Clear Sky Science · de
Granularitätsgeführte Fusion für multimodales Sentimentverständnis
Warum Online-Sarkasmus für Maschinen schwer ist
Sarkasmus ist im Netz allgegenwärtig: ein sonniges Strandfoto mit dem Kommentar „Schreckliches Wetter heute“ oder ein grinsendes Selfie unter „Ich liebe Staus ja so sehr“. Menschen verstehen den Witz sofort, weil wir die Diskrepanz zwischen dem, was wir sehen, und dem, was wir lesen, wahrnehmen. Computer dagegen tun sich mit dieser doppelten Bedeutung schwer, besonders wenn Beiträge Bilder, Text und versteckte kulturelle Hinweise mischen. Dieses Papier stellt ein neues KI-Modell vor, das Social‑Media‑Beiträge in mehreren Schichten betrachtet und Maschinen hilft, subtile Widersprüche zu bemerken und besser zu erkennen, wann Menschen sarkastisch sind.
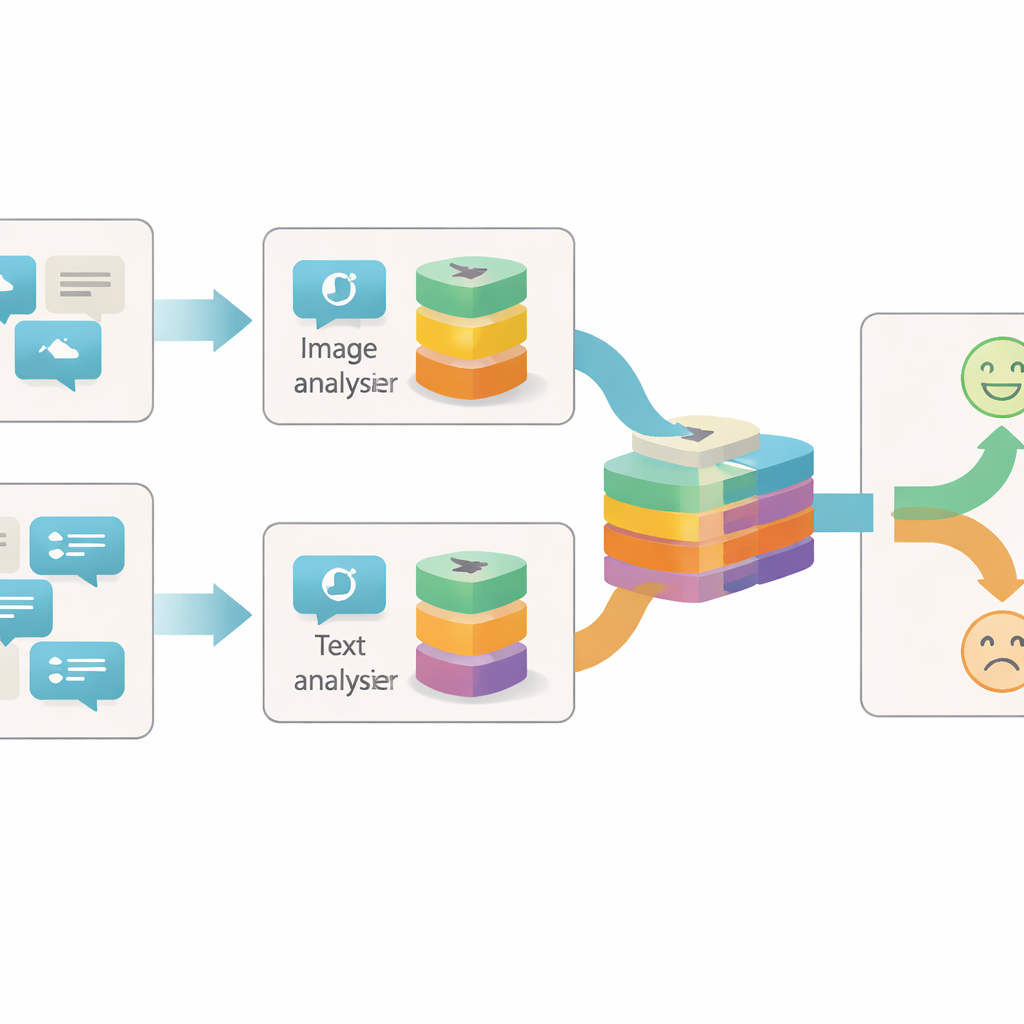
Beiträge aus mehr als einem Blickwinkel betrachten
Die meisten früheren Systeme zur Erkennung von Online‑Sarkasmus konzentrierten sich entweder auf den Text oder auf eine einfache Kombination aus Text und Bild. Oft behandelten sie jedes Bild oder jeden Satz als einen einzigen Informationsblock und betrachteten nur, wie diese beiden Blöcke übereinstimmten oder widersprachen. Die Autoren argumentieren, dass das zu grob ist: Innerhalb eines einzelnen Bildes oder Satzes können viele separate Hinweise auf das eigentliche Gefühl hinter einem Beitrag stecken. Ein helles, fröhliches Bild kann beispielsweise im Widerspruch zu düsterer Wortwahl stehen, oder ein neutrales Foto wird erst durch eine bestimmte Phrase sarkastisch. Um diese Nuancen zu erfassen, muss ein Modell jeden Inhaltsbestandteil auf unterschiedlichen Detailebenen betrachten.
Bedeutung in kleine Stücke zerlegen
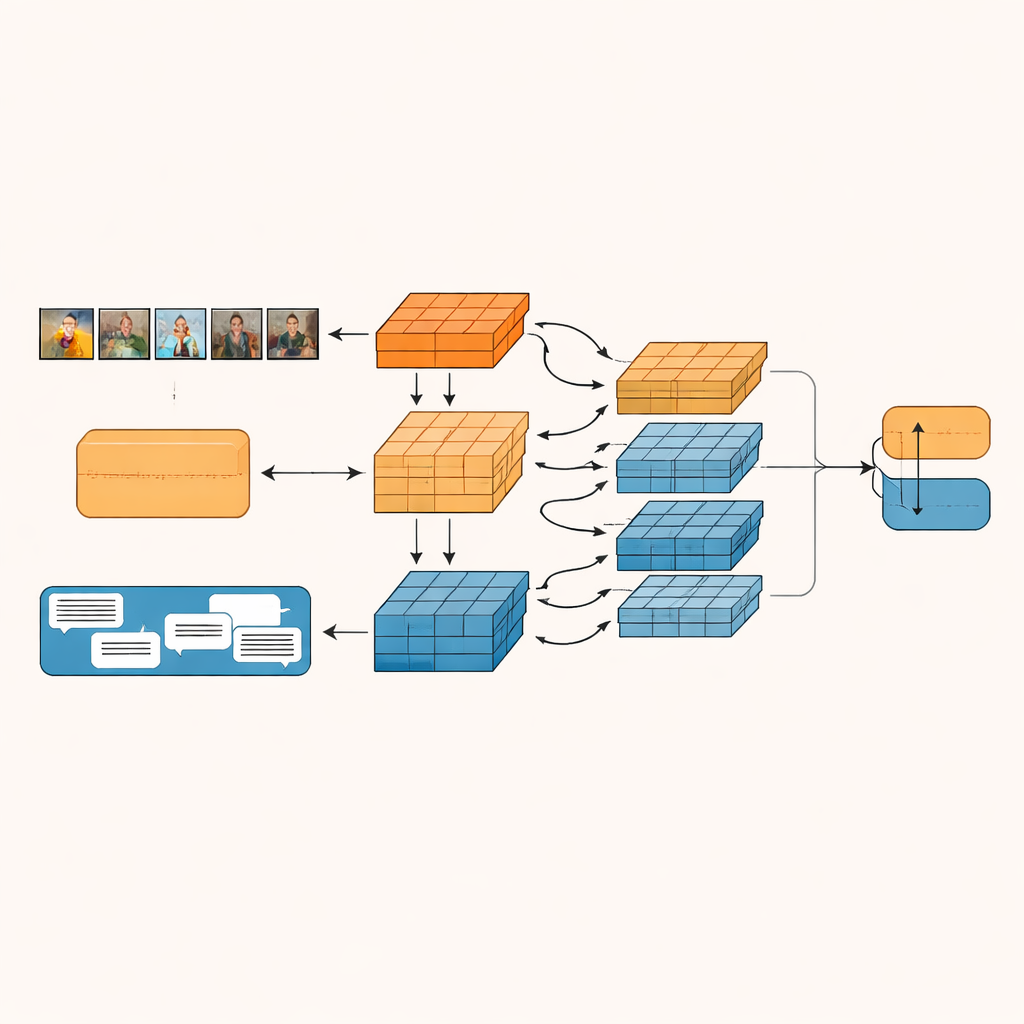
Das vorgeschlagene System, genannt Granularity-based Intra-modal and Inter-modal Fusion Network (GIIFN), beginnt mit leistungsfähigen vortrainierten Werkzeugen: einem Vision Transformer zur Bildverarbeitung und einem Sprachmodell zur Textverarbeitung. Es fügt außerdem eine dritte Informationsquelle hinzu, indem es ein automatisches Captioning‑Tool auf das Bild anwendet und so eine kurze Beschreibung erzeugt, die wie externes „Alltagswissen“ über das Bild wirkt. Statt die resultierenden Merkmalsvektoren als einen einzigen Block zu behandeln, verwendet das Modell ein spezielles Modul, um sie in mehrere „Granularitäten“ aufzuteilen – Gruppen von Merkmalen, die automatisch erlernt werden. Diese lernbare Gruppierung entscheidet, welche Teile der Repräsentation zusammengehören und bildet kleine semantische Einheiten, die etwa Objekte, Stimmungen oder Beziehungen innerhalb des Inhalts hervorheben können.
Bilder und Worte miteinander sprechen lassen
Sobald diese semantischen Einheiten gebildet sind, lässt GIIFN sie in einem strukturierten Drei‑Schritte‑Prozess miteinander interagieren. Zuerst verfeinert es das Wissen über das Bild allein, indem grobe Gesamteindrücke mit feinen visuellen Details kombiniert werden. Danach bringt es die verfeinerten Bildeinheiten mit den Texteinheiten zusammen, wobei ein bidirektionaler Aufmerksamkeitsmechanismus verwendet wird: Bildeinheiten „sehen“ auf Texteinheiten und Texteinheiten „sehen“ auf Bildeinheiten. Dieser wechselseitige Austausch hilft dem System, Widersprüche aufzunehmen, etwa einen stürmischen Himmel, der mit einer heiteren Phrase gepaart ist. Im letzten Schritt integriert das Modell die wissensreichen Bildbeschreibungs‑Einheiten, vertieft so sein Verständnis dessen, was in der Szene passiert, und wie das mit der geschriebenen Nachricht zusammenhängt.
Das Modell in freier Wildbahn testen
Um zu prüfen, ob diese zusätzlichen Analyseebenen wirklich helfen, testeten die Forschenden GIIFN auf einem weit verbreiteten Twitter‑Datensatz mit Beiträgen, die als sarkastisch oder nicht sarkastisch gelabelt sind und jeweils Text sowie ein Bild enthalten. Sie verglichen ihr System mit vielen bestehenden Methoden, darunter starke Modelle, die bereits Graphen, Attention oder externes Wissen nutzen. GIIFN erzielte die besten Werte bei Standardmaßen wie Accuracy und F1‑Score, und die Ergebnisse waren über verschiedene zufällige Trainings‑Test‑Aufteilungen hinweg konsistent. Sorgfältige Ablationsstudien, bei denen einzelne Systemteile entfernt wurden, zeigten, dass die lernbare Granularitätsgruppierung den größten Leistungszuwachs brachte, während die feinkörnigen Bilddetails und die dreistufige Fusion ebenfalls spürbare Verbesserungen beitrugen.
Was das für das Verständnis von Online‑Emotionen bedeutet
Alltäglich ausgedrückt zeigt diese Arbeit, dass Maschinen besser „zwischen den Zeilen lesen“ können, indem sie Beiträge in kleinere, sinnvolle Stücke zerlegen und Bilder, Worte und Hintergrundwissen einander wechselseitig beeinflussen lassen. Das geschichtete Design von GIIFN macht es einem Algorithmus leichter zu erkennen, wann die oberflächliche Bedeutung eines Beitrags mit seiner eigentlichen Absicht kollidiert – ein Kennzeichen von Sarkasmus. Über das Erkennen von Witzen und Ironie hinaus könnten dieselben Ideen künftigen Systemen helfen, Online‑Sentiment zuverlässiger zu interpretieren und Werkzeuge für Inhaltsmoderation, Gerüchteerkennung und mentale Gesundheitsüberwachung zu verbessern, während sie gleichzeitig mit der reichen, gemischten Medienform moderner sozialer Plattformen umgehen.
Zitation: Chen, M., Tang, H., Sun, C. et al. Granularity-guided fusion for multi-modal sentiment understanding. Sci Rep 16, 13286 (2026). https://doi.org/10.1038/s41598-026-43363-5
Schlüsselwörter: Sarkasmuserkennung, multimodales Sentiment, Social-Media-Analyse, Deep Learning, Vision-Language-Modelle