Clear Sky Science · nl
Multischaal objectdetectiemodel gebaseerd op pyramid vision transformer
Waarom kleine scheuren ertoe doen
Van bruggen en tunnels tot wooncomplexen: veel moderne constructies zijn van beton gemaakt. Kleine scheurtjes of verborgen gebreken in dat beton kunnen uitgroeien tot verzakkingen, vallend puin of zelfs instorting. Inspecteurs vertrouwen nog steeds sterk op hun ogen, wat traag en kostbaar is en kleine maar gevaarlijke fouten kan missen. Dit artikel presenteert een nieuw kunstmatig-intelligentiesysteem (AI) dat ontworpen is om betondefecten van zeer verschillende afmetingen nauwkeuriger te herkennen, en zo bij te dragen aan veiliger gebouwen en infrastructuur.
Defecten waarnemen op verschillende schalen
De kernuitdaging is dat defecten niet één handige maat hebben. Een brede scheur is voor camera’s en algoritmen relatief gemakkelijk te vinden, maar een haarfijne barst of een roestvlek kan net zo belangrijk en veel lastiger te detecteren zijn. Klassieke objectdetectiesystemen, zoals eerdere versies uit de veelgebruikte YOLO-familie, werken goed voor grotere, goed afgebakende objecten, maar hebben vaak moeite met kleine, overlappende of vage exemplaren. Dat is extra risicovol in bouw, fabricage en gezondheidszorg, waar een gemist defect de veiligheid kan aantasten. De auteurs willen een detector bouwen die zowel grote als kleine problemen binnen één afbeelding kan zien zonder te traag te worden voor praktisch gebruik. 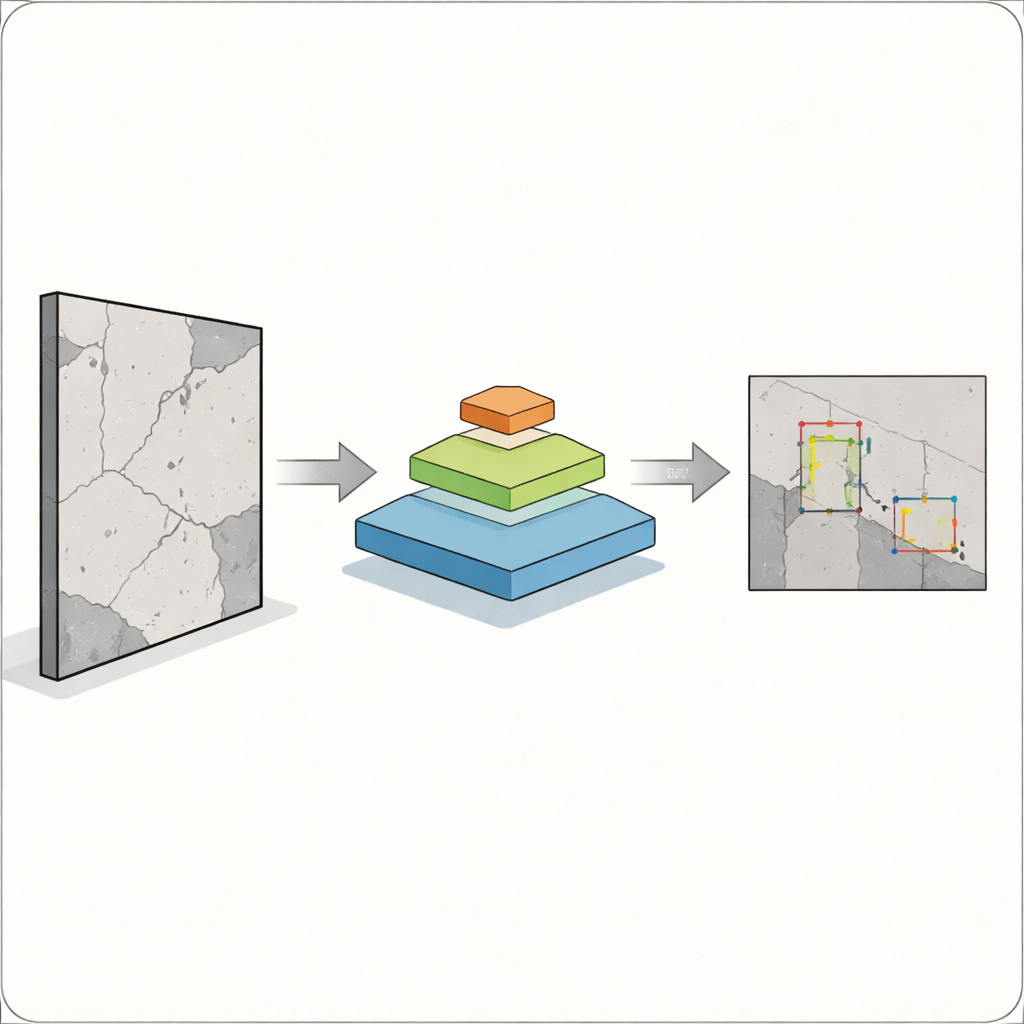
Snelle visuele verwerking gecombineerd met een slimme piramide
Daartoe combineren de onderzoekers twee krachtige ideeën. Ze behouden de nieuwste YOLOv12 “detection head”, die goed is in het omzetten van visuele kenmerken naar begrenzende kaders rond objecten, en vervangen de traditionele backbone door een pyramid vision transformer. In plaats van alleen kleine pixelbuurten te bekijken, kijkt deze transformer naar de hele afbeelding en leert hij hoe verre regio’s zich tot elkaar verhouden via een proces dat zelfaandacht (self-attention) heet. Tegelijk bouwt hij een piramide van featuremaps op verschillende resoluties — van grof overzicht tot fijne details — zodat zowel kleine scheurtjes als grote schadeplekken samen weergegeven kunnen worden. Deze multischaal featuremaps worden vervolgens gevoed aan YOLOv12, dat beslist waar de defecten zitten en wat ze zijn.
De trainingsbeelden opschonen en verrijken
Een slim model heeft even slimme trainingsdata nodig. Foto’s van echt beton zijn rommelig, met schaduwen, ongelijkmatige belichting en ruwe texturen die gebreken kunnen verbergen. De auteurs ontwerpen een achtstappen-voorverwerkingspipeline om duidelijke “maskers” van defecten uit ruwe beelden te halen. Ze zetten beelden om naar grijswaarden, verwijderen ruis, versterken lokaal het contrast om vage scheuren zichtbaar te maken, inverteren de helderheid zodat defecten opvallen, en gebruiken vormgebaseerde bewerkingen om gebroken scheurfragmenten te verbinden en kleine vlekjes te verwijderen die geen echte schade zijn. Het resultaat is een nette omtrek van elk defect.
Het maken van realistische synthetische defecten
Aangezien gevaarlijke defecten zeldzamer zijn dan onbeschadigde oppervlakken, zijn de trainingsgegevens uit balans: het model zou anders kunnen leren dat “geen defect” de veilige gok is. Om dit te verhelpen bouwen de onderzoekers een bibliotheek van geïsoleerde defectmaskers en plakken die op schone betonnen achtergronden op vele willekeurige posities, hoeken en maten. In plaats van simpelweg knippen en plakken gebruiken ze vloeiende blending zodat de randen van het defect natuurlijk in het nieuwe oppervlak overgaan. Dit levert realistische synthetische beelden op die het uiterlijk van echte scheuren, roest, afbrokkeling en andere schadevormen behouden, terwijl de variatie aan voorbeelden waar het model tijdens training mee te maken krijgt flink toeneemt. 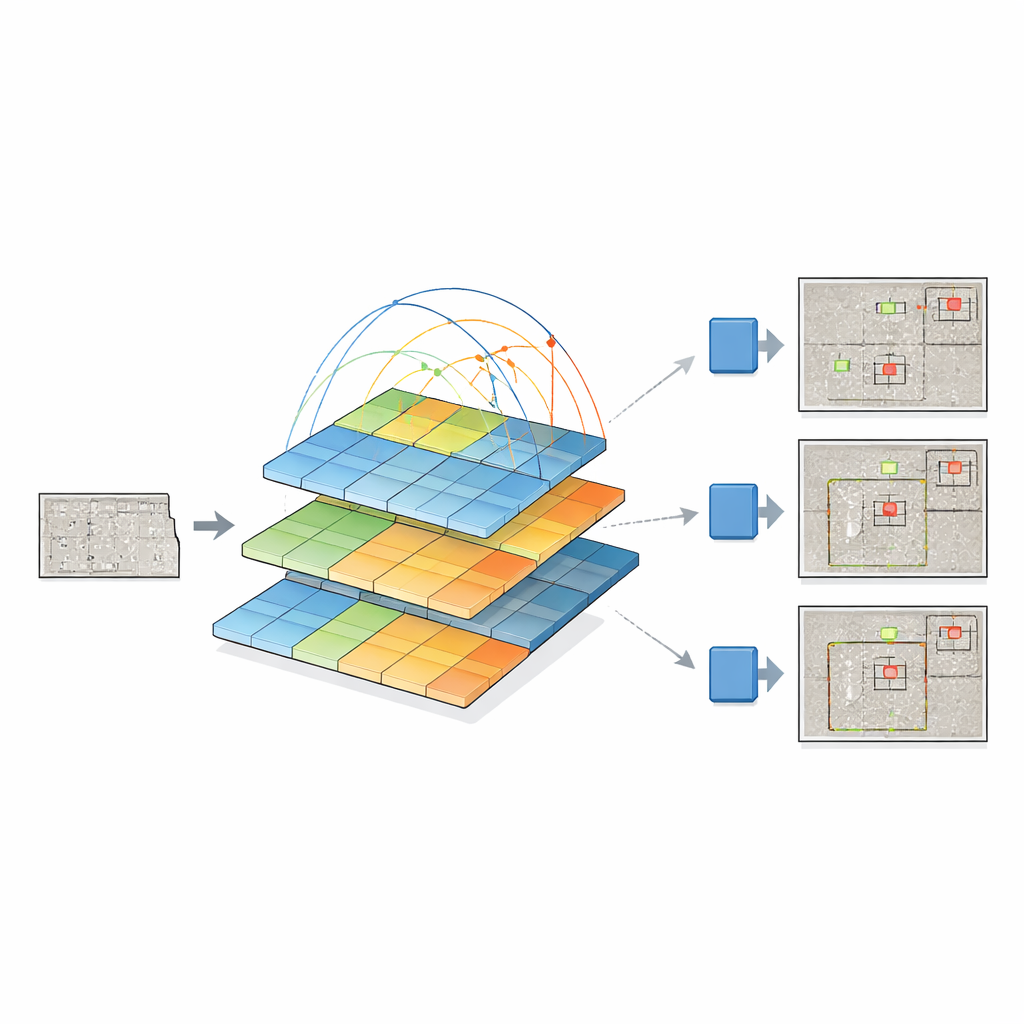
Hoe goed werkt het?
De auteurs vergelijken hun pyramid-transformer-plus-YOLO-systeem grondig met meerdere families detectors, inclusief oudere YOLO-versies, klassieke tweefasige modellen zoals Faster R-CNN, en recente transformer-gebaseerde ontwerpen zoals DETR en DINO. Hun model verbetert consequent de detectie van kleine defecten—waar de veiligheidsbelangen het grootst zijn—en presteert ook goed op middelgrote en grote defecten. Het overtreft bovendien een verwant ontwerp dat een andere transformer (Swin) als backbone gebruikt, terwijl het minder parameters en iets minder rekencapaciteit vereist. Hoewel de transformer-backbone elke voorspelling langzamer maakt dan de lichtste YOLO-varianten, is de winst in nauwkeurigheid—vooral bij subtiele defecten in ruisachtige betontexturen—aanzienlijk.
Veiliger bouwsels door scherper digitaal zicht
In praktische zin laat dit onderzoek zien dat het koppelen van een pyramid vision transformer aan een moderne detector zoals YOLO AI veel beter kan maken in het opsporen van kleine gebreken zonder ingenieurs te overspoelen met valse meldingen. Het model zet ruwe, rommelige inspectiefoto’s om in multischaal, globaal geïnformeerde representaties die scheuren, roest en afbrokkeling op verschillende schalen benadrukken. Met verbeterde datavoorbewerking en synthetische trainingsbeelden leert het echte defecten te onderscheiden van onschuldige oppervlakpatronen. Hoewel er nog steeds een afweging bestaat tussen snelheid en nauwkeurigheid, brengt deze aanpak geautomatiseerde inspectie dichter bij betrouwbaar gebruik in de praktijk—en biedt zo scherpere digitale ogen om kostbare en gevaarlijke falen in onze gebouwde omgeving te helpen voorkomen.
Bronvermelding: Baek, JW., Suh, D. & Chung, K. Multiscale object detection model based on pyramid vision transformer. Sci Rep 16, 13307 (2026). https://doi.org/10.1038/s41598-026-43522-8
Trefwoorden: detectie van betondefecten, pyramid vision transformer, YOLO objectdetectie, multischaal visie, infrastructuurveiligheid