Clear Sky Science · pt
Fusão guiada por granularidade para compreensão multimodal de sentimento
Por que o sarcasmo online é difícil para máquinas
O sarcasmo está em toda parte online: uma foto de praia ensolarada marcada com “Que tempo terrível hoje”, ou uma selfie sorridente com a legenda “Adoro engarrafamentos.” Humanos captam a piada instantaneamente porque percebemos a discrepância entre o que vemos e o que lemos. Computadores, no entanto, têm dificuldade com esse duplo sentido, especialmente quando publicações misturam imagens, texto e pistas culturais implícitas. Este artigo apresenta um novo modelo de inteligência artificial que analisa postagens em redes sociais de forma mais estratificada, ajudando máquinas a notar contradições sutis e a entender melhor quando as pessoas estão sendo sarcásticas.
Olhando para publicações por mais de um ângulo
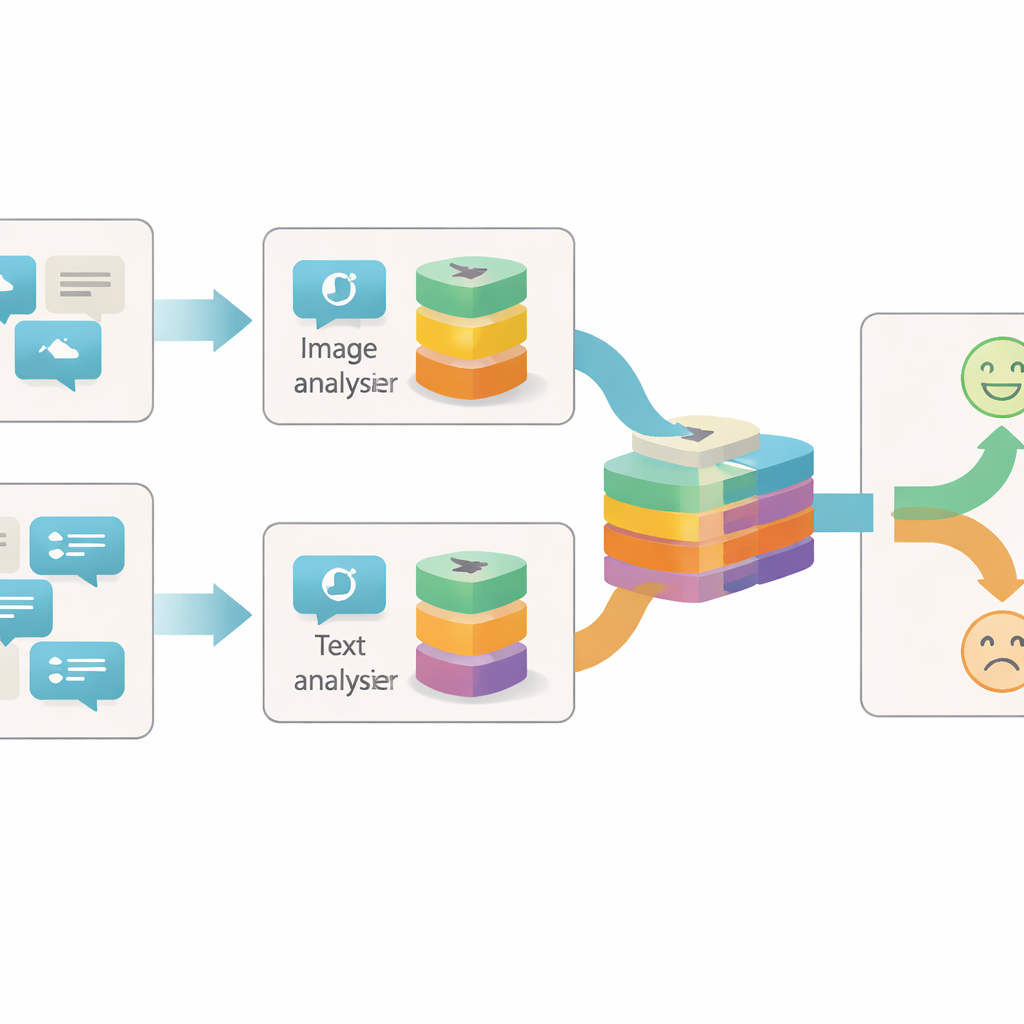
A maioria dos sistemas anteriores para identificar sarcasmo online focava ou no texto ou em uma combinação simples de texto e imagem. Eles frequentemente tratavam cada imagem ou frase como um único bloco de informação e analisavam apenas se os dois blocos concordavam ou discordavam. Os autores argumentam que isso é muito grosseiro: dentro de uma única imagem ou sentença pode haver muitas pistas separadas sobre o sentimento real por trás de uma postagem. Por exemplo, uma foto brilhante e alegre pode entrar em choque com uma redação sombria, ou uma foto neutra pode se tornar sarcástica apenas quando pareada com certa frase. Para capturar essas nuances, um modelo precisa observar cada peça de conteúdo em diferentes níveis de detalhe.
Quebrando o significado em pequenas partes
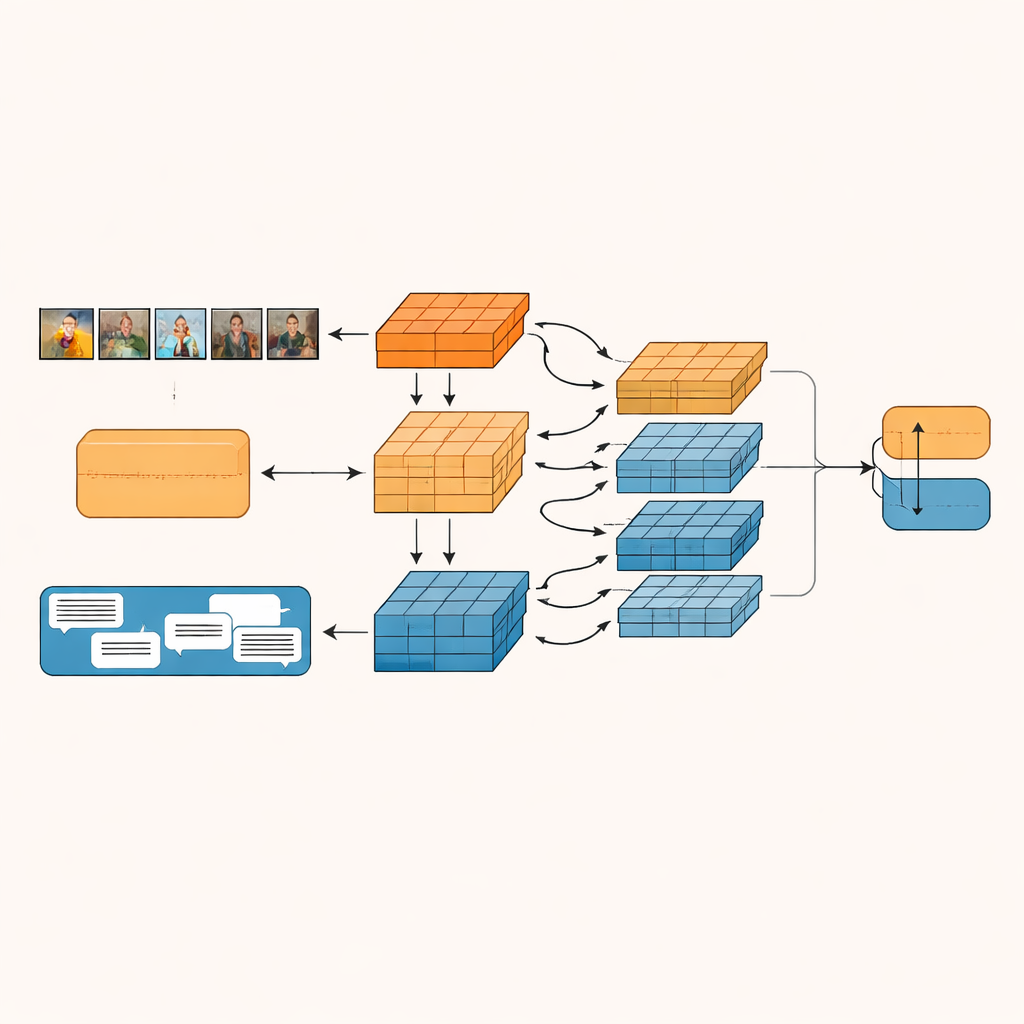
O sistema proposto, chamado Rede de Fusão Intra-modal e Inter-modal com Base em Granularidade (GIIFN), começa usando ferramentas pré-treinadas poderosas: um transformador visual para entender imagens e um modelo de linguagem para entender o texto. Ele também adiciona uma terceira fonte de informação ao executar uma ferramenta automática de legenda na imagem, criando uma descrição curta que age como um “senso comum” externo sobre o que a imagem mostra. Em vez de tratar os vetores de características resultantes como um único bloco, o modelo usa um módulo especial para dividi-los em múltiplas “granularidades” — grupos de características aprendidos automaticamente. Essa agrupamento aprendível decide quais partes da representação pertencem juntas, formando pequenas unidades semânticas que podem destacar, por exemplo, objetos, estados de ânimo ou relacionamentos dentro do conteúdo.
Deixando imagens e palavras conversarem entre si
Uma vez formadas essas unidades semânticas, o GIIFN permite que elas interajam em um processo estruturado de três etapas. Primeiro, ele refina o que sabe apenas sobre a imagem, combinando impressões gerais e mais grosseiras com detalhes visuais finos. Em seguida, reúne as peças refinadas da imagem com as peças do texto, usando um mecanismo de atenção bidirecional: unidades de imagem “olham” para unidades de texto e unidades de texto “olham” para unidades de imagem. Essa troca mútua ajuda o sistema a identificar contradições, como um céu tempestuoso pareado com uma frase alegre. Na etapa final, o modelo incorpora as unidades de legenda de imagem ricas em conhecimento, aprofundando sua compreensão do que ocorre na cena e de como isso se relaciona com a mensagem escrita.
Testando o modelo em ambiente real
Para verificar se essas camadas extras de análise realmente ajudam, os pesquisadores testaram o GIIFN em um conjunto de dados amplamente usado do Twitter com postagens rotuladas como sarcásticas ou não, cada uma contendo texto e imagem. Eles compararam seu sistema com muitos métodos existentes, incluindo modelos fortes que já usam grafos, atenção ou conhecimento externo. O GIIFN alcançou as melhores pontuações em medidas padrão, como acurácia e F1-score, e seus resultados foram consistentes em diferentes divisões aleatórias de treinamento e teste. Testes de ablação cuidadosos, em que partes individuais do sistema foram removidas, mostraram que o agrupamento aprendível por granularidade trouxe o maior ganho de desempenho, enquanto os detalhes visuais de alta resolução e a fusão em três estágios também adicionaram ganhos significativos.
O que isso significa para compreender emoções online
Em termos práticos, este trabalho mostra que máquinas podem melhorar em “ler nas entrelinhas” ao dividir postagens em pedaços menores e significativos e permitir que imagens, palavras e conhecimento de fundo influenciem-se mutuamente. O design em camadas do GIIFN facilita que um algoritmo detecte quando o significado superficial de uma postagem entra em choque com sua intenção subjacente, marca registrada do sarcasmo. Além de identificar piadas e ironias, as mesmas ideias podem ajudar sistemas futuros a interpretar o sentimento online de forma mais confiável, melhorando ferramentas para moderação de conteúdo, detecção de boatos e monitoramento da saúde mental, tudo isso lidando com a natureza rica e multimídia das plataformas sociais modernas.
Citação: Chen, M., Tang, H., Sun, C. et al. Granularity-guided fusion for multi-modal sentiment understanding. Sci Rep 16, 13286 (2026). https://doi.org/10.1038/s41598-026-43363-5
Palavras-chave: detecção de sarcasmo, sentimento multimodal, análise de mídia social, aprendizado profundo, modelos visão-linguagem