Clear Sky Science · zh
用于多模态情感理解的粒度引导融合
为什么线上讽刺对机器很难识别
讽刺在网络上随处可见:一张阳光沙滩的照片却配着“今天天气糟透了”,或者一张咧嘴自拍下写着“我就是喜欢交通堵塞”。人类能立刻捕捉到这种笑点,因为我们能感知图像与文字之间的不一致。相比之下,计算机在处理这种双重含义时就很吃力,尤其是帖子同时混合图片、文字和隐含的文化线索时。本文提出了一种新的人工智能模型,以更层次化的方式观察社交媒体帖子,帮助机器注意到细微的矛盾,从而更好地判断何时存在讽刺。
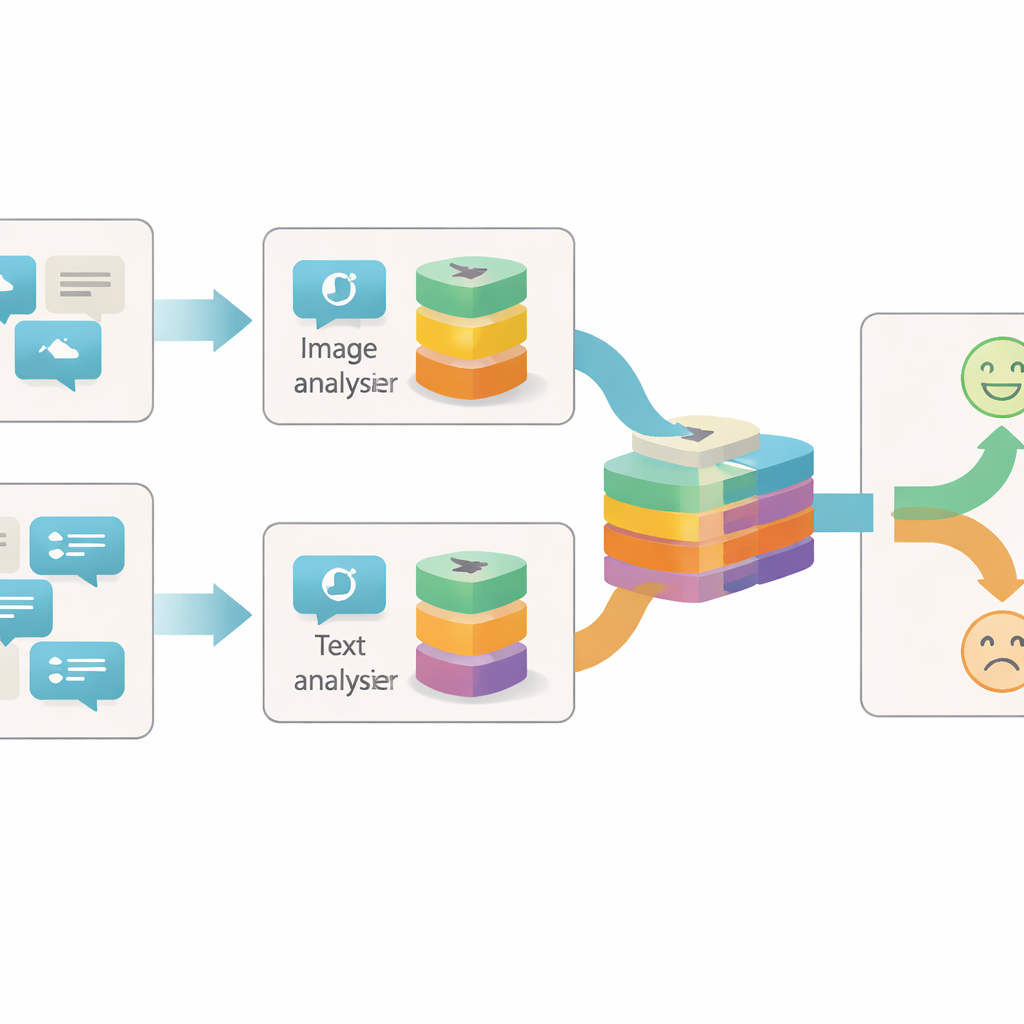
从多个角度观察帖子
以往大多数用于识别线上讽刺的系统要么只关注文本,要么只做文本与图像的简单组合。它们常常把每张图片或每句话当作单一的信息块,仅仅考察两块信息是否一致或相悖。作者认为这太粗糙:在同一张图片或一句话内部,可能存在许多独立的线索,揭示帖子真实情感的细节。例如,一张明亮欢快的照片可能与阴郁的文字相冲突,或者一张中性照片只有在配上特定短语时才显得讽刺。要捕捉这些细微差别,模型需要在每个内容片段内部以不同的细节层次进行观察。
把意义拆成更小的片段
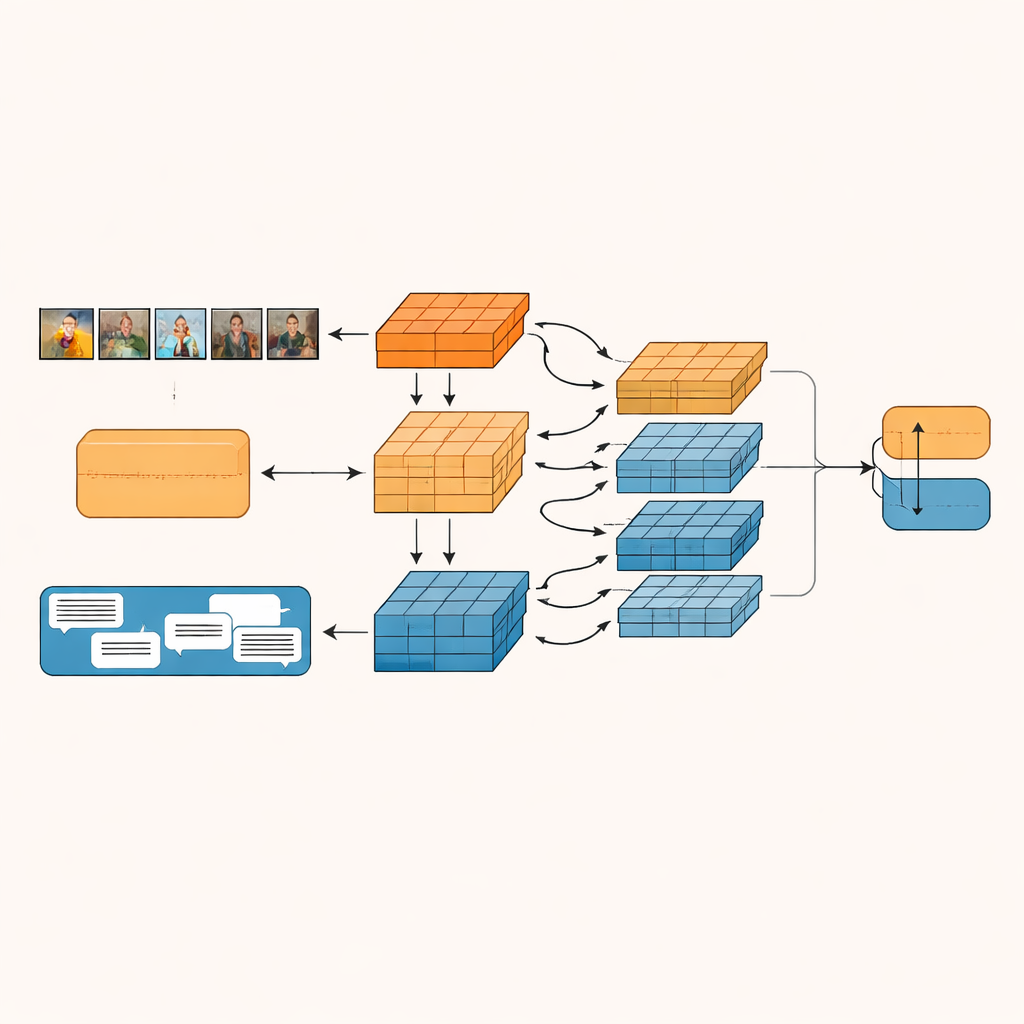
所提出的系统称为基于粒度的模态内与模态间融合网络(Granularity-based Intra-modal and Inter-modal Fusion Network,GIIFN),它从使用强大的预训练工具开始:用视觉变换器理解图像,用语言模型理解文本。它还通过对图像运行自动描述生成工具引入第三类信息,产生一段短描述,作为关于图像所示内容的外部“常识”。模型并不把得到的特征向量当作单一整体,而是用一个特殊模块将它们分割成多个“粒度”——若干自动学习出来的特征组。这个可学习的分组决定了表示中哪些部分应被归为一类,形成可突出诸如对象、情绪或关系等小语义单元。
让图像与文字相互交流
一旦这些语义单元形成,GIIFN 便通过结构化的三步过程让它们相互作用。首先,模型对图像自身进行精化,结合粗略的整体印象与细致的视觉信息。接着,它把精化后的图像单元与文本单元结合,使用双向注意力机制:图像单元“看”文本单元,文本单元也“看”图像单元。这种相互交换有助于系统捕捉矛盾,比如暴风雨的天空与轻松欢快的文字并存。在最后一步,模型引入信息丰富的图像描述单元,深化对场景中发生内容以及这些内容与文字信息之间关系的理解。
在真实数据上测试模型
为了检验这些额外的分析层是否真正有效,研究者在一个广泛使用的推特数据集上测试了 GIIFN,该数据集包含带文本和图像的帖子,并标注了是否带讽刺。他们将系统与多种现有方法进行了比较,包括已经使用图结构、注意力或外部知识的强基线模型。GIIFN 在准确率和 F1 分数等标准指标上取得了最佳成绩,并且在不同的随机训练—测试划分中表现稳定。通过消融实验(移除系统的个别部分)表明,可学习的粒度分组带来了最大的性能提升,而细粒度图像信息和三阶段融合也带来了显著的增益。
这对理解网络情绪意味着什么
通俗地说,这项工作表明,通过将帖子拆分成更小且有意义的片段,并让图像、文字与背景知识相互影响,机器可以更好地“读懂潜台词”。GIIFN 的分层设计使算法更容易识别帖子表面含义与潜在意图之间的冲突,这是讽刺的典型特征。除了识别笑话与讥讽之外,同样的思路还可帮助未来系统更可靠地解读在线情感,改进内容审核、谣言检测与心理健康监测等工具,同时适应现代社交平台上丰富且混合的媒体形式。
引用: Chen, M., Tang, H., Sun, C. et al. Granularity-guided fusion for multi-modal sentiment understanding. Sci Rep 16, 13286 (2026). https://doi.org/10.1038/s41598-026-43363-5
关键词: 讽刺检测, 多模态情感, 社交媒体分析, 深度学习, 视觉-语言模型