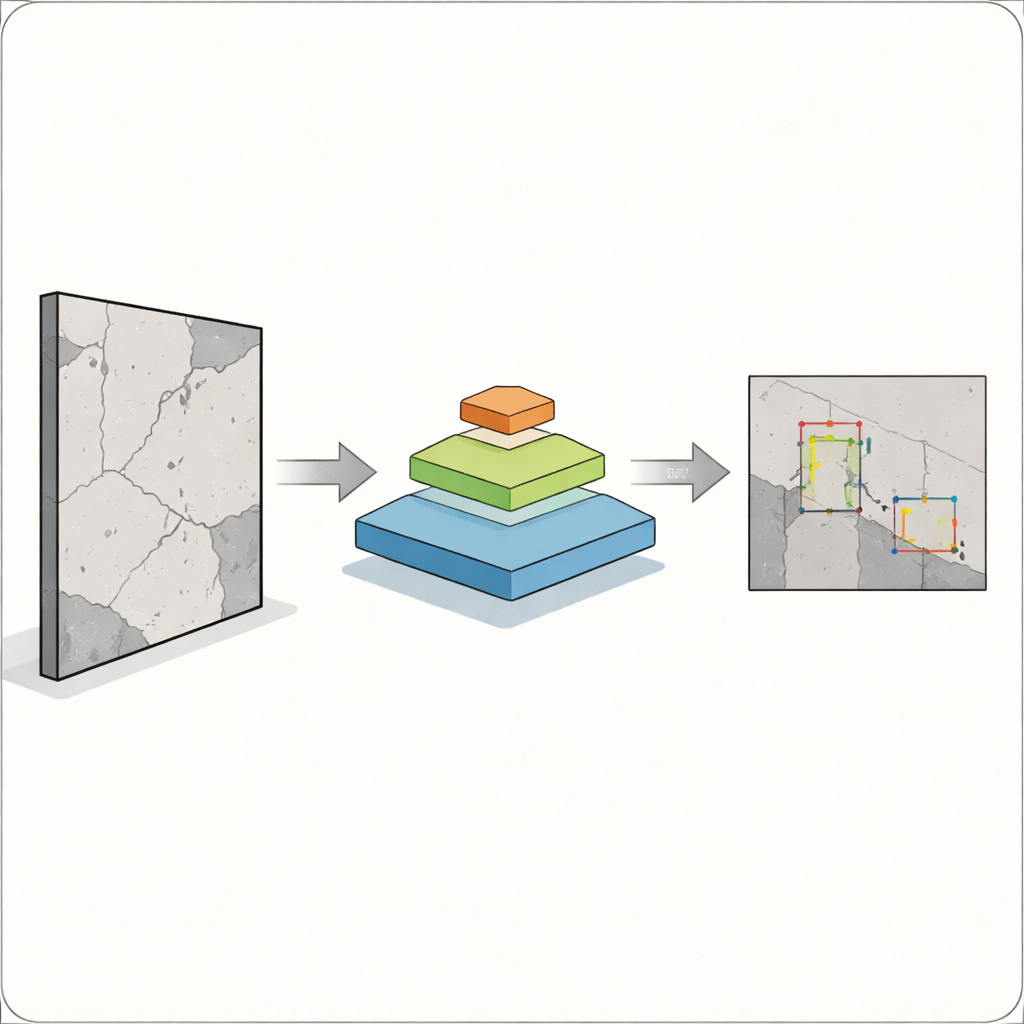
Łączenie szybkiego widzenia ze sprytną piramidą
Aby to osiągnąć, badacze łączą dwie silne idee. Zachowują najnowszy „detection head” YOLOv12, który sprawnie przekształca cechy wizualne w ramki ograniczające obiekty, i zastępują tradycyjny backbone modułem pyramid vision transformer. Zamiast analizować jedynie małe sąsiedztwa pikseli, ten transformer patrzy na cały obraz i uczy się, jak odległe obszary są ze sobą powiązane dzięki mechanizmowi self-attention. Jednocześnie buduje piramidę map cech o różnych rozdzielczościach — od ogólnych przeglądów po drobne detale — tak aby włosowate pęknięcia i duże obszary uszkodzeń mogły być reprezentowane razem. Te wieloskalowe mapy cech trafiają następnie do YOLOv12, który decyduje, gdzie i jakie występują wady.
Oczyszczanie i wzbogacanie obrazów treningowych
Inteligentny model wymaga równie inteligentnych danych treningowych. Zdjęcia betonu z rzeczywistości są chaotyczne, mają cienie, nierównomierne oświetlenie i chropowate faktury, które mogą ukrywać defekty. Autorzy zaprojektowali ośmiostopniowy proces wstępnej obróbki, aby wyciąć wyraźne „maski” wad z surowych obrazów. Konwertują obrazy do skali szarości, usuwają szum, lokalnie wzmacniają kontrast, by uwidocznić słabe pęknięcia, odwracają jasność, aby wady się wyróżniały, i stosują operacje zależne od kształtu, by połączyć fragmenty pęknięć oraz usunąć drobne plamki, które nie są rzeczywistymi uszkodzeniami. Efektem jest czysty obrys każdej wady.
Tworzenie realistycznych defektów syntetycznych
Ponieważ niebezpieczne wady występują rzadziej niż nienaruszone powierzchnie, dane treningowe są niezbalansowane: w przeciwnym razie model mógłby nauczyć się, że „brak wady” to bezpieczne założenie. Aby to naprawić, zespół tworzy bibliotekę izolowanych masek defektów i wkleja je na czyste betonowe tła w wielu losowych pozycjach, kątach i rozmiarach. Zamiast prostego wklejania, używają płynnego wygładzania, dzięki czemu krawędzie defektu naturalnie stapiają się z nową powierzchnią. Powstają realistyczne obrazy syntetyczne, które zachowują wygląd prawdziwych pęknięć, rdzy, odprysków i innych rodzajów uszkodzeń, a jednocześnie znacznie zwiększają różnorodność przykładów widzianych przez model podczas treningu. 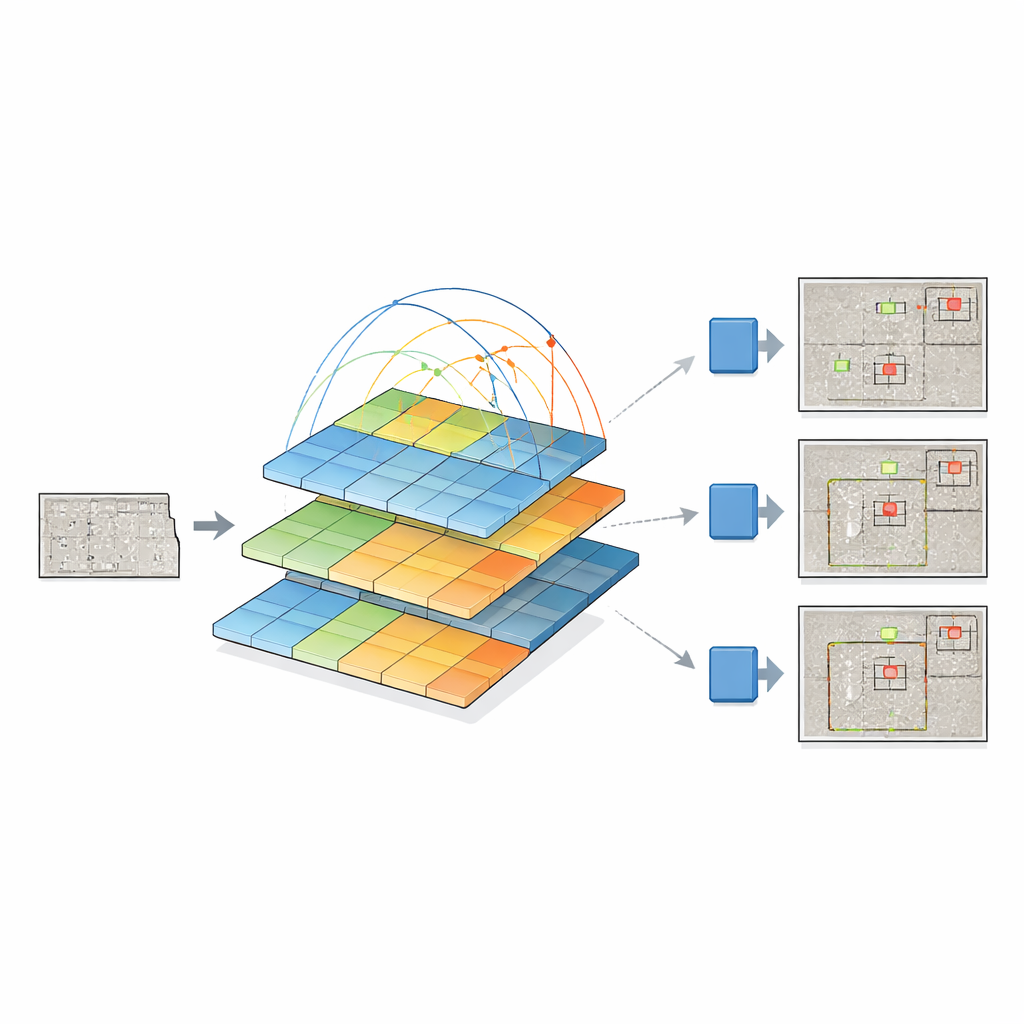
Jak dobrze to działa?
Autorzy dokładnie porównują swój system łączący pyramid-transformer z YOLO z kilkoma rodzinami detektorów, w tym starszymi wersjami YOLO, klasycznymi modelami dwustopniowymi jak Faster R-CNN oraz nowymi projektami opartymi na transformerach, takimi jak DETR i DINO. Ich model konsekwentnie poprawia wykrywanie małych wad, gdzie stawka jest najważniejsza, i dobrze konkurować na obiektach średnich i dużych. Przewyższa też powiązaną architekturę używającą innego transformera (Swin) jako backbone, jednocześnie wykorzystując mniej parametrów i nieco mniejsze zapotrzebowanie obliczeniowe. Chociaż backbone oparty na transformerze sprawia, że pojedyncze predykcje są wolniejsze niż w najlżejszych wariantach YOLO, zysk w dokładności — szczególnie w wykrywaniu subtelnych wad na zaszumionych teksturach betonu — jest znaczący.
Bezpieczniejsze konstrukcje dzięki ostrzejszym cyfrowym oczom
W praktyce badania te pokazują, że połączenie pyramid vision transformer z nowoczesnym detektorem jak YOLO może znacznie polepszyć zdolność AI do wykrywania drobnych usterek bez zalewania inżynierów fałszywymi alarmami. Model przekształca surowe, zagracone zdjęcia inspekcyjne w wieloskalowe, globalnie skonsolidowane reprezentacje, które uwydatniają pęknięcia, rdzę i odpryski w różnych rozmiarach. Dzięki ulepszonej obróbce danych i synchronicznym obrazom syntetycznym uczy się rozróżniać prawdziwe wady od nieszkodliwych wzorów powierzchni. Choć nadal istnieje kompromis między szybkością a dokładnością, podejście to przybliża automatyczną inspekcję do niezawodnego zastosowania w rzeczywistych warunkach — oferując ostrzejszy zestaw cyfrowych oczu, które pomagają zapobiegać kosztownym i niebezpiecznym awariom w naszej zabudowanej przestrzeni.
Cytowanie: Baek, JW., Suh, D. & Chung, K. Multiscale object detection model based on pyramid vision transformer. Sci Rep 16, 13307 (2026). https://doi.org/10.1038/s41598-026-43522-8
Słowa kluczowe: wykrywanie wad betonu, pyramid vision transformer, detekcja obiektów YOLO, widzenie wieloskalowe, bezpieczeństwo infrastruktury