Clear Sky Science · es
Modelo de detección de objetos multiescala basado en transformer piramidal de visión
Por qué importan las grietas diminutas
Desde puentes y túneles hasta torres de apartamentos, muchas estructuras modernas están hechas de hormigón. Pequeñas grietas o defectos ocultos en ese hormigón pueden crecer hasta provocar hundimientos, caída de escombros o incluso colapsos. Los inspectores siguen confiando en gran medida en la vista humana, que es lenta, costosa y puede pasar por alto fallos pequeños pero peligrosos. Este artículo presenta un nuevo sistema de inteligencia artificial (IA) diseñado para detectar defectos en el hormigón de tamaños muy diversos con mayor precisión, ayudando a mantener edificios e infraestructuras más seguros.
Detectar defectos a muchas escalas
El desafío principal es que los defectos no vienen en un único tamaño cómodo. Una grieta ancha es fácil de captar para cámaras y algoritmos, pero una fisura capilar o una motita de óxido puede ser igual de importante y mucho más difícil de detectar. Los sistemas clásicos de detección de objetos, como versiones anteriores de la familia YOLO ampliamente usada, funcionan bien con objetos grandes y bien definidos, pero a menudo tienen problemas con objetos pequeños, solapados o tenue. Esto resulta especialmente arriesgado en construcción, fabricación y sanidad, donde un fallo no detectado puede afectar a la seguridad. Los autores buscan construir un detector que vea tanto problemas grandes como diminutos dentro de una sola imagen, sin volverse demasiado lento para su uso en campo. 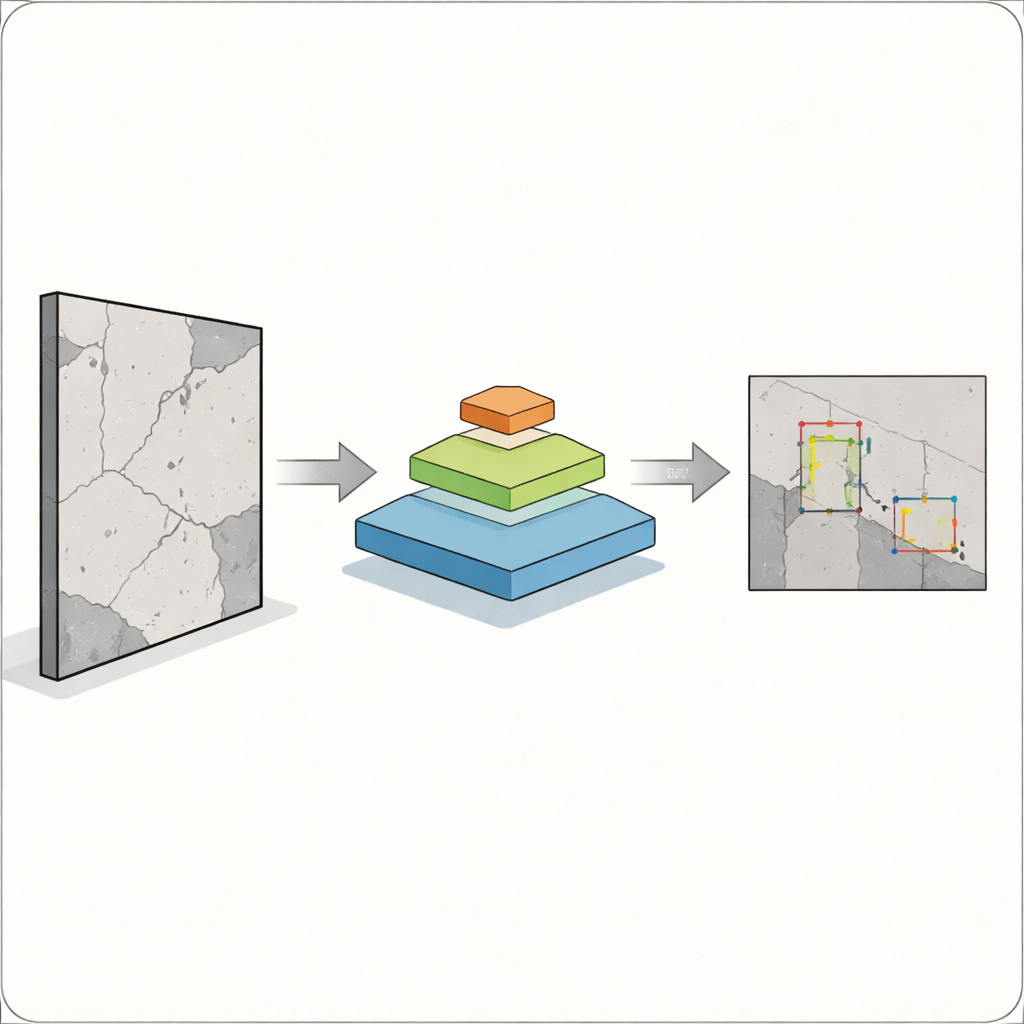
Combinar visión rápida con una pirámide inteligente
Para lograrlo, los investigadores fusionan dos ideas potentes. Conservan la moderna “cabeza de detección” de YOLOv12, que es buena convirtiendo características visuales en cuadros delimitadores alrededor de objetos, y reemplazan su backbone tradicional por un transformer piramidal de visión. En lugar de examinar solo vecindarios pequeños de píxeles, este transformer observa toda la imagen y aprende cómo se relacionan regiones distantes mediante un proceso llamado auto-atención. Al mismo tiempo, construye una pirámide de mapas de características a diferentes resoluciones —desde visiones generales hasta detalles finos— para que puedan representarse juntos tanto las grietas pequeñas como las áreas grandes de daño. Estos mapas de características multiescala se alimentan luego a YOLOv12, que decide dónde están y qué son los defectos.
Limpiar y enriquecer las imágenes de entrenamiento
Un modelo inteligente necesita datos de entrenamiento igualmente inteligentes. Las fotos reales de hormigón son desordenadas, con sombras, iluminación desigual y texturas rugosas que pueden ocultar fallos. Los autores diseñan una canalización de preprocesado de ocho pasos para extraer “máscaras” claras de los defectos a partir de las imágenes crudas. Convierten las imágenes a escala de grises, eliminan ruido, mejoran localmente el contraste para revelar grietas tenues, invierten la luminancia para que los defectos resalten y utilizan operaciones basadas en forma para conectar fragmentos de grietas rotas y eliminar pequeñas motas que no son daños reales. El resultado es el contorno limpio de cada defecto.
Crear defectos sintéticos realistas
Debido a que los defectos peligrosos son menos frecuentes que las superficies intactas, los datos de entrenamiento están desbalanceados: de otro modo, el modelo podría aprender que «sin defecto» es la opción segura. Para corregir esto, el equipo construye una biblioteca de máscaras de defectos aisladas y las pega sobre fondos de hormigón limpios en muchas posiciones, ángulos y tamaños aleatorios. En lugar de recortar y pegar de forma tosca, usan un mezclado suave para que los bordes del defecto se integren de forma natural con la nueva superficie. Esto produce imágenes sintéticas realistas que conservan el aspecto de grietas reales, óxido, desprendimientos y otros tipos de daño, al tiempo que aumentan ampliamente la variedad de ejemplos que el modelo ve durante el entrenamiento. 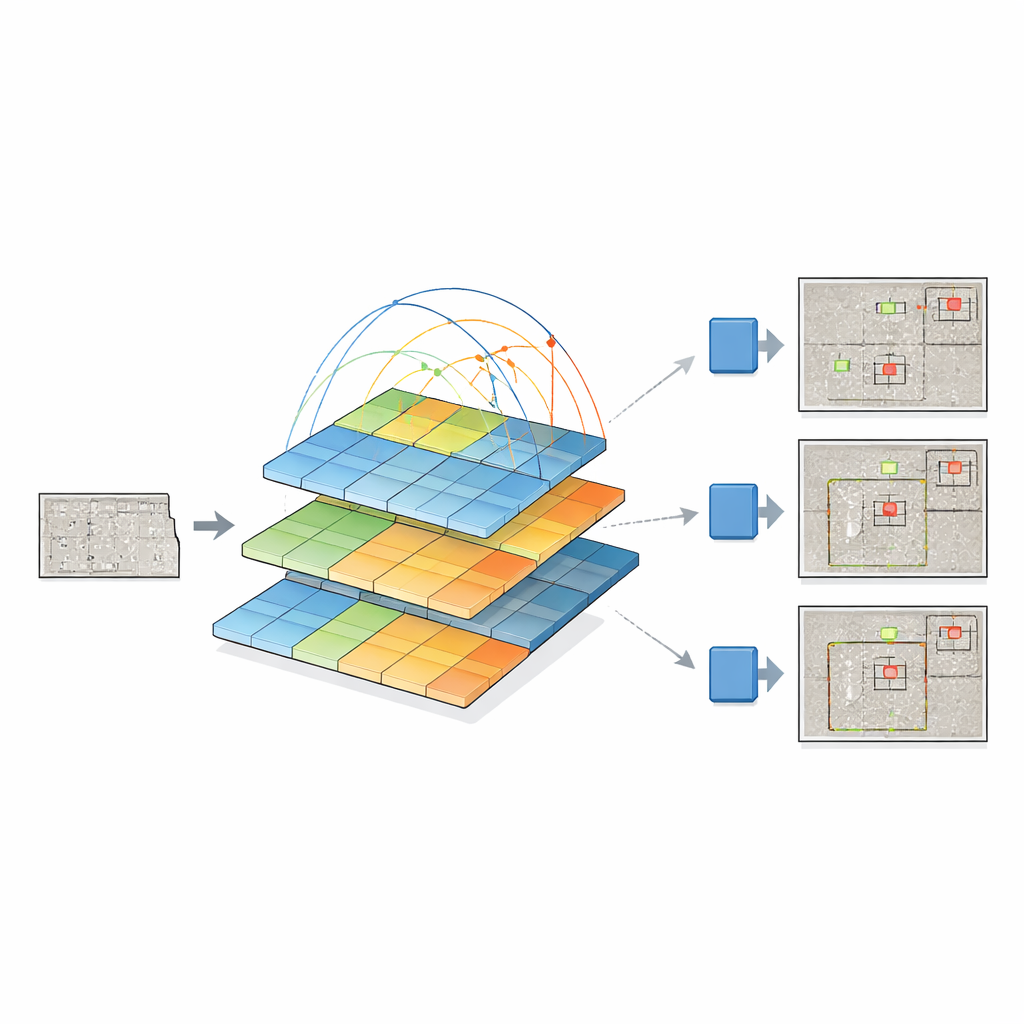
¿Qué tan bien funciona?
Los autores comparan exhaustivamente su sistema de transformer piramidal más YOLO con varias familias de detectores, incluidas versiones antiguas de YOLO, modelos clásicos de dos etapas como Faster R-CNN y diseños recientes basados en transformers como DETR y DINO. Su modelo mejora de manera consistente la detección de defectos pequeños, donde las implicaciones de seguridad son mayores, y compite bien en defectos medianos y grandes. También supera a un diseño relacionado que utiliza otro transformer (Swin) como backbone, empleando además menos parámetros y un cálculo ligeramente menor. Aunque el backbone transformer hace que cada predicción sea más lenta que las variantes YOLO más ligeras, la ganancia en exactitud —especialmente en defectos sutiles sobre texturas de hormigón ruidosas— es sustancial.
Estructuras más seguras mediante ojos digitales más nítidos
En términos prácticos, esta investigación demuestra que emparejar un transformer piramidal de visión con un detector moderno como YOLO puede mejorar mucho la capacidad de la IA para detectar fallos diminutos sin inundar a los ingenieros con falsas alarmas. El modelo convierte fotos de inspección crudas y con ruido en representaciones multiescala y globales que resaltan grietas, óxido y desprendimientos en una variedad de tamaños. Con una mejor preparación de datos e imágenes sintéticas de entrenamiento, aprende a distinguir defectos reales de patrones superficiales inofensivos. Aunque todavía existe un equilibrio entre velocidad y precisión, este enfoque acerca la inspección automatizada a un uso fiable en el mundo real, ofreciendo un conjunto de ojos digitales más nítidos para ayudar a prevenir fallos costosos y peligrosos en nuestro entorno construido.
Cita: Baek, JW., Suh, D. & Chung, K. Multiscale object detection model based on pyramid vision transformer. Sci Rep 16, 13307 (2026). https://doi.org/10.1038/s41598-026-43522-8
Palabras clave: detección de defectos en hormigón, transformer piramidal de visión, detección de objetos YOLO, visión multiescala, seguridad de infraestructuras