Clear Sky Science · ja
ピラミッド・ビジョントランスフォーマに基づくマルチスケール物体検出モデル
なぜ小さなひび割れが重要なのか
橋やトンネル、高層マンションに至るまで、多くの現代建造物はコンクリートで作られています。そのコンクリートにできた小さなひびや隠れた欠陥は、やがて陥没、落下物、あるいは崩壊につながる可能性があります。検査は依然として人間の目に大きく依存しており、時間がかかりコストも高く、小さく危険な欠陥を見逃すことがあります。本論文は、様々な大きさのコンクリート欠陥をより正確に検出することを目指した新しい人工知能(AI)システムを提示し、建物やインフラの安全性向上に寄与します。
多尺度で欠陥を見る
核心的な課題は、欠陥が一つの都合のよいサイズに収まらないことです。幅のある割れはカメラやアルゴリズムで捉えやすい一方、毛髪ほどの亀裂や小さな錆の斑点は同じくらい重要でありながら検出がはるかに難しいことがあります。従来の物体検出システム、たとえば広く使われてきたYOLO系の旧バージョンは、大きく明瞭な対象には強いものの、小さく重なり合ったり薄い対象には苦戦しがちです。これは建設、製造、医療現場などで見逃しが人命や安全に直結するため特に危険です。著者らは、単一の画像内で大きな問題も小さな問題も見分けられ、かつ現場で使える速度を損なわない検出器を構築することを目指しています。 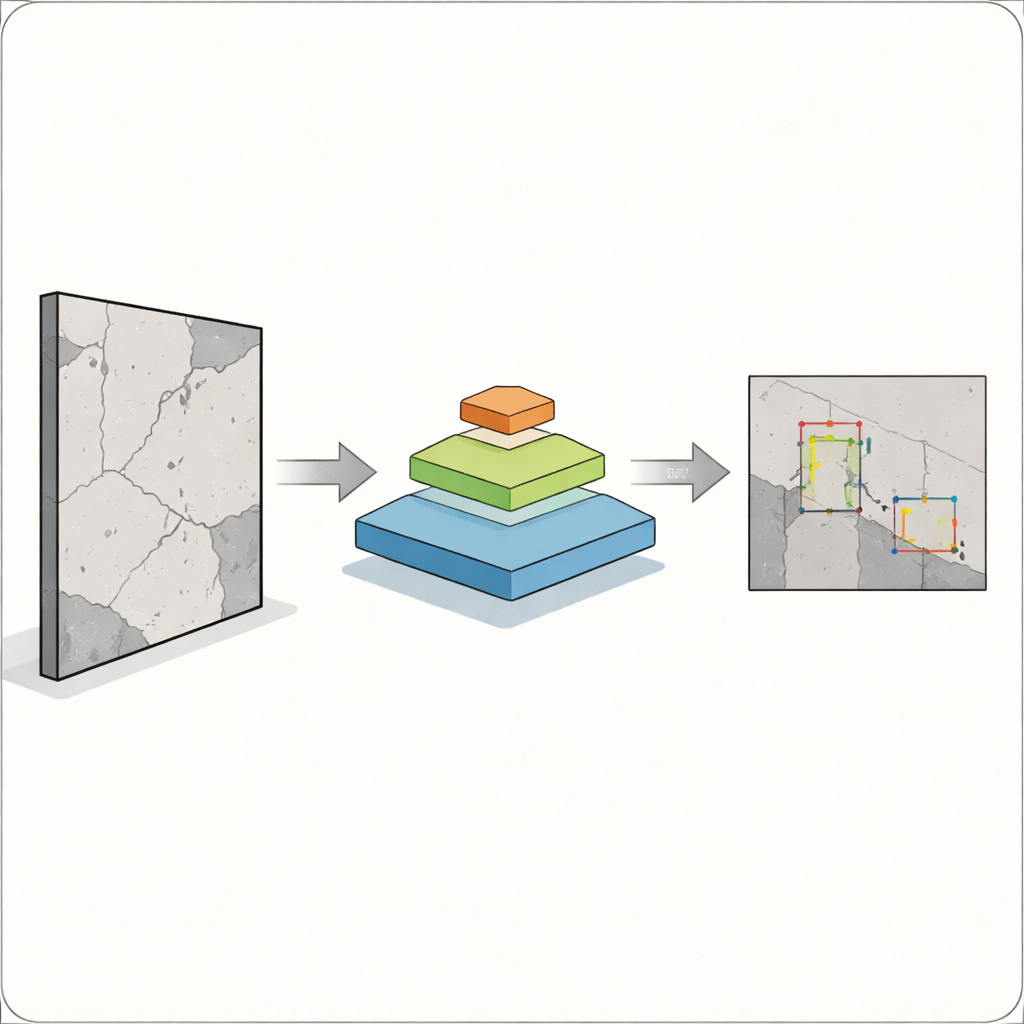
高速なビジョンと賢いピラミッドの融合
これを実現するために、研究者たちは二つの強力なアイデアを融合させます。視覚特徴を物体の周りのバウンディングボックスに変換するのが得意な最新のYOLOv12の「検出ヘッド」を維持し、その従来のバックボーンをピラミッド・ビジョン・トランスフォーマに置き換えます。このトランスフォーマは、小さな画素近傍だけを走査する代わりに、自己注意(self-attention)という過程を通じて画像全体を見渡し、遠く離れた領域同士の関係を学習します。同時に粗い俯瞰から細部へと異なる解像度の特徴マップのピラミッドを構築するため、小さな亀裂も大きな損傷も一緒に表現できます。こうして得られたマルチスケールの特徴マップはYOLOv12に供給され、欠陥の位置と種類を判定します。
学習画像のクリーンアップと強化
巧妙なモデルには、それに見合った巧妙な学習データが必要です。実際のコンクリート写真は影、むらのある照明、荒い質感で雑多になり、欠陥を隠してしまいます。著者らは、生画像から欠陥の明瞭な「マスク」を切り出すための8段階の前処理パイプラインを設計しました。画像をグレースケールに変換し、ノイズを除去し、局所的にコントラストを強調して薄い亀裂を浮かび上がらせ、明暗を反転させて欠陥を目立たせ、形状に基づく操作で途切れた亀裂断片を接続し、真の損傷でない小さな斑点を除去します。その結果、各欠陥のきれいな輪郭が得られます。
現実的な合成欠陥の作成
危険な欠陥は健全な表面よりも稀であるため、学習データは不均衡になりがちで、モデルは「欠陥なし」が妥当だと学習してしまうかもしれません。これを是正するために、チームは単独の欠陥マスクのライブラリを構築し、これをきれいなコンクリート背景にランダムな位置、角度、サイズで貼り付けます。単純な切り貼りではなく、エッジを自然に馴染ませるスムーズなブレンディングを用いることで、欠陥の境界が新しい表面と自然に溶け込むようにしています。これにより、実際のひび割れ、錆、剥離などの外観を保ちながら、学習時にモデルが見る事例の多様性を大幅に増やす現実的な合成画像が生成されます。 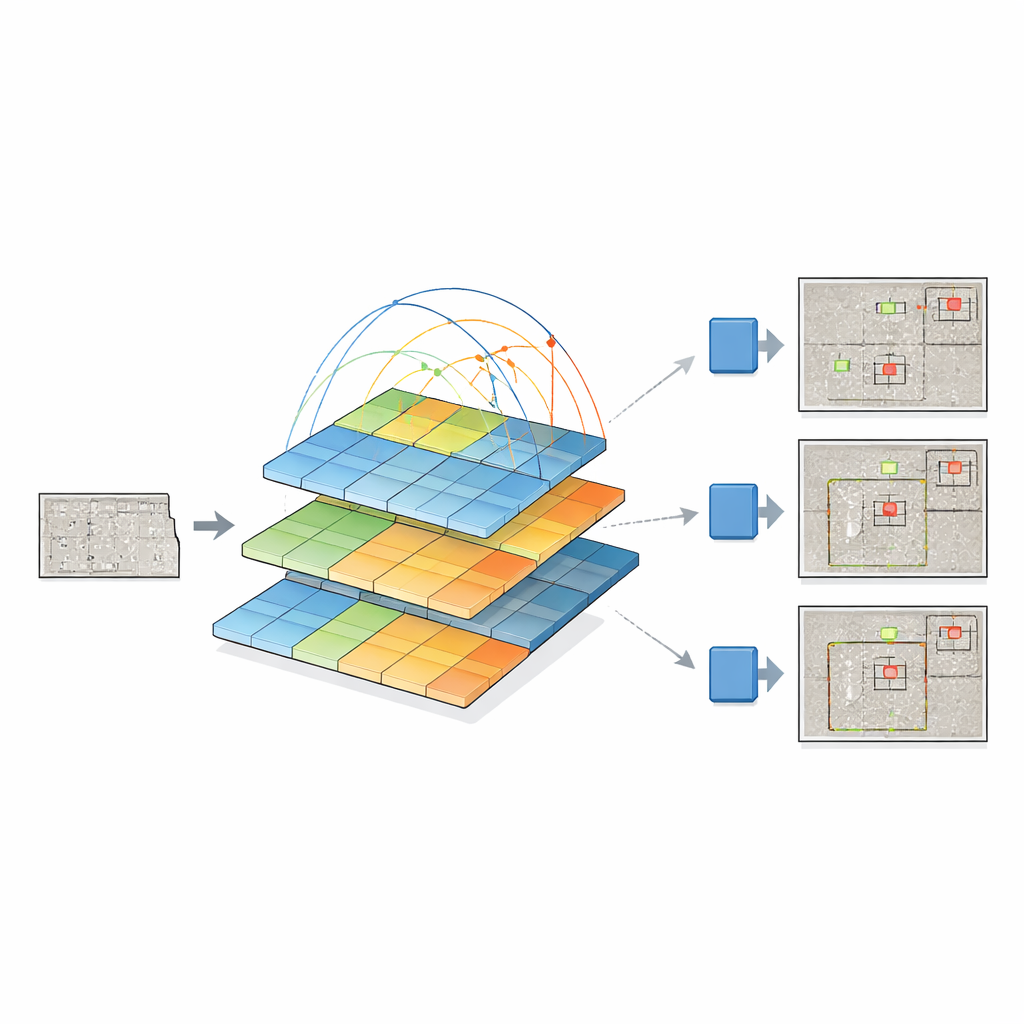
どれほどうまく機能するか?
著者らは、自らのピラミッド・トランスフォーマ+YOLOシステムを、古いYOLO系、Faster R-CNNのような古典的二段階モデル、DETRやDINOといった最近のトランスフォーマベースの設計など、複数の検出器群と徹底的に比較しました。彼らのモデルは、小さな欠陥の検出を一貫して改善しており、安全性の観点で最も重要な領域で優れた性能を示しています。中〜大サイズの欠陥でも競争力があり、別のトランスフォーマ(Swin)をバックボーンに用いる類似設計よりも少ないパラメータ数と若干少ない計算量で上回っています。トランスフォーマバックボーンにより最も軽量なYOLOバリアントよりも予測は遅くなる一方で、特にノイズの多いコンクリート質感中の微妙な欠陥に対する精度向上は著しいです。
より鋭いデジタルの目で安全な構造を
実務的に見れば、本研究はピラミッド・ビジョン・トランスフォーマをYOLOのような現代的検出器と組み合わせることで、誤検知に悩まされることなく微細な欠陥を検出する能力が大幅に向上することを示しています。モデルは生の雑然とした検査写真をマルチスケールかつ全体を考慮した表現に変換し、さまざまなサイズのひび、錆、剥離を浮かび上がらせます。改良されたデータ準備と合成学習画像によって、実際の欠陥と無害な表面模様を区別することを学習します。速度と精度のトレードオフは残るものの、このアプローチは自動検査を信頼できる実用段階へと近づけ、我々の構築環境における高価で危険な故障を防ぐためのより鋭いデジタルの目を提供します。
引用: Baek, JW., Suh, D. & Chung, K. Multiscale object detection model based on pyramid vision transformer. Sci Rep 16, 13307 (2026). https://doi.org/10.1038/s41598-026-43522-8
キーワード: コンクリート欠陥検出, ピラミッド・ビジョン・トランスフォーマ, YOLO物体検出, マルチスケールビジョン, インフラ安全性