Clear Sky Science · pl
Fuzja kierowana ziarnistością dla wielomodalnego rozumienia sentymentu
Dlaczego sarkazm w internecie jest trudny dla maszyn
Sarkazm jest wszędzie w sieci: zdjęcie słonecznej plaży podpisane „Okropna pogoda dziś” albo szeroko uśmiechnięte selfie z dopiskiem „Uwielbiam korki”. Ludzie od razu wychwytują żart, bo wyczuwamy rozbieżność między tym, co widzimy, a tym, co czytamy. Komputery natomiast mają problem z takimi podwójnymi znaczeniami, zwłaszcza gdy posty łączą obraz, tekst i ukryte kulturowe wskazówki. W artykule przedstawiono nowy model sztucznej inteligencji, który analizuje posty z mediów społecznościowych w sposób wielowarstwowy, pomagając maszynom zauważać subtelne sprzeczności i lepiej rozumieć, kiedy ktoś jest sarkastyczny.
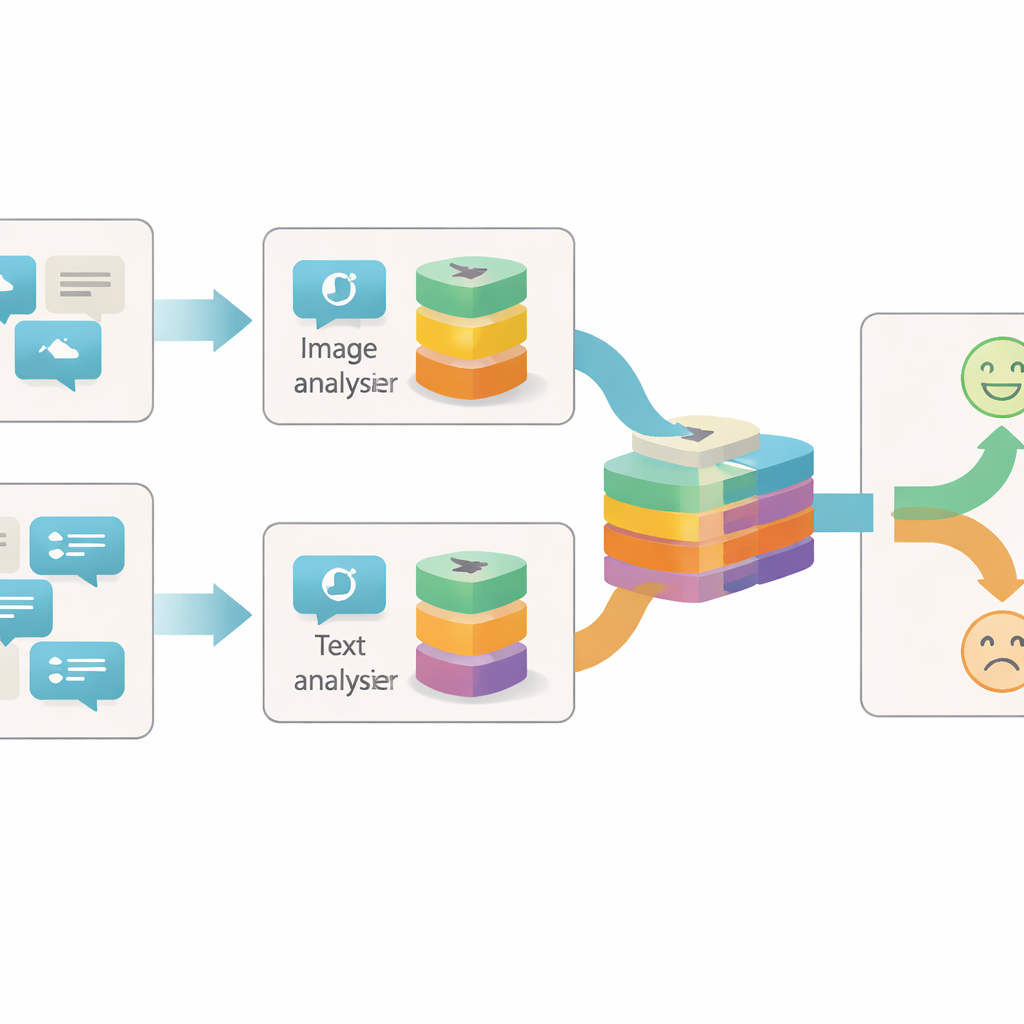
Patrzenie na posty z więcej niż jednej perspektywy
Większość wcześniejszych systemów wykrywających sarkazm online skupiała się albo na tekście, albo na prostym połączeniu tekstu i obrazu. Często traktowały każde zdjęcie czy zdanie jako pojedynczy blok informacji i sprawdzały jedynie, czy bloki te się zgadzają lub nie. Autorzy argumentują, że to zbyt gruboziarniste podejście: w obrębie jednego obrazu czy zdania może być wiele oddzielnych wskazówek dotyczących rzeczywistego nastroju stojącego za postem. Na przykład jasne, pogodowe zdjęcie może kolidować z ponurym tekstem, albo neutralne zdjęcie nabierać sarkastycznego sensu tylko w połączeniu z określonym zwrotem. Aby wychwycić te niuanse, model musi przyjrzeć się każdemu elementowi treści na różnych poziomach szczegółu.
Rozbijanie znaczenia na drobne części
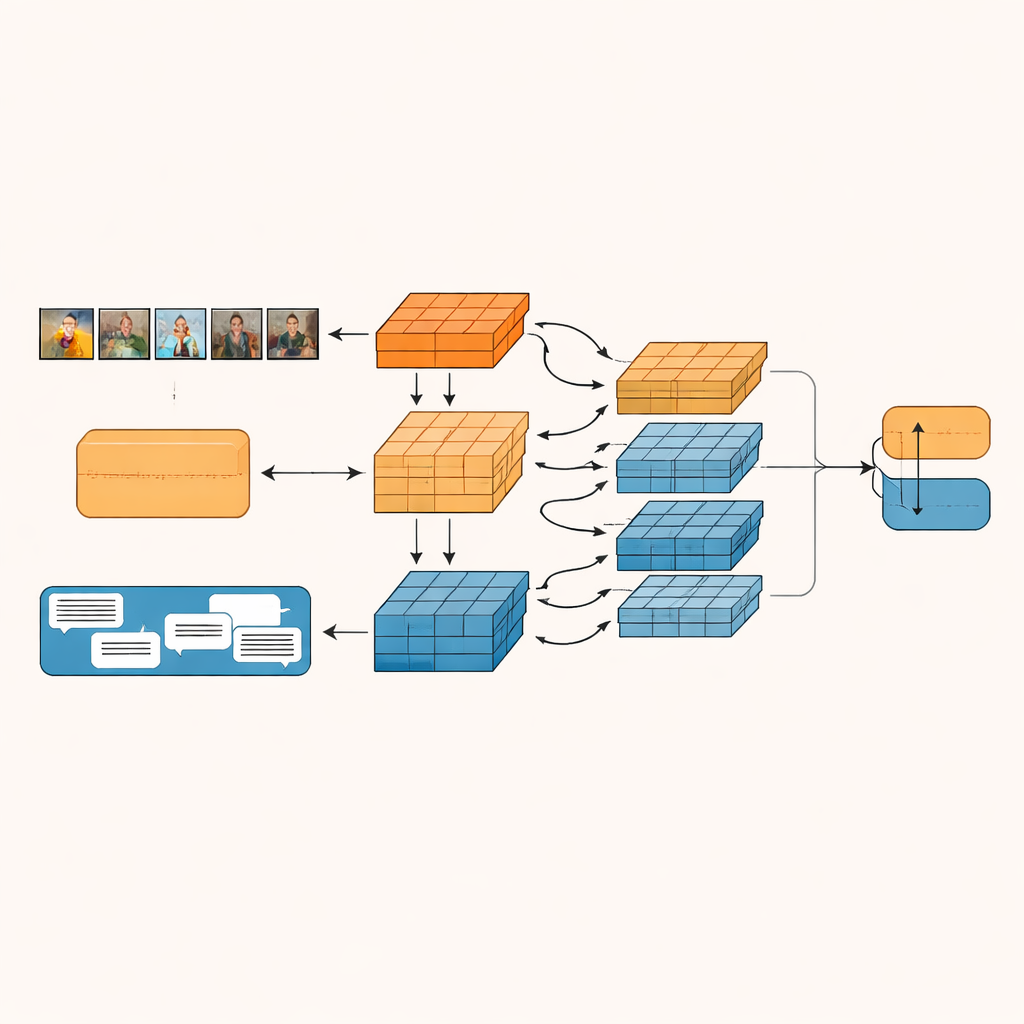
Proponowany system, nazwany Granularity-based Intra-modal and Inter-modal Fusion Network (GIIFN), zaczyna od wykorzystania potężnych, wstępnie wytrenowanych narzędzi: transformera wizji do rozumienia obrazów oraz modelu językowego do analizy tekstu. Dodaje też trzeci strumień informacji, uruchamiając automatyczny moduł opisywania obrazu, który tworzy krótki opis działający jak zewnętrzny „zdrowy rozsądek” dotyczący tego, co pokazuje zdjęcie. Zamiast traktować powstałe wektory cech jako jedną całość, model używa specjalnego modułu do podziału ich na wiele „ziarnistości” — grup cech uczonych automatycznie. Ta uczona grupizacja decyduje, które części reprezentacji należą do siebie, tworząc małe jednostki semantyczne, które mogą uwypuklać np. obiekty, nastroje czy relacje wewnątrz treści.
Pozwalanie, by obrazy i słowa ze sobą rozmawiały
Gdy te jednostki semantyczne zostaną utworzone, GIIFN pozwala im wchodzić w interakcję w uporządkowanym, trzyetapowym procesie. Najpierw dopracowuje informacje o samym obrazie, łącząc ogólne, grube wrażenia z drobnymi detalami wizualnymi. Następnie łączy dopracowane fragmenty obrazu z fragmentami tekstu, używając mechanizmu dwukierunkowej uwagi: jednostki obrazu „spoglądają” na jednostki tekstu, a jednostki tekstu „spoglądają” na jednostki obrazu. Wzajemna wymiana pomaga systemowi wychwycić sprzeczności, takie jak burzowe niebo zestawione z radosnym podpisem. W ostatnim kroku model integruje bogate w wiedzę jednostki podpisu obrazu, pogłębiając zrozumienie, co dzieje się na scenie i jak to odnosi się do przekazu pisanego.
Testowanie modelu w naturalnym środowisku
Aby sprawdzić, czy te dodatkowe warstwy analizy naprawdę pomagają, badacze przetestowali GIIFN na szeroko stosowanym zbiorze tweetów oznaczonych jako sarkastyczne lub nie, złożonych z tekstu i obrazu. Porównali swój system z wieloma istniejącymi metodami, w tym silnymi modelami wykorzystującymi grafy, mechanizmy uwagi czy wiedzę zewnętrzną. GIIFN osiągnął najlepsze wyniki w standardowych miarach, takich jak dokładność i F1, a jego rezultaty były spójne przy różnych losowych podziałach na zbiory treningowe i testowe. Dokładne testy ablacynjne, w których usuwano poszczególne elementy systemu, wykazały, że uczona grupizacja ziarnistości przyniosła największy wzrost wydajności, podczas gdy drobnoziarniste szczegóły obrazu i trzyetapowa fuzja również dodały istotne korzyści.
Co to oznacza dla rozumienia emocji online
W prostych słowach, praca ta pokazuje, że maszyny mogą lepiej „czytać między wierszami”, rozbijając posty na mniejsze, znaczące części i pozwalając, by obrazy, słowa i wiedza kontekstowa wzajemnie na siebie wpływały. Wielowarstwowa konstrukcja GIIFN ułatwia algorytmowi wykrycie, kiedy powierzchowne znaczenie posta koliduje z ukrytą intencją — cechą charakterystyczną sarkazmu. Poza wykrywaniem żartów i kąśliwych uwag, te same pomysły mogą pomóc przyszłym systemom bardziej niezawodnie interpretować sentyment online, ulepszając narzędzia do moderacji treści, wykrywania plotek czy monitorowania zdrowia psychicznego, jednocześnie radząc sobie z bogatą, mieszanym mediami naturą współczesnych platform społecznościowych.
Cytowanie: Chen, M., Tang, H., Sun, C. et al. Granularity-guided fusion for multi-modal sentiment understanding. Sci Rep 16, 13286 (2026). https://doi.org/10.1038/s41598-026-43363-5
Słowa kluczowe: wykrywanie sarkazmu, wielomodalny sentyment, analiza mediów społecznościowych, uczenie głębokie, modele wizja-język