Clear Sky Science · nl
Granularity-guided fusion for multi-modal sentiment understanding
Waarom online sarcasme moeilijk is voor machines
Sarcasme is overal online: een zonnige strandfoto met de tag “Verschrikkelijk weer vandaag,” of een grijnzende selfie met “Ik hou echt van files.” Mensen vangen de grap meteen omdat we het contrast voelen tussen wat we zien en wat we lezen. Computers hebben daarentegen moeite met die dubbele betekenis, zeker wanneer berichten afbeeldingen, tekst en verborgen culturele aanwijzingen mengen. Dit artikel introduceert een nieuw kunstmatig-intelligentiemodel dat socialmedia-berichten op een meer gelaagde manier bekijkt, waardoor machines subtiele tegenstrijdigheden beter opmerken en begrijpen wanneer mensen sarcastisch zijn.
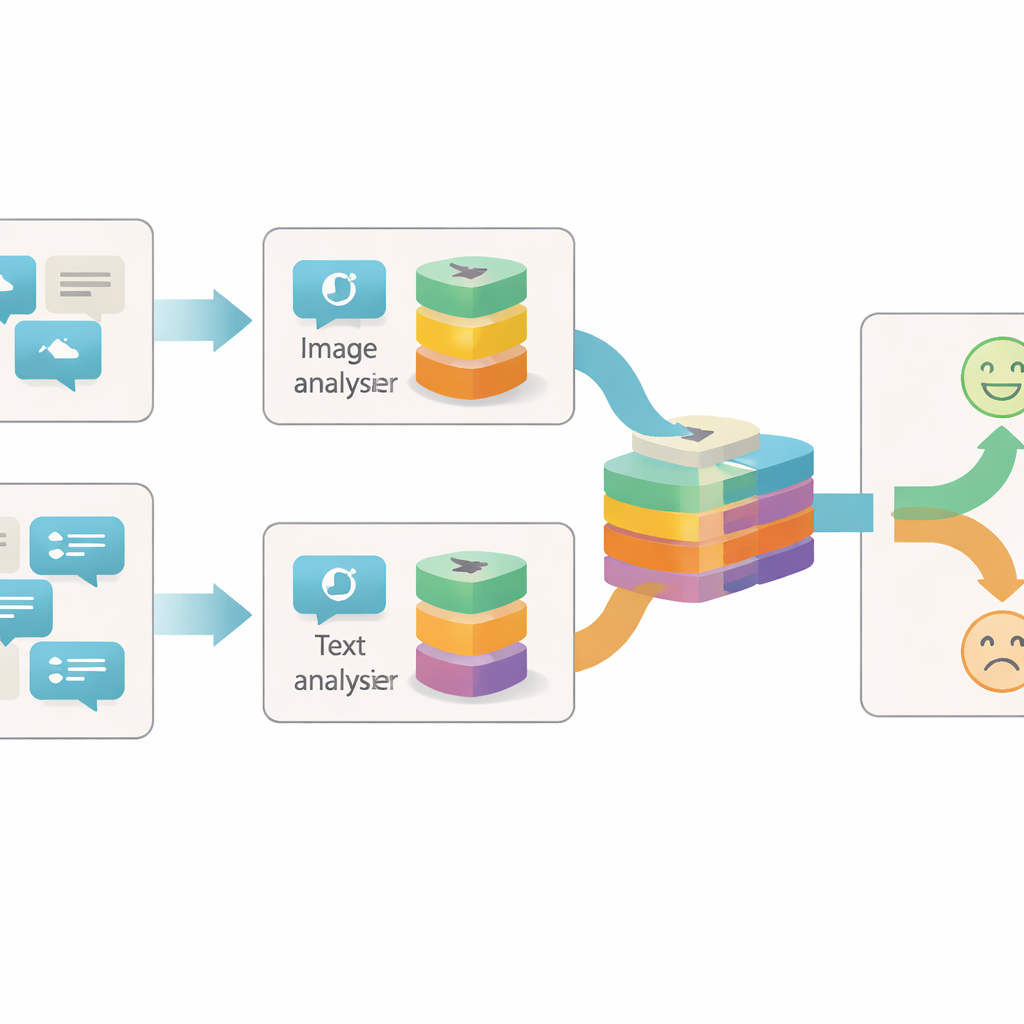
Berichten vanuit meerdere invalshoeken bekijken
De meeste eerdere systemen om online sarcasme te herkennen richtten zich op ofwel de tekst of op een eenvoudige combinatie van tekst en beeld. Ze behandelden vaak elke afbeelding of zin als één blok informatie en keken alleen of die twee blokken overeenkwamen of niet. De auteurs stellen dat dat te grof is: binnen een enkele afbeelding of zin kunnen veel afzonderlijke aanwijzingen zitten over het echte gevoel achter een bericht. Een heldere, vrolijke foto kan bijvoorbeeld botsen met sombere bewoordingen, of een neutrale foto kan alleen sarcastisch worden als hij met een bepaalde frase wordt gecombineerd. Om deze nuances vast te leggen, moet een model binnen elk inhoudsdeel op verschillende detailniveaus kijken.
Betekenis opdelen in kleine stukjes
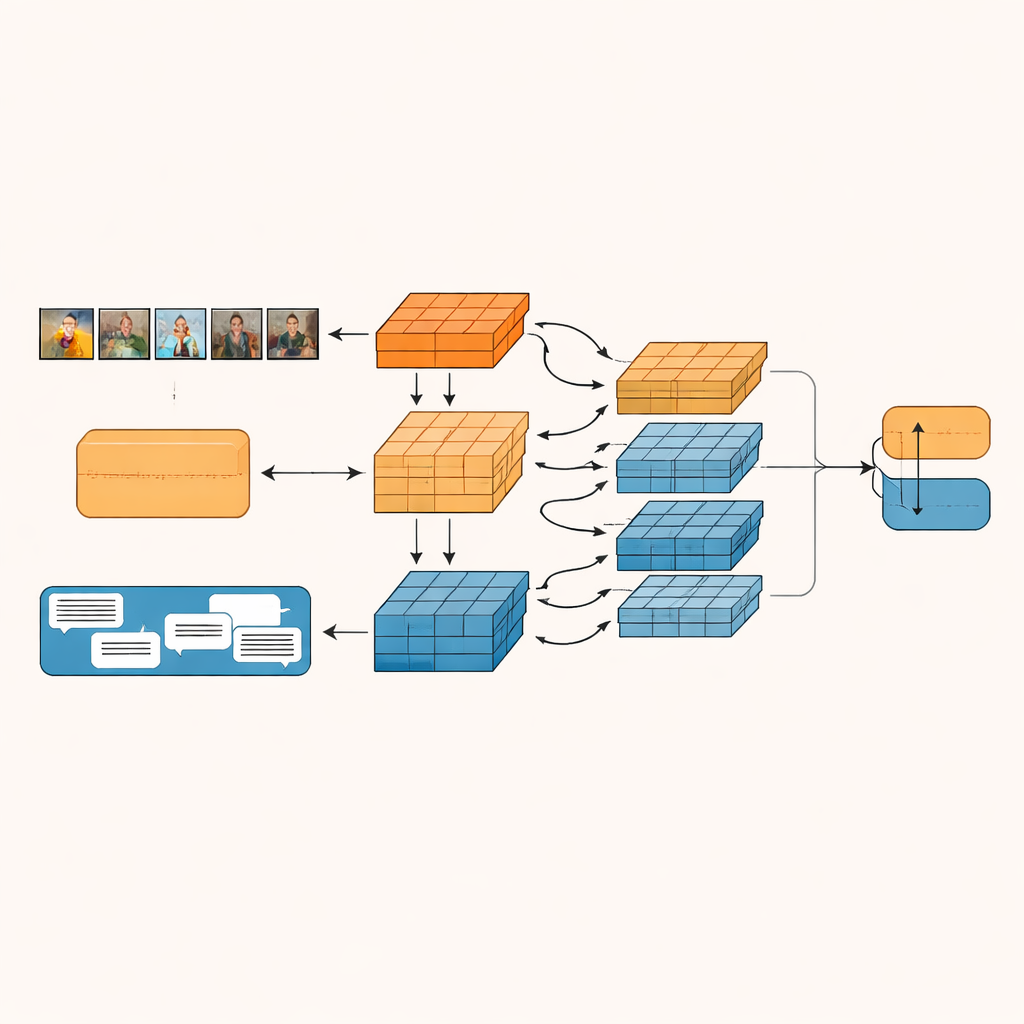
Het voorgestelde systeem, Granularity-based Intra-modal and Inter-modal Fusion Network (GIIFN), begint met krachtige voorgetrainde tools: een vision transformer om afbeeldingen te begrijpen en een taalmodel om tekst te begrijpen. Het voegt ook een derde informatiebron toe door automatisch ondertitelen van de afbeelding, wat een korte beschrijving oplevert die fungeert als externe “gezond verstand”-kennis over wat de foto toont. In plaats van de resulterende featurevectoren als één geheel te behandelen, gebruikt het model een speciaal module om ze in meerdere “granulariteiten” te splitsen — groepen features die automatisch worden geleerd. Deze leerbare groepering bepaalt welke delen van de representatie bij elkaar horen en vormt kleine semantische eenheden die bijvoorbeeld objecten, stemmingen of relaties binnen de inhoud kunnen benadrukken.
Afbeeldingen en woorden met elkaar laten praten
Zodra deze semantische eenheden gevormd zijn, laat GIIFN ze op een gestructureerde, drieledige manier interageren. Eerst verfijnt het wat het alleen over de afbeelding weet, door grove algemene indrukken te combineren met fijne visuele details. Vervolgens brengt het de verfijnde afbeeldingsdelen samen met de tekstdelen, met behulp van een bidirectioneel attentiemechanisme: beeld-eenheden “kijken naar” teksteenheden en teksteenheden “kijken naar” beeld-eenheden. Deze wederzijdse uitwisseling helpt het systeem tegenstrijdigheden op te pikken, zoals een stormachtige lucht gepaard met een vrolijke uitspraak. In de laatste stap voegt het model de kennisrijke afbeeldingsonderschriften samen, waardoor het begrip van wat er in de scène gebeurt en hoe dat zich verhoudt tot de geschreven boodschap verdiept.
Het model in de praktijk testen
Om te onderzoeken of deze extra analysetrappen echt helpen, testten de onderzoekers GIIFN op een veelgebruikt Twitter-dataset van berichten gelabeld als sarcastisch of niet, elk met zowel tekst als afbeelding. Ze vergeleken hun systeem met vele bestaande methoden, inclusief sterke modellen die al gebruikmaken van grafen, attentie of externe kennis. GIIFN behaalde de beste scores over standaardmaten zoals nauwkeurigheid en F1-score, en de resultaten waren consistent over verschillende willekeurige train–test-splits. Zorgvuldige ablatietests, waarbij afzonderlijke onderdelen van het systeem werden verwijderd, toonden aan dat de leerbare granulariteitsgroepering de grootste prestatieverbetering opleverde, terwijl de fijnmazige beelddetails en de drie-staps fusie ook betekenisvolle winst toevoegden.
Wat dit betekent voor het begrijpen van online emotie
In gewone bewoordingen laat dit werk zien dat machines beter “tussen de regels door kunnen lezen” door berichten op te delen in kleinere, betekenisvolle stukken en afbeeldingen, woorden en achtergrondkennis elkaar te laten beïnvloeden. Het gelaagde ontwerp van GIIFN maakt het voor een algoritme makkelijker te detecteren wanneer de oppervlakkige betekenis van een bericht botst met de onderliggende intentie, een kenmerk van sarcasme. Buiten het herkennen van grappen en sarcasme kunnen dezelfde ideeën toekomstige systemen helpen online sentiment betrouwbaarder te interpreteren, wat gereedschappen voor contentmoderatie, geruchtendetectie en mentale-gezondheidbewaking kan verbeteren, terwijl ze omgaan met de rijke, multimediaale aard van moderne sociale platforms.
Bronvermelding: Chen, M., Tang, H., Sun, C. et al. Granularity-guided fusion for multi-modal sentiment understanding. Sci Rep 16, 13286 (2026). https://doi.org/10.1038/s41598-026-43363-5
Trefwoorden: sarcasm detection, multimodal sentiment, social media analysis, deep learning, vision-language models