Clear Sky Science · ru
Слияние, управляемое гранулярностью, для понимания мультимодальных настроений
Почему онлайн-сарказм сложен для машин
Сарказм повсюду в интернете: солнечное фото пляжа с подписью «Ужасная погода сегодня» или улыбающееся селфи с комментарием «Я так люблю пробки». Люди мгновенно понимают шутку, потому что чувствуют несоответствие между увиденным и прочитанным. Компьютерам же трудно уловить эту двойственность, особенно когда посты смешивают изображения, текст и скрытые культурные сигналы. В этой статье предложена новая модель искусственного интеллекта, которая рассматривает посты в социальных сетях более многоуровнево, помогая машинам замечать тонкие противоречия и лучше распознавать сарказм.
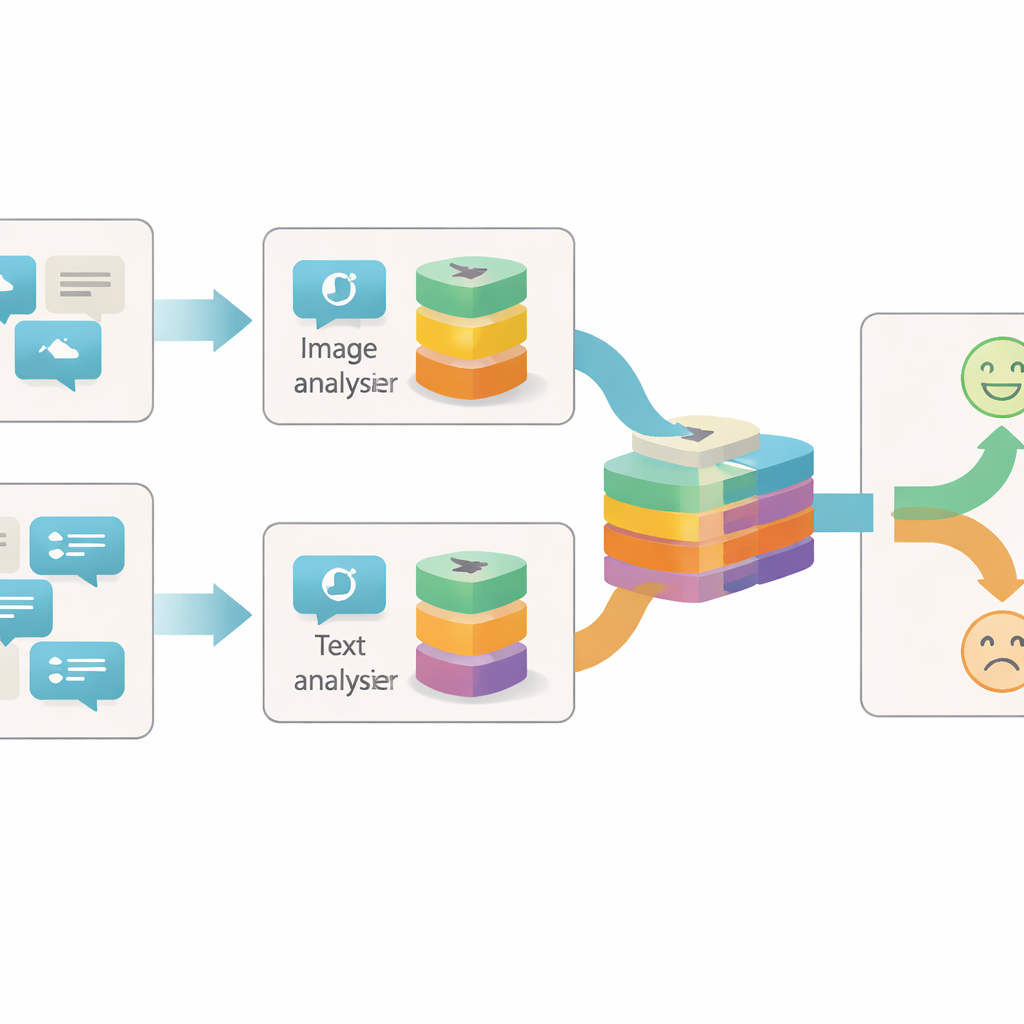
Рассматривать посты под разными углами
Большинство ранних систем для поиска сарказма в сети фокусировались либо на тексте, либо на простой комбинации текста и изображения. Часто они рассматривали каждую картинку или предложение как единый блок информации и проверяли только, насколько эти блоки согласуются или расходятся. Авторы утверждают, что это слишком грубо: внутри одного изображения или предложения может быть множество отдельных подсказок о реальном настрое поста. Например, яркая жизнерадостная фотография может вступать в конфликт с мрачной формулировкой, или нейтральная фотография становится саркастичной лишь в сочетании с определённой фразой. Чтобы зафиксировать эти нюансы, модель должна анализировать каждую часть контента на разных уровнях детализации.
Дробление смысла на мелкие части
Предложенная система, названная Сетью слияния внутри и между модальностями на основе гранулярности (GIIFN), начинает с использования мощных предварительно обученных инструментов: визуального трансформера для понимания изображений и языковой модели для обработки текста. Она также добавляет третий источник информации, запуская автоматический инструмент подписи изображения, который создаёт короткое описание — нечто вроде внешнего «здравого смысла» о том, что изображено. Вместо того чтобы рассматривать полученные векторы признаков как единое целое, модель использует специальный модуль для их разбиения на несколько «гранулярностей» — группы признаков, которые обучаются автоматически. Это обучаемое группирование решает, какие части представления принадлежат друг другу, формируя небольшие семантические единицы, которые могут выделять, например, объекты, настроения или отношения внутри контента.
Дать изображениям и словам возможность взаимодействовать
Когда эти семантические единицы сформированы, GIIFN даёт им взаимодействовать в структурированном трёхэтапном процессе. Сначала она уточняет знания только об изображении, сочетая грубые общие впечатления с тонкими визуальными деталями. Затем синтезирует уточнённые фрагменты изображения с фрагментами текста, используя двунаправленный механизм внимания: единицы изображения «смотрят» на единицы текста, а единицы текста — на единицы изображения. Этот взаимный обмен помогает системе замечать противоречия, например штормовое небо в паре с радостной фразой. На финальном этапе модель включает в обработку информативные единицы автогенерируемых подписей к изображению, углубляя понимание происходящего на сцене и того, как это соотносится с письменным сообщением.
Тестирование модели в реальных условиях
Чтобы проверить, действительно ли эти дополнительные слои анализа помогают, исследователи протестировали GIIFN на широко используемом наборе твитов, размеченных как саркастичные или нет, каждый из которых содержал и текст, и изображение. Они сравнили свою систему со многими существующими методами, включая сильные модели, уже использующие графы, механизмы внимания или внешние знания. GIIFN показала лучшие результаты по стандартным метрикам, таким как точность и F1-метрика, и её показатели были стабильны при разных случайных разбиениях на обучающую и тестовую выборки. Тщательные абляционные эксперименты, в которых поочерёдно убирали отдельные части системы, показали, что обучаемое группирование по гранулярности принесло наибольший прирост производительности, а тонкие визуальные детали и трёхступенчатое слияние также добавили значимые улучшения.
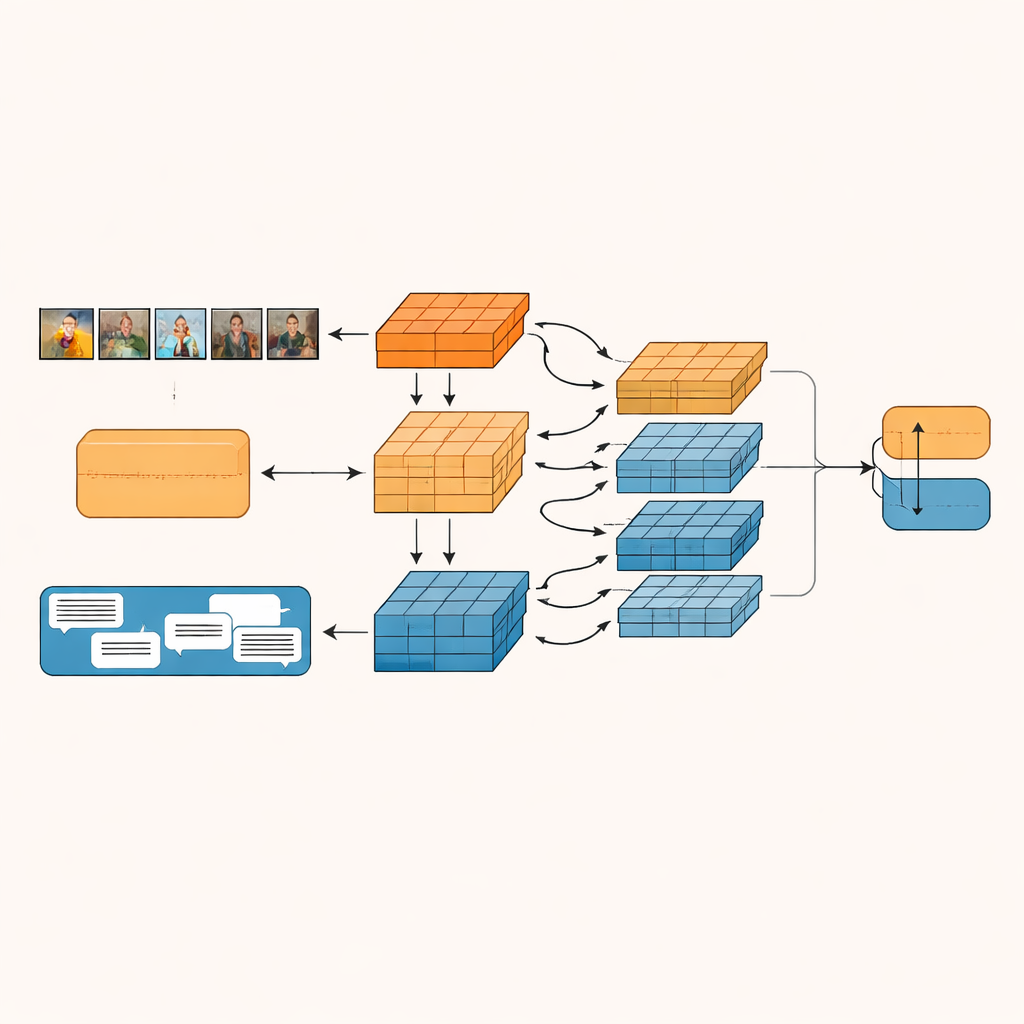
Что это значит для понимания онлайн-эмоций
Проще говоря, эта работа показывает, что машины могут лучше «читать между строк», разбивая посты на меньшие значимые части и позволяя изображениям, словам и фоновым знаниям влиять друг на друга. Слоистая архитектура GIIFN облегчает алгоритму обнаружение случаев, когда поверхностный смысл поста противоречит его скрытому намерению — признак сарказма. Помимо распознавания шуток и насмешек, те же идеи могут помочь будущим системам надёжнее интерпретировать онлайн-настроения, улучшая инструменты модерации контента, обнаружения слухов и мониторинга психического здоровья, при этом справляясь с богатой мультимедийной природой современных социальных платформ.
Цитирование: Chen, M., Tang, H., Sun, C. et al. Granularity-guided fusion for multi-modal sentiment understanding. Sci Rep 16, 13286 (2026). https://doi.org/10.1038/s41598-026-43363-5
Ключевые слова: обнаружение сарказма, мультимодальные настроения, анализ социальных сетей, глубокое обучение, модели зрения и языка