Clear Sky Science · fr
Fusion guidée par granularité pour la compréhension multimodale du sentiment
Pourquoi le sarcasme en ligne est difficile pour les machines
Le sarcasme est omniprésent en ligne : une photo de plage ensoleillée légendée « Temps affreux aujourd’hui », ou un selfie souriant sous la mention « J’adore les embouteillages ». Les humains saisissent instantanément la plaisanterie parce que nous percevons le décalage entre ce que nous voyons et ce que nous lisons. Les ordinateurs, en revanche, peinent à appréhender ce double sens, notamment lorsque les publications mêlent images, texte et indices culturels implicites. Cet article présente un nouveau modèle d’intelligence artificielle qui analyse les publications sur les réseaux sociaux de manière plus stratifiée, aidant les machines à repérer des contradictions subtiles et à mieux comprendre quand les internautes sont sarcastiques.
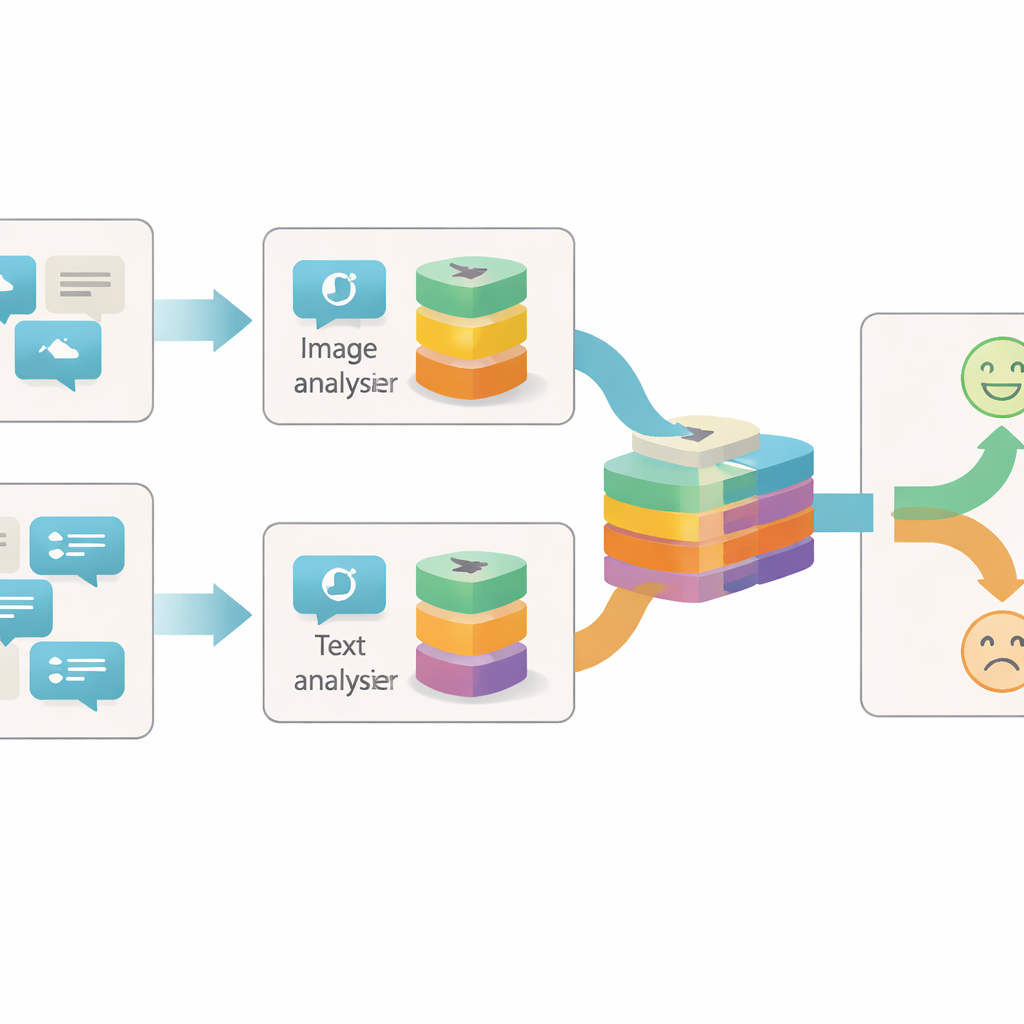
Examiner les publications sous plusieurs angles
La plupart des systèmes antérieurs pour repérer le sarcasme en ligne se concentraient soit sur le texte soit sur une combinaison simple texte–image. Ils traitaient souvent chaque image ou phrase comme un bloc unique d’information et ne considéraient que la concordance ou la discordance entre ces blocs. Les auteurs soutiennent que c’est trop grossier : au sein d’une même image ou d’une même phrase, il peut y avoir de nombreux indices distincts sur le véritable sentiment porté par la publication. Par exemple, une photo lumineuse et joyeuse peut contraster avec un texte morose, ou une photo neutre ne devient sarcastique que lorsqu’elle est associée à une certaine expression. Pour saisir ces nuances, un modèle doit examiner l’intérieur de chaque élément de contenu à différents niveaux de détail.
Décomposer le sens en petits éléments
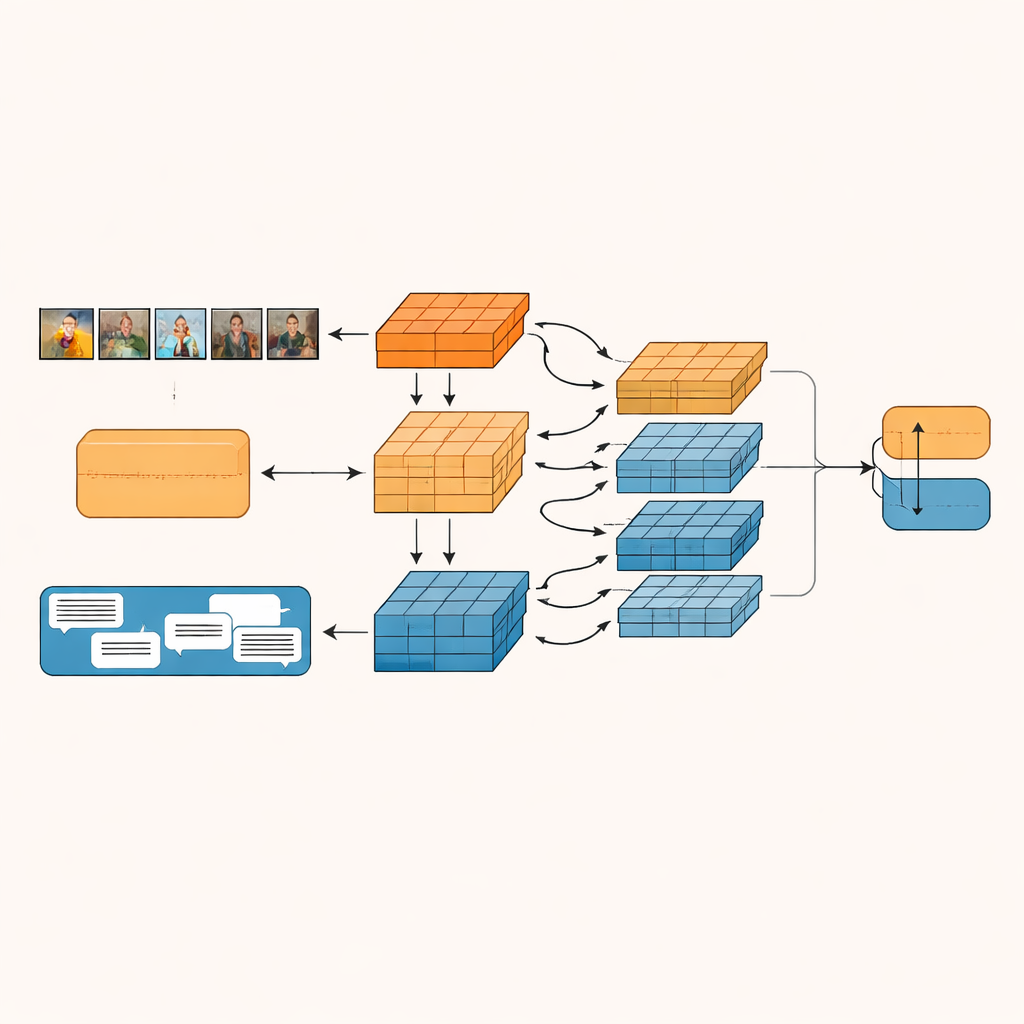
Le système proposé, appelé Réseau de Fusion Intra-modal et Inter-modal basé sur la Granularité (GIIFN), commence par exploiter des outils pré-entraînés puissants : un vision transformer pour comprendre les images et un modèle de langage pour comprendre le texte. Il ajoute aussi une troisième source d’information en générant automatiquement une légende pour l’image, créant une brève description qui sert de « sens commun » externe sur le contenu visuel. Plutôt que de considérer les vecteurs de caractéristiques résultants comme une masse unique, le modèle utilise un module spécial pour les diviser en plusieurs « granularités » — groupes de caractéristiques appris automatiquement. Ce regroupement apprenable décide quelles parties de la représentation vont ensemble, formant de petites unités sémantiques qui peuvent mettre en évidence, par exemple, des objets, des ambiances ou des relations à l’intérieur du contenu.
Laisser les images et les mots dialoguer
Une fois ces unités sémantiques formées, GIIFN les fait interagir selon un processus structuré en trois étapes. D’abord, il affine sa compréhension de l’image seule, en combinant des impressions globales grossières avec des détails visuels fins. Ensuite, il met en relation les morceaux d’image raffinés avec les morceaux de texte, en utilisant un mécanisme d’attention bidirectionnelle : les unités d’image « regardent » les unités de texte et les unités de texte « regardent » les unités d’image. Cet échange mutuel aide le système à détecter des contradictions, comme un ciel orageux associé à une phrase enjouée. Dans la dernière étape, le modèle intègre les unités issues des légendes d’image, riches en connaissances, approfondissant sa compréhension de la scène et de sa relation avec le message écrit.
Tester le modèle sur des données réelles
Pour vérifier si ces couches d’analyse supplémentaires sont réellement utiles, les chercheurs ont évalué GIIFN sur un jeu de données Twitter largement utilisé, contenant des publications étiquetées comme sarcastiques ou non, comportant à la fois du texte et une image. Ils ont comparé leur système à de nombreuses méthodes existantes, y compris des modèles performants utilisant déjà des graphes, de l’attention ou des connaissances externes. GIIFN a obtenu les meilleurs scores sur des mesures standards telles que la précision et le F1-score, et ses résultats se sont avérés cohérents sur différentes répartitions aléatoires entraînement–test. Des tests d’ablation soigneux, où des parties individuelles du système étaient retirées, ont montré que le regroupement apprenable par granularité apportait le gain de performance le plus important, tandis que les détails visuels fins et la fusion en trois étapes ajoutaient aussi des améliorations significatives.
Ce que cela signifie pour la compréhension des émotions en ligne
En termes généraux, ce travail montre que les machines peuvent mieux « lire entre les lignes » en décomposant les publications en éléments plus petits et signifiants, et en laissant images, mots et connaissances contextuelles s’influencer mutuellement. La conception en couches de GIIFN facilite la détection des cas où le sens apparent d’une publication est en contradiction avec son intention sous-jacente, caractéristique du sarcasme. Au-delà de la détection des plaisanteries et du cynisme, les mêmes idées pourraient aider les systèmes futurs à interpréter le sentiment en ligne de manière plus fiable, améliorant des outils de modération de contenu, de détection de rumeurs et de surveillance de la santé mentale, tout en gérant la nature riche et multimédia des plateformes sociales modernes.
Citation: Chen, M., Tang, H., Sun, C. et al. Granularity-guided fusion for multi-modal sentiment understanding. Sci Rep 16, 13286 (2026). https://doi.org/10.1038/s41598-026-43363-5
Mots-clés: détection du sarcasme, sentiment multimodal, analyse des réseaux sociaux, apprentissage profond, modèles vision-langage