Clear Sky Science · it
Fusione guidata dalla granularità per la comprensione multimodale del sentimento
Perché il sarcasmo online è difficile per le macchine
Il sarcasmo è ovunque online: una foto di una spiaggia soleggiata accompagnata da “Che tempo orribile oggi”, o un selfie sorridente con la didascalia “Adoro proprio gli ingorghi”. Gli esseri umani colgono subito la battuta perché percepiamo la discrepanza tra ciò che vediamo e ciò che leggiamo. I computer, invece, faticano con questo doppio significato, soprattutto quando i post mescolano immagini, testo e riferimenti culturali impliciti. Questo lavoro introduce un nuovo modello di intelligenza artificiale che analizza i post dei social media in modo più stratificato, aiutando le macchine a notare contraddizioni sottili e a capire meglio quando le persone sono sarcastiche.
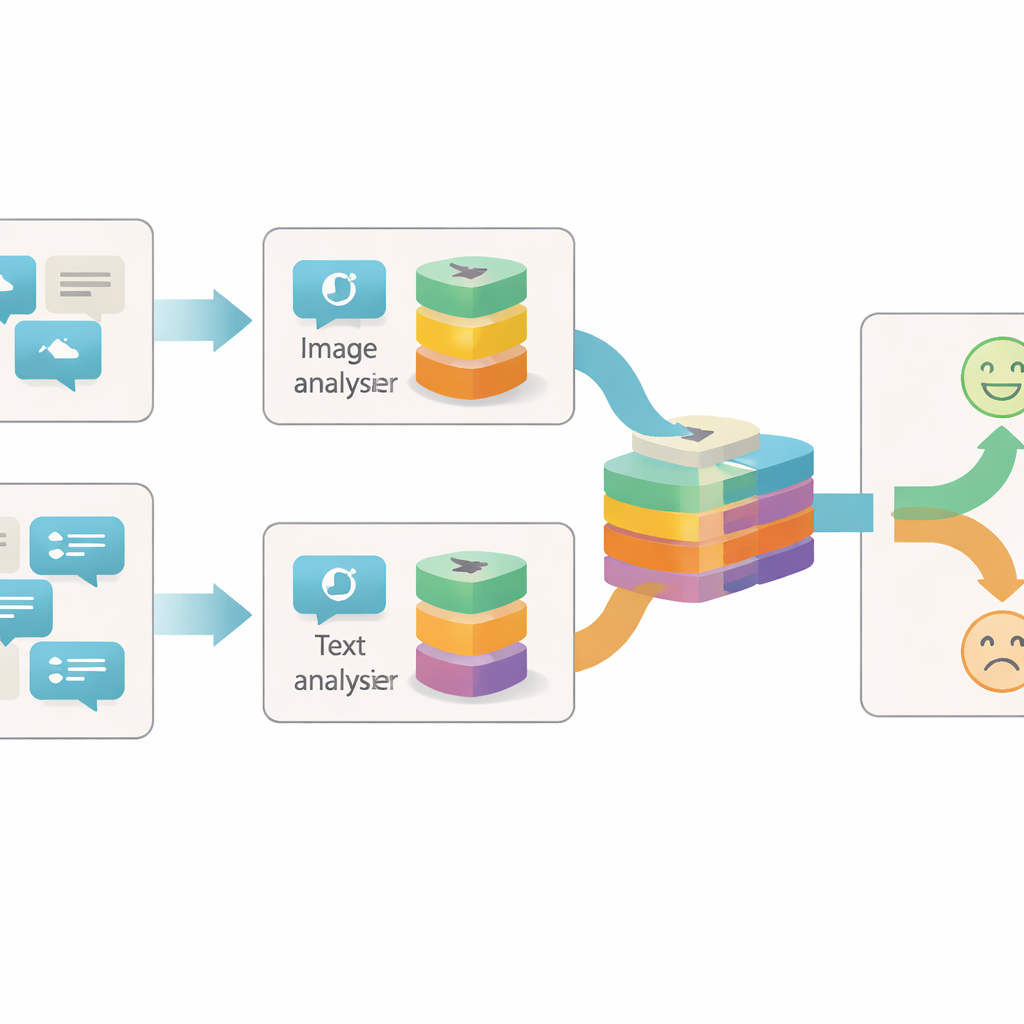
Osservare i post da più angolazioni
La maggior parte dei sistemi precedenti per individuare il sarcasmo online si concentrava o sul testo o su una combinazione semplice di testo e immagine. Spesso trattavano ogni immagine o frase come un unico blocco informativo e guardavano solo a come i due blocchi concordavano o si contraddicevano. Gli autori sostengono che questo approccio è troppo rozzo: all’interno di una singola immagine o frase possono esserci molti indizi separati sul sentimento reale dietro un post. Per esempio, un’immagine luminosa e allegra può scontrarsi con parole cupe, oppure una foto neutra può diventare sarcastica solo se associata a una certa frase. Per cogliere queste sfumature, un modello deve analizzare ogni elemento di contenuto a diversi livelli di dettaglio.
Spezzare il significato in piccoli pezzi
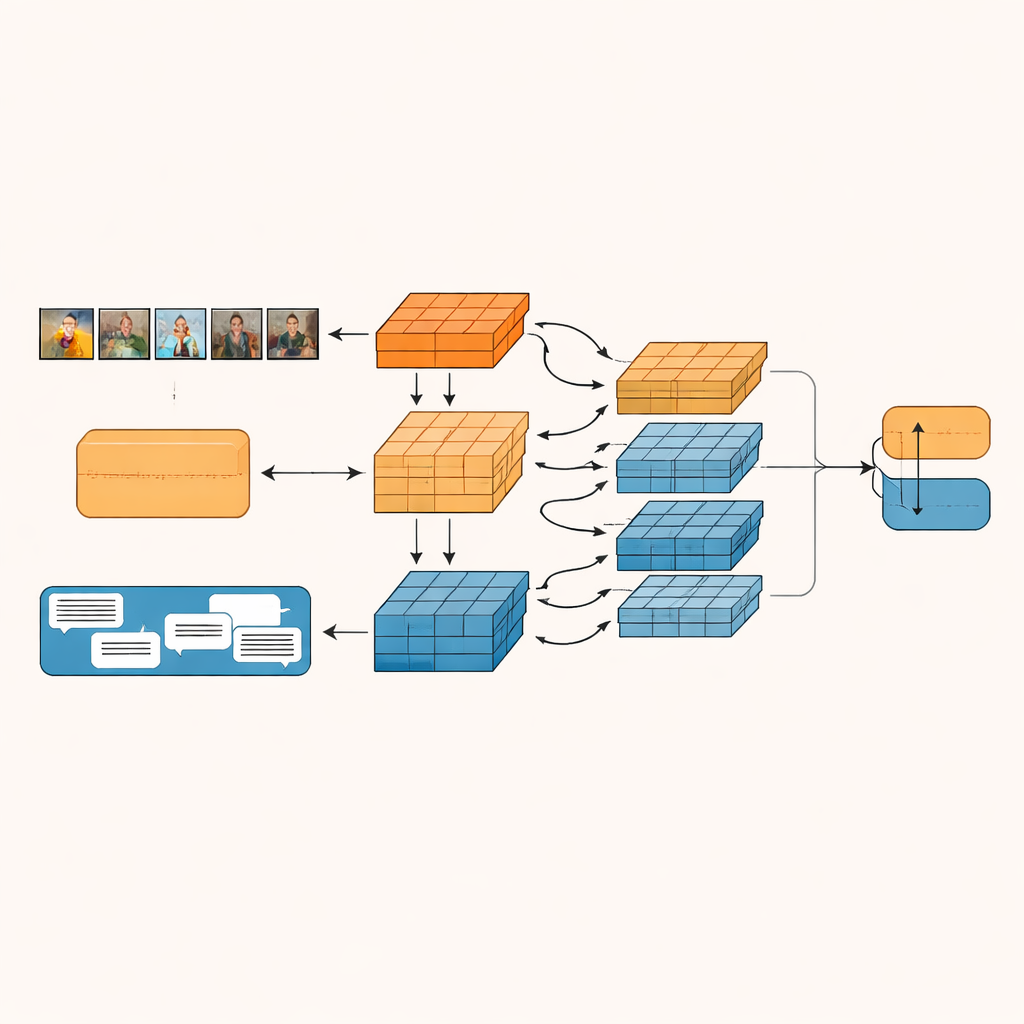
Il sistema proposto, chiamato Granularity-based Intra-modal and Inter-modal Fusion Network (GIIFN), parte dall’uso di potenti strumenti pre-addestrati: un vision transformer per comprendere le immagini e un modello linguistico per comprendere il testo. Aggiunge anche una terza fonte d’informazione eseguendo uno strumento di captioning automatico sull’immagine, creando una breve descrizione che funge da “conoscenza comune” esterna su ciò che la foto mostra. Invece di trattare i vettori di caratteristiche risultanti come un unico insieme, il modello utilizza un modulo speciale per suddividerli in più “granularità” — gruppi di caratteristiche apprese automaticamente. Questo raggruppamento apprendibile decide quali parti della rappresentazione appartengono insieme, formando piccole unità semantiche che possono evidenziare, per esempio, oggetti, stati d’animo o relazioni all’interno del contenuto.
Far dialogare immagini e parole
Una volta formate queste unità semantiche, GIIFN ne consente l’interazione tramite un processo strutturato in tre fasi. Per prima cosa, affina ciò che sa sull’immagine da sola, combinando impressioni generali e grossolane con dettagli visivi fini. Poi mette insieme i pezzi di immagine raffinati con i pezzi di testo, usando un meccanismo di attenzione bidirezionale: le unità immagine “guardano” le unità testo e le unità testo “guardano” le unità immagine. Questo scambio reciproco aiuta il sistema a cogliere contraddizioni, come un cielo tempestoso associato a una frase gioiosa. Nella fase finale, il modello integra le unità ricche di conoscenza derivate dalle didascalie dell’immagine, approfondendo la comprensione di ciò che accade nella scena e di come questo si relazioni al messaggio scritto.
Testare il modello sul campo
Per verificare se questi strati aggiuntivi di analisi fossero davvero utili, i ricercatori hanno testato GIIFN su un dataset di Twitter ampiamente utilizzato, composto da post etichettati come sarcastici o non sarcastici, ciascuno contenente testo e immagine. Hanno confrontato il loro sistema con molti metodi esistenti, inclusi modelli avanzati che già impiegano grafi, attenzione o conoscenza esterna. GIIFN ha ottenuto i punteggi migliori sulle misure standard come accuratezza e F1-score, e i suoi risultati sono stati coerenti attraverso diverse suddivisioni casuali train–test. Attenti test di ablazione, in cui singole parti del sistema sono state rimosse, hanno mostrato che il raggruppamento apprendibile per granularità ha apportato il maggiore incremento di prestazioni, mentre i dettagli visivi fine-grained e la fusione in tre fasi hanno fornito guadagni significativi.
Cosa significa per la comprensione delle emozioni online
In termini pratici, questo lavoro mostra che le macchine possono migliorare nel “leggere fra le righe” spezzando i post in pezzi più piccoli e significativi e permettendo a immagini, parole e conoscenze di background di influenzarsi a vicenda. Il design a strati di GIIFN facilita per un algoritmo la rilevazione quando il significato superficiale di un post si scontra con l’intento sottostante, caratteristica tipica del sarcasmo. Oltre a individuare battute e ironia, le stesse idee potrebbero aiutare sistemi futuri a interpretare il sentimento online in modo più affidabile, migliorando strumenti per la moderazione dei contenuti, la rilevazione di dicerie e il monitoraggio della salute mentale, il tutto affrontando la natura ricca e multimediale delle piattaforme social moderne.
Citazione: Chen, M., Tang, H., Sun, C. et al. Granularity-guided fusion for multi-modal sentiment understanding. Sci Rep 16, 13286 (2026). https://doi.org/10.1038/s41598-026-43363-5
Parole chiave: rilevamento del sarcasmo, sentimento multimodale, analisi dei social media, deep learning, modelli visione-linguaggio