Clear Sky Science · he
מיזוג מונחה-גרנולריות להבנת סנטימנט רב-מודאלי
מדוע סרקזם אונליין קשה למכונות
סרקזם נמצא בכל מקום ברשת: תמונת חוף שטופת שמש עם התיוג "מזג אוויר נוראי היום", או סלפי מחייכת תחת הכיתוב "אני פשוט אוהב פקקי תנועה". בני אדם קולטים את הבדיחה מיד כי הם מרגישים את חוסר ההתאמה בין מה שאנו רואים למה שנכתב. מחשבים, לעומת זאת, מתקשים עם המשמעות הכפולה הזאת, במיוחד כאשר פוסטים מערבים תמונות, טקסט ורמזים תרבותיים נסתרי משמעויות. מאמר זה מציג מודל בינה מלאכותית חדש שמתבונן בפוסטים ברשת בשכבות רבות יותר, ועוזר למכונות לזהות סתירות עדינות ולהבין טוב יותר מתי אנשים מצטטים בסרקזם.
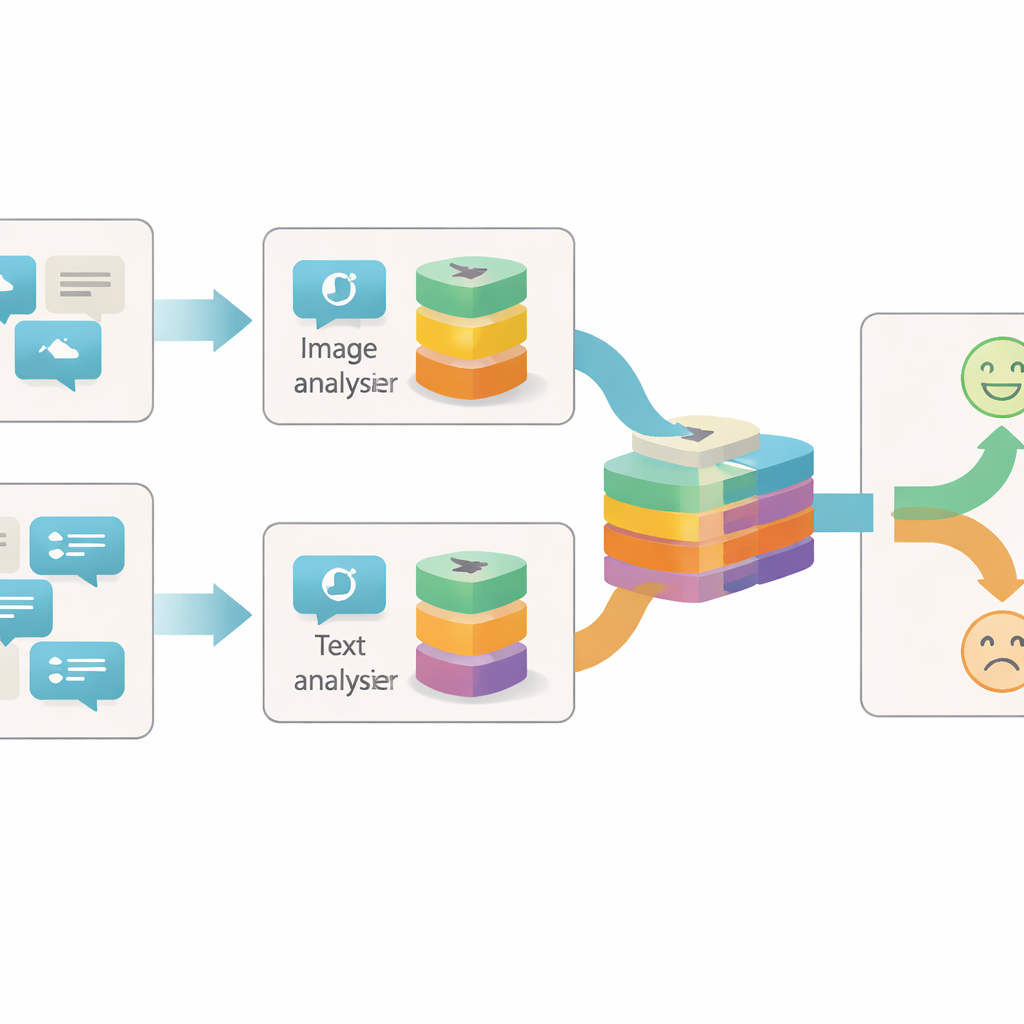
מבט על פוסטים מכיוונים שונים
מרבית המערכות הקודמות לזיהוי סרקזם ברשת התמקדו או בטקסט או בשילוב פשוט של טקסט ותמונה. לעתים קרובות הן התייחסו לכל תמונה או משפט כיחידת מידע אחת ובחנו רק עד כמה שתי היחידות הללו מסכימות או סותרות זו את זו. המחברים טוענים שזה גס מדי: בתוך תמונה אחת או משפט אחד יכולים להיות רמזים נפרדים רבים לגבי התחושה האמיתית שמאחורי הפוסט. למשל, תמונה בהירה ושמחה עלולה להתנגש עם ניסוח מדוכדך, או תמונה ניטרלית עשויה להפוך לסרקסטית רק כשמצורפת אליה ביטוי מסוים. כדי ללכוד את הדקויות הללו, מודל צריך להתבונן בתוך כל יחידת תוכן ברמות פירוט שונות.
פירוק המשמעות לחתיכות קטנות
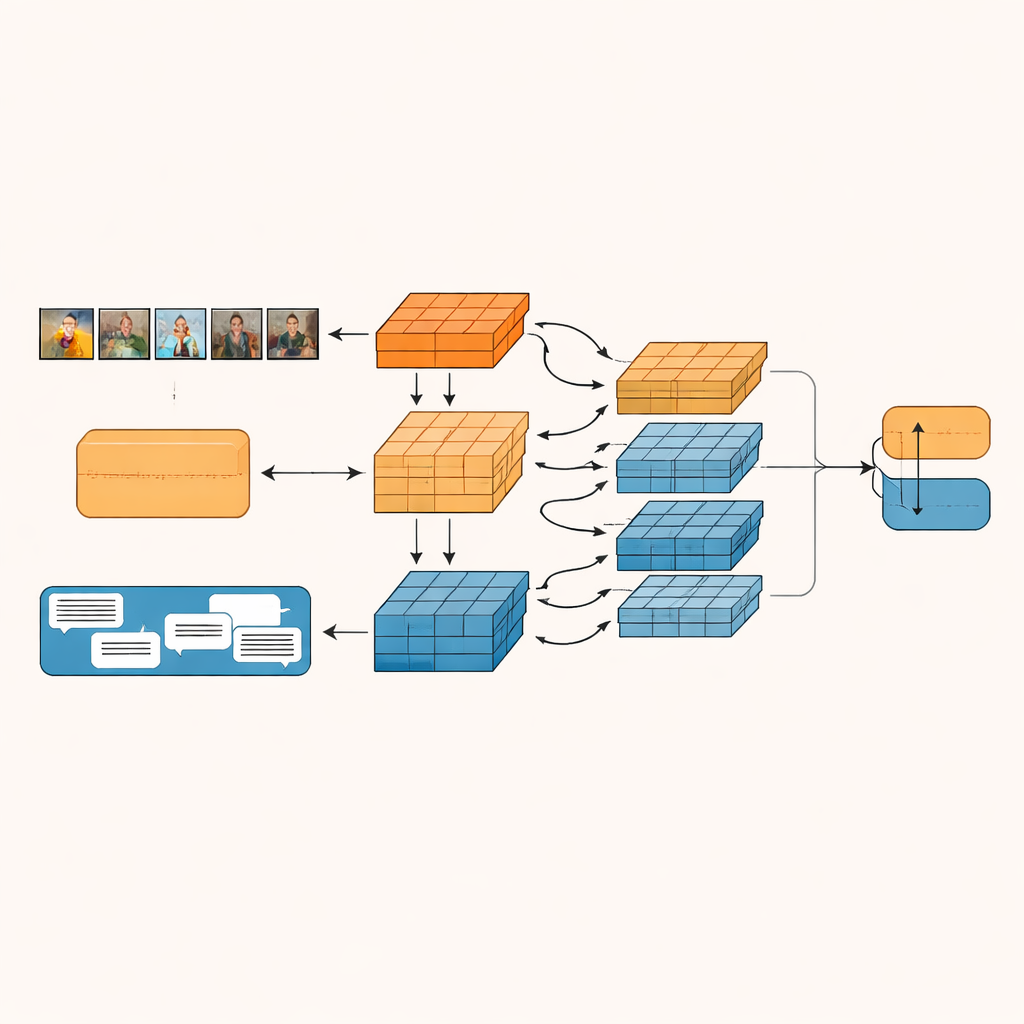
המערכת המוצעת, שנקראת רשת המיזוג הפנימי-מודאלי ובין-מודאלי המונחית-גרנולריות (GIIFN), מתחילה בשימוש בכלים חזקים מאומני-מקור: טרנספורמר חזוני להבנת תמונות ומודל שפה להבנת טקסט. בנוסף היא מוסיפה מקור מידע שלישי דרך הרצת כלי תיאור אוטומטי על התמונה, שיוצר תיאור קצר המשמש כ"הגיון נפוץ" חיצוני לגבי מה שהתמונה מציגה. במקום להתייחס לווקטורי התכונות שנוצרו כגוש אחד, המודל משתמש במודול מיוחד שמפצל אותם לכמה "גרנולריות" — קבוצות תכונות שנלמדות אוטומטית. קיבוץ הנלמד הזה קובע אילו חלקים של הייצוג שייכים יחד, ויוצר יחידות סמנטיות קטנות שיכולות להדגיש, למשל, עצמים, מצבים רוחיים או יחסים בתוך התוכן.
לתת לתמונות ולמילים לתקשר זו עם זו
ברגע שיחידות סמנטיות אלה נוצרות, GIIFN מאפשרת להן להיערך באינטראקציה מובנית בתהליך תלת-שלבי. ראשית, היא מחדדת את הידע על התמונה לבדה, ומשלבת התרשמויות כלליות גסות עם פרטים חזותיים עדינים. לאחר מכן, היא מביאה את חתיכות התמונה המודללות יחד עם חתיכות הטקסט, באמצעות מנגנון תשומת לב דו-כיווני: יחידות תמונה "מביטות" ביחידות טקסט ויחידות טקסט "מביטות" ביחידות תמונה. החלפה הדדית זו מסייעת למערכת לתפוס סתירות, כגון שמיים סוערים המוצמדים לביטוי עליז. בשלב הסופי, המודל משלב את יחידות כותרת התמונה העשירות בידע, מה שמעמיק את הבנת מה מתרחש בסצנה וכיצד זה מתקשר להודעה הכתובה.
בדיקת המודל בשטח
כדי לבדוק האם השכבות הנוספות של הניתוח אכן עוזרות, החוקרים בדקו את GIIFN על מערך נתונים נפוץ של ציוצים מתויגים כסרקסטיים או לא, שכל אחד מהם מכיל טקסט ותמונה. הם השוו את המערכת שלהם לשיטות רבות קיימות, כולל מודלים חזקים שמשתמשים כבר בגרפים, תשומת לב או ידע חיצוני. GIIFN השיגה את התוצאות הטובות ביותר במדדים מקובלים כגון דיוק ו-F1, והתוצאות שלה היו עקביות על פני פיצולי אימון-מבחן אקראיים שונים. ניסויי אבולוציה זהירים, שבהם הוסרו חלקים בודדים מהמערכת, הראו כי קיבוץ הגרנולריות הנלמד היה הגורם שנתן את קפיצת הביצועים הגדולה ביותר, בעוד שהפרטים החזותיים הדקים והמיזוג בתלת-שלב גם הם הוסיפו שיפורים משמעותיים.
מה משמעות הדבר עבור הבנת רגשות ברשת
במונחים יומיומיים, עבודה זו מראה שמכונות יכולות להשתפר ב"קריאה בין השורות" על ידי פירוק פוסטים לחתיכות קטנות ומשמעותיות והפעלת אינטראקציה בין תמונות, מילים וידע רקע. העיצוב הרב-שכבתי של GIIFN מקל על אלגוריתם לזהות כאשר המשמעות החיצונית של פוסט מתנגשת עם הכוונה הטמונה שלו — סימן היכר של סרקזם. מעבר לזיהוי בדיחות וציניות, אותן רעיונות יכולים לעזור למערכות עתידיות לפרש סנטימנט ברשת בצורה אמינה יותר, ולשפר כלים למודרציה של תוכן, זיהוי שמועות וניטור בריאות נפשית, וכל זאת תוך התמודדות עם הטבע העשיר והמגוון של מדיה משולבת בפלטפורמות חברתיות מודרניות.
ציטוט: Chen, M., Tang, H., Sun, C. et al. Granularity-guided fusion for multi-modal sentiment understanding. Sci Rep 16, 13286 (2026). https://doi.org/10.1038/s41598-026-43363-5
מילות מפתח: זיהוי סרקזם, סנטימנט מולטימודאלי, ניתוח מדיה חברתית, למידה עמוקה, מודלים חזון-שפה