Clear Sky Science · tr
Çok modlu duygu anlayışı için granülerlik rehberli füzyon
Çevrimiçi iğnelemenin makineler için neden zor olduğu
İnternette iğneleme her yerde: “Bugün korkunç hava” etiketiyle paylaşılan güneşli bir plaj fotoğrafı veya “Trafik sıkıntılarını gerçekten çok seviyorum” diyen gülümseyen bir selfie. İnsanlar, gördükleri ile okudukları arasındaki uyumsuzluğu hissederek espriyi hemen kavrarlar. Ancak bilgisayarlar, özellikle gönderiler resim, metin ve gizli kültürel ipuçlarını karıştırdığında, bu çifte anlamla başa çıkmakta zorlanır. Bu makale, sosyal medya gönderimlerini daha katmanlı bir biçimde inceleyen yeni bir yapay zeka modeli sunar; böylece makineler ince çelişkileri fark eder ve insanların iğneleme yapıp yapmadığını daha iyi anlar.
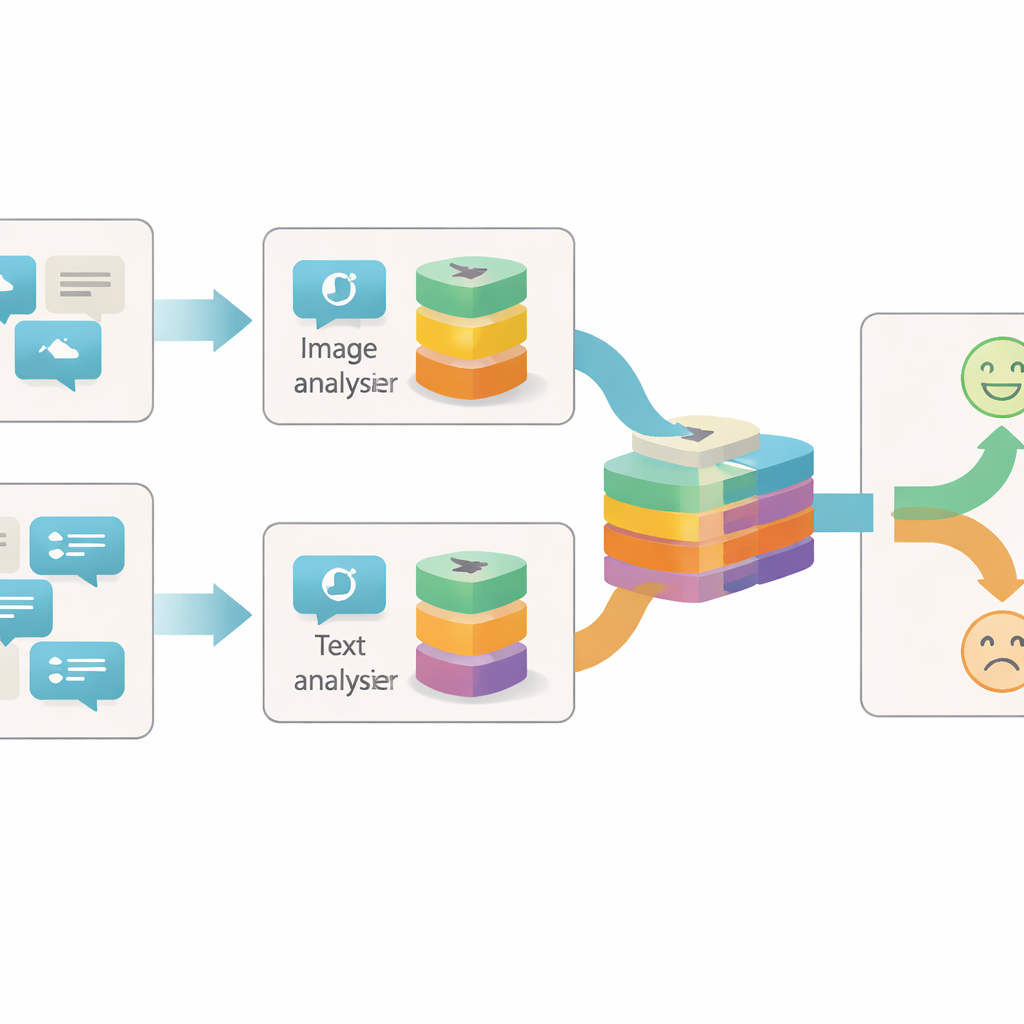
Gönderilere birden fazla açıdan bakmak
Çevrimiçi iğnelemeyi tespit etmeye yönelik önceki sistemlerin çoğu ya metne odaklandı ya da metin ile görüntünün basit bir birleşimini kullandı. Genellikle her resmi veya cümleyi tek bir bilgi bloğu olarak ele alıp yalnızca iki blok arasındaki uyum veya uyuşmazlığa baktılar. Yazarlar bunun çok kaba olduğunu savunuyor: tek bir görüntüde veya cümlede, gönderinin arkasındaki gerçek duyguyu gösteren birçok ayrı ipucu bulunabilir. Örneğin parlak, neşeli bir resim kasvetli bir ifadeyle çelişebilir ya da nötr bir fotoğraf yalnızca belirli bir ifadeyle eşleştirildiğinde iğneleyici hale gelebilir. Bu nüansları yakalamak için modelin her içerik parçasının içini farklı ayrıntı düzeylerinde incelemesi gerekir.
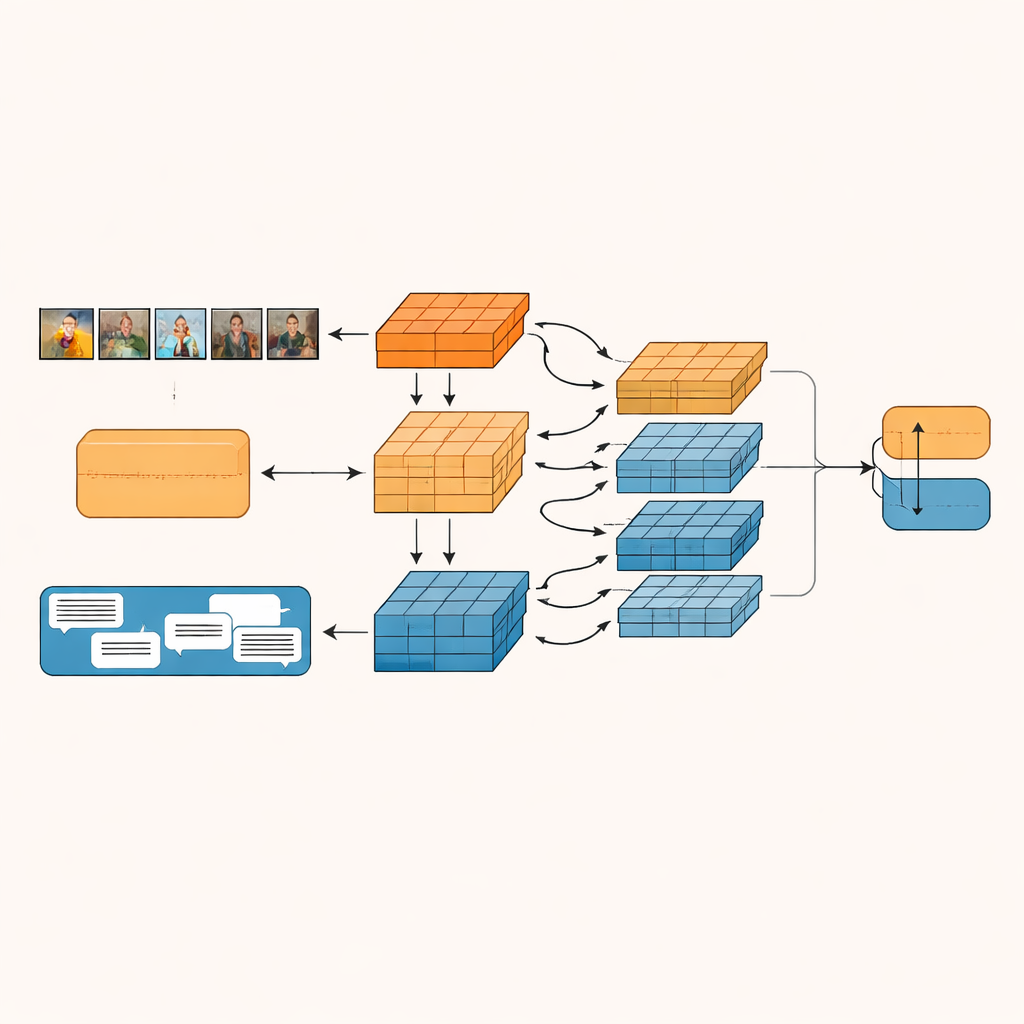
Anlamı küçük parçalara ayırmak
Önerilen sistem, Granularity-based Intra-modal and Inter-modal Fusion Network (GIIFN) adlı model, görüntüleri anlamak için bir vision transformer ve metni anlamak için bir dil modeli gibi güçlü önceden eğitilmiş araçları kullanmakla başlar. Ayrıca resim üzerinde otomatik bir altyazı oluşturma aracı çalıştırarak üçüncü bir bilgi kaynağı ekler; bu, resmin ne gösterdiğine dair dışsal bir “sağduyu” kısa tanımı olarak iş görür. Ortaya çıkan özellik vektörlerini tek bir yığın olarak ele almak yerine, model bunları birden çok "granülerlik"e — otomatik olarak öğrenilen özellik gruplarına — ayıran özel bir modül kullanır. Bu öğrenilebilir gruplaşma, temsilin hangi parçalarının birlikte olması gerektiğine karar verir ve nesneleri, duyguları veya içerikteki ilişkileri vurgulayabilecek küçük anlamsal birimler oluşturur.
Görüntülerin ve kelimelerin birbirleriyle konuşmasına izin vermek
Bu anlamsal birimler oluşturulduktan sonra GIIFN bunların yapılandırılmış, üç aşamalı bir süreçte etkileşmesine izin verir. Önce yalnızca görüntü hakkında bildiklerini rafine eder; kaba genel izlenimleri ince görsel ayrıntılarla birleştirir. Sonra rafine edilmiş görüntü parçalarını metin parçalarıyla birleştirir ve iki yönlü bir dikkat mekanizması kullanır: görüntü birimleri metin birimlerine “bakar”, metin birimleri ise görüntü birimlerine “bakar”. Bu karşılıklı alışveriş, fırtınalı bir gökyüzünün neşeli bir ifadeyle eşleştirilmesi gibi çelişkileri yakalamaya yardımcı olur. Son adımda model bilgi açısından zengin görüntü altyazı birimlerini katıp sahnede neler olduğunu ve bunun yazılı mesajla nasıl ilişkili olduğunu daha derinlemesine anlar.
Modeli sahada test etmek
Bu ekstra analiz katmanlarının gerçekten yardımcı olup olmadığını görmek için araştırmacılar GIIFN’i hem metin hem de görüntü içeren, iğneleyici veya değil olarak etiketlenmiş yaygın kullanılan bir Twitter veri setinde test ettiler. Sistemi, grafikler, dikkat mekanizmaları veya dış bilgi kullanan güçlü modeller de dahil olmak üzere mevcut birçok yöntemle karşılaştırdılar. GIIFN doğruluk ve F1 skoru gibi standart ölçütlerde en iyi puanları elde etti ve sonuçları farklı rastgele eğitim–test bölüşümlerinde tutarlı kaldı. Sistemin bireysel parçalarının çıkarıldığı dikkatli ablation testleri, öğrenilebilir granülerlik gruplayıcısının en büyük performans artışını sağladığını; ince taneli görüntü ayrıntıları ve üç aşamalı füzyonun da anlamlı katkılar eklediğini gösterdi.
Çevrimiçi duyguyu anlamak için bunun anlamı
Günlük ifadeyle, bu çalışma makinelerin gönderileri daha küçük, anlamlı parçalara bölerek ve görüntülerin, sözcüklerin ve arka plan bilgisinin birbirini etkilemesine izin vererek “satır aralarını okuma” konusunda daha iyi olabileceğini gösteriyor. GIIFN’in katmanlı tasarımı, bir gönderinin yüzey anlamının alttaki niyetle çelişip çelişmediğini algılamayı bir algoritma için kolaylaştırır; bu, iğnelemenin ayırt edici özelliğidir. Şakaları ve iğneleri tespit etmenin ötesinde, aynı fikirler gelecekteki sistemlerin çevrimiçi duygu yorumunu daha güvenilir hale getirmesine yardımcı olabilir; içerik moderasyonu, söylenti tespiti ve ruh sağlığı izleme gibi araçların iyileştirilmesini sağlayarak modern sosyal platformların zengin, karma medya doğasıyla başa çıkabilir.
Atıf: Chen, M., Tang, H., Sun, C. et al. Granularity-guided fusion for multi-modal sentiment understanding. Sci Rep 16, 13286 (2026). https://doi.org/10.1038/s41598-026-43363-5
Anahtar kelimeler: iğneleme (sarkazm) tespiti, çok modlu duygu, sosyal medya analizi, derin öğrenme, görüntü-dil modelleri