Clear Sky Science · sv
Fusionsmetod styrd av granularitet för multimodal sentimentförståelse
Varför sarkasm online är svårt för maskiner
Sarkasm finns överallt på nätet: en solig strandbild märkt med ”Förfärligt väder idag” eller en leende selfie under texten ”Jag bara älskar bilköer.” Människor uppfattar skämtet direkt eftersom vi känner igen avvikelsen mellan vad vi ser och vad vi läser. Datorer har däremot svårt med denna dubbla betydelse, särskilt när inlägg blandar bilder, text och dolda kulturella signaler. Denna artikel presenterar en ny AI-modell som tolkar inlägg i sociala medier på ett mer flerdimensionellt sätt, vilket hjälper system att upptäcka subtila motsägelser och bättre förstå när människor är sarkastiska.
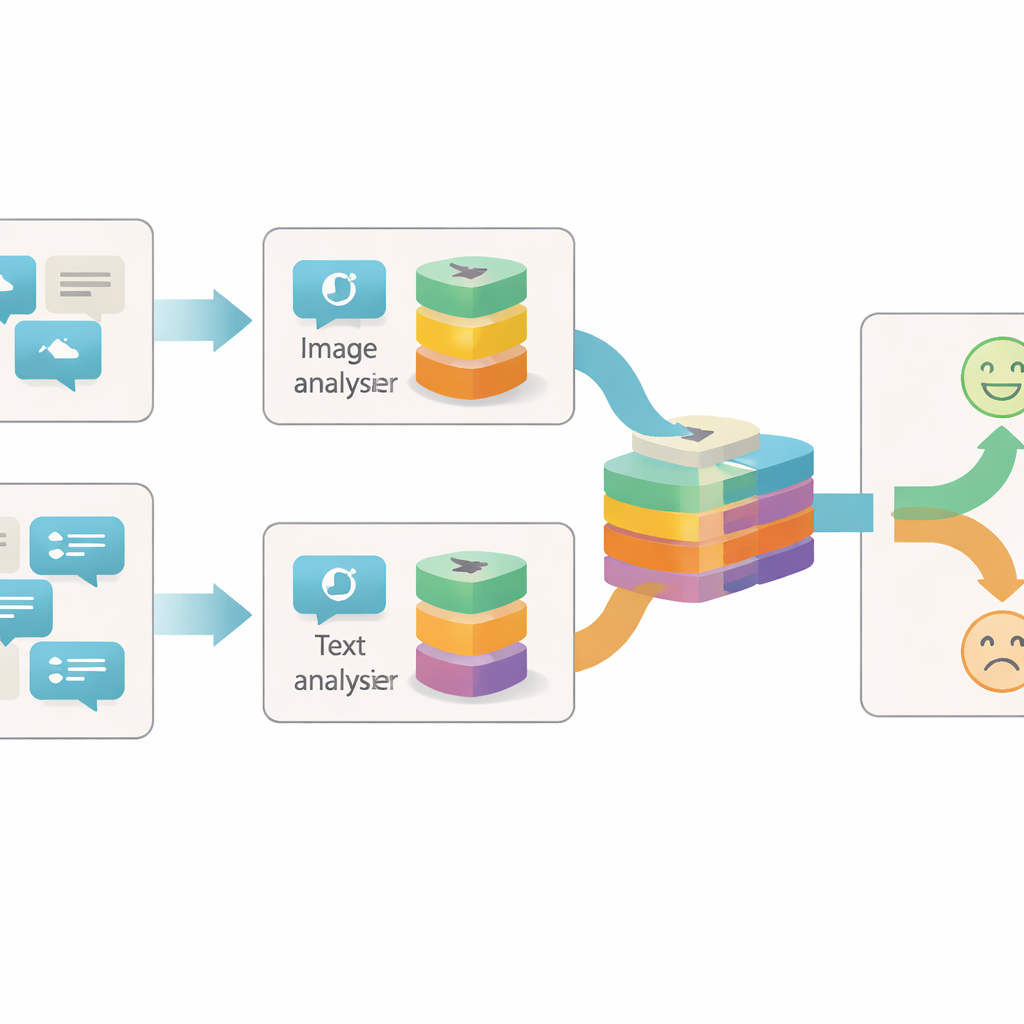
Att betrakta inlägg från flera vinklar
De flesta tidigare system för att upptäcka sarkasm online har fokuserat antingen på texten eller på en enkel kombination av text och bild. De behandlade ofta varje bild eller mening som ett enda informationsblock och tittade bara på hur dessa block överensstämde eller motsade varandra. Författarna menar att detta är alltför grovt: inom en enda bild eller mening kan det finnas många separata ledtrådar till det verkliga känsloläget bakom ett inlägg. Till exempel kan en ljus, glad bild stå i kontrast till dystra formuleringar, eller en neutral bild kan först bli sarkastisk i kombination med en viss fras. För att fånga dessa nyanser behöver en modell granska varje innehållsdel på olika detaljnivåer.
Att bryta ned betydelsen i mindre delar
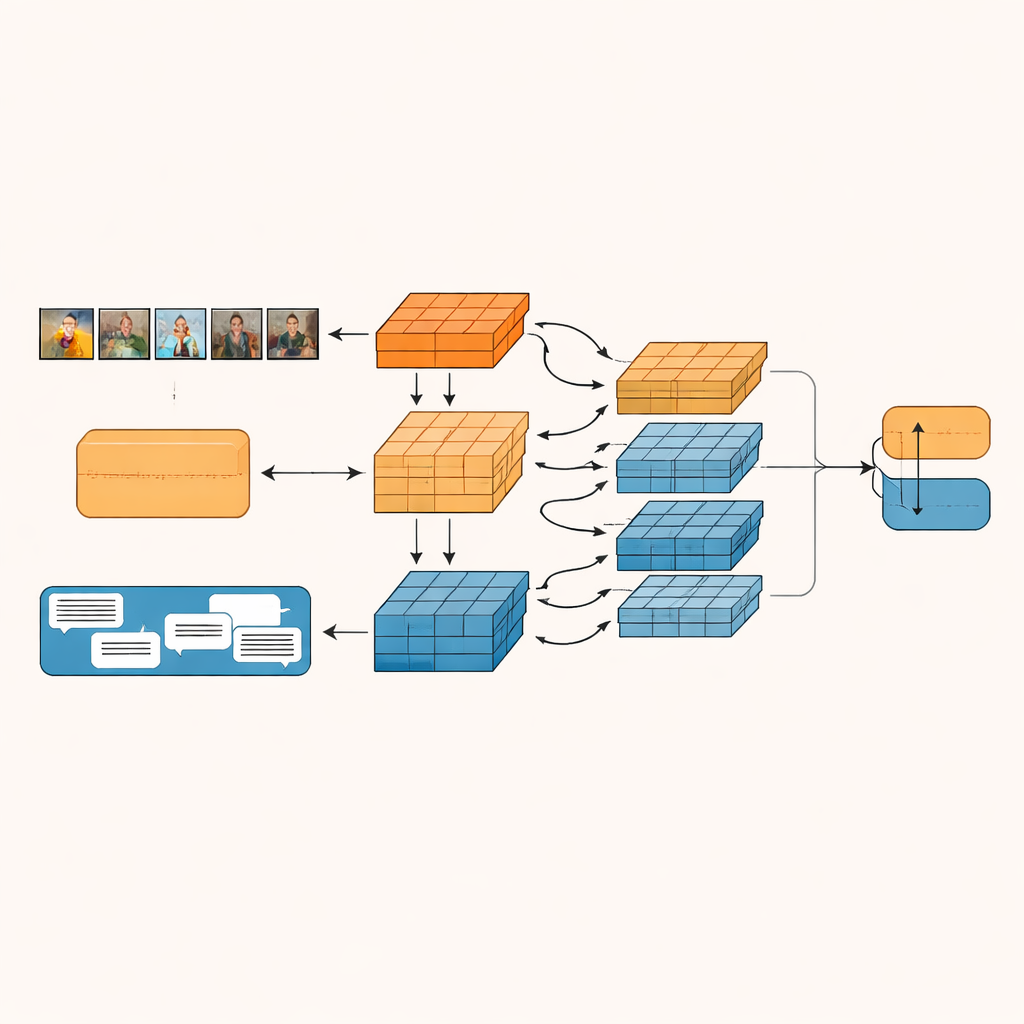
Det föreslagna systemet, kallat Granularity-based Intra-modal and Inter-modal Fusion Network (GIIFN), börjar med kraftfulla förtränade verktyg: en vision-transformer för att tolka bilder och en språkmodell för att tolka text. Det lägger också till en tredje informationskälla genom att köra en automatisk bildtextsgenerator på bilden och skapa en kort beskrivning som fungerar som extern ”sunt förnuft” om vad bilden visar. Istället för att behandla de resulterande funktionsvektorerna som en enda klump använder modellen en specialmodul för att dela upp dem i flera ”granulariteter” — grupper av funktioner som lärs automatiskt. Denna lärbara gruppering avgör vilka delar av representationen som hör ihop och bildar små semantiska enheter som kan framhäva till exempel objekt, stämningar eller relationer i innehållet.
Låta bilder och ord samspela
När dessa semantiska enheter har skapats låter GIIFN dem interagera i en strukturerad trestegsprocess. Först förfinar den vad den vet om bilden ensam och kombinerar grova helhetsintryck med fina visuella detaljer. Därefter förenar den de förfinade bilddelarna med textdelarna med hjälp av en tvåvägs attention-mekanism: bildenheter ”tittar på” textenheter och textenheter ”tittar på” bildenheter. Denna ömsesidiga växelverkan hjälper systemet att plocka upp motsägelser, som en stormig himmel i samband med en glad formulering. I det sista steget integrerar modellen de kunskapsrika bildtextenheterna, vilket fördjupar förståelsen av vad som händer i scenen och hur det relaterar till den skrivna texten.
Testning av modellen i verkliga miljöer
För att undersöka om dessa extra analyslager verkligen hjälper testade forskarna GIIFN på en välanvänd Twitter-dataset med inlägg märkta som sarkastiska eller inte, där varje post innehöll både text och bild. De jämförde sitt system med många befintliga metoder, inklusive starka modeller som redan använder grafer, attention eller extern kunskap. GIIFN uppnådde de bästa resultaten över standardmått som noggrannhet och F1-score, och resultaten var stabila över olika slumpmässiga uppdelningar i tränings- och testdata. Noga utförda ablationstester, där enskilda delar av systemet plockades bort, visade att den lärbara granularitetsgrupperingen gav den största prestationsökningen, medan de finfördelade bilddetaljerna och den trestegs-fusionen också bidrog med meningsfulla förbättringar.
Vad detta betyder för förståelsen av onlinekänslor
I vardagliga termer visar detta arbete att maskiner kan bli bättre på att ”läsa mellan raderna” genom att bryta ner inlägg i mindre, meningsfulla delar och låta bilder, ord och bakgrundskunskap påverka varandra. GIIFN:s flerskiktade design gör det lättare för en algoritm att upptäcka när ett inläggs ytliga mening strider mot dess underliggande avsikt, vilket är kännetecknande för sarkasm. Utöver att identifiera skämt och sarkasm kan samma idéer hjälpa framtida system att tolka online-sentiment mer pålitligt, förbättra verktyg för innehållsmoderering, ryktesspridningsdetektion och mentalhälsomonitorering — samtidigt som de hanterar den rika, multimodala naturen hos moderna sociala plattformar.
Citering: Chen, M., Tang, H., Sun, C. et al. Granularity-guided fusion for multi-modal sentiment understanding. Sci Rep 16, 13286 (2026). https://doi.org/10.1038/s41598-026-43363-5
Nyckelord: sarkasmupptäckt, multimodalt sentiment, analys av sociala medier, deep learning, vision-language-modeller