Clear Sky Science · en
Granularity-guided fusion for multi-modal sentiment understanding
Why online sarcasm is hard for machines
Sarcasm is everywhere online: a sunny beach photo tagged with “Terrible weather today,” or a grinning selfie under “I just love traffic jams.” Humans instantly catch the joke because we sense the mismatch between what we see and what we read. Computers, however, struggle with this double meaning, especially when posts mix images, text, and hidden cultural cues. This paper introduces a new artificial intelligence model that looks at social media posts in a more layered way, helping machines notice subtle contradictions and better understand when people are being sarcastic.
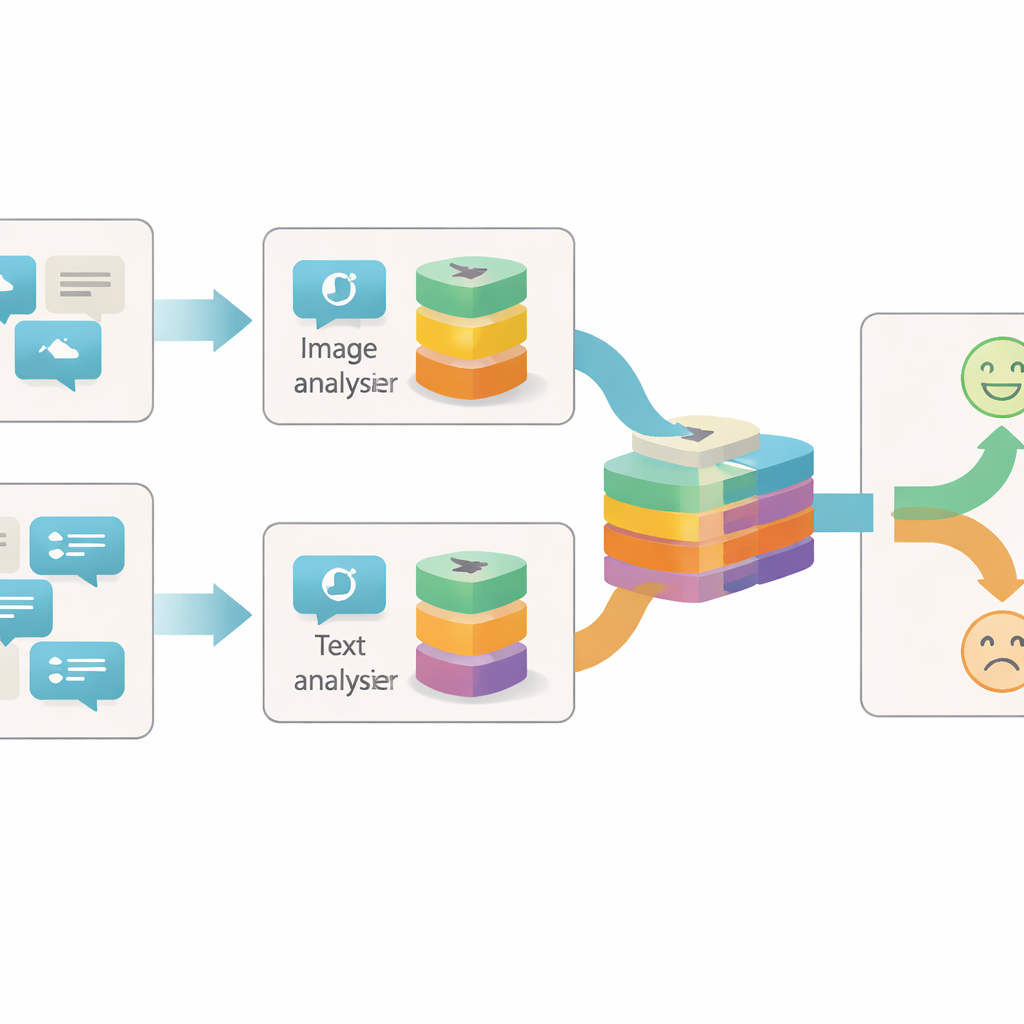
Looking at posts from more than one angle
Most earlier systems for spotting sarcasm online focused on either the text or a simple combination of text and image. They often treated each picture or sentence as a single block of information and looked only at how the two blocks agreed or disagreed. The authors argue that this is too crude: within a single image or sentence, there can be many separate hints about the true feeling behind a post. For example, a bright, cheerful picture might clash with gloomy wording, or a neutral photo might become sarcastic only when paired with a certain phrase. To capture these nuances, a model needs to look inside each piece of content at different levels of detail.
Breaking meaning into small pieces
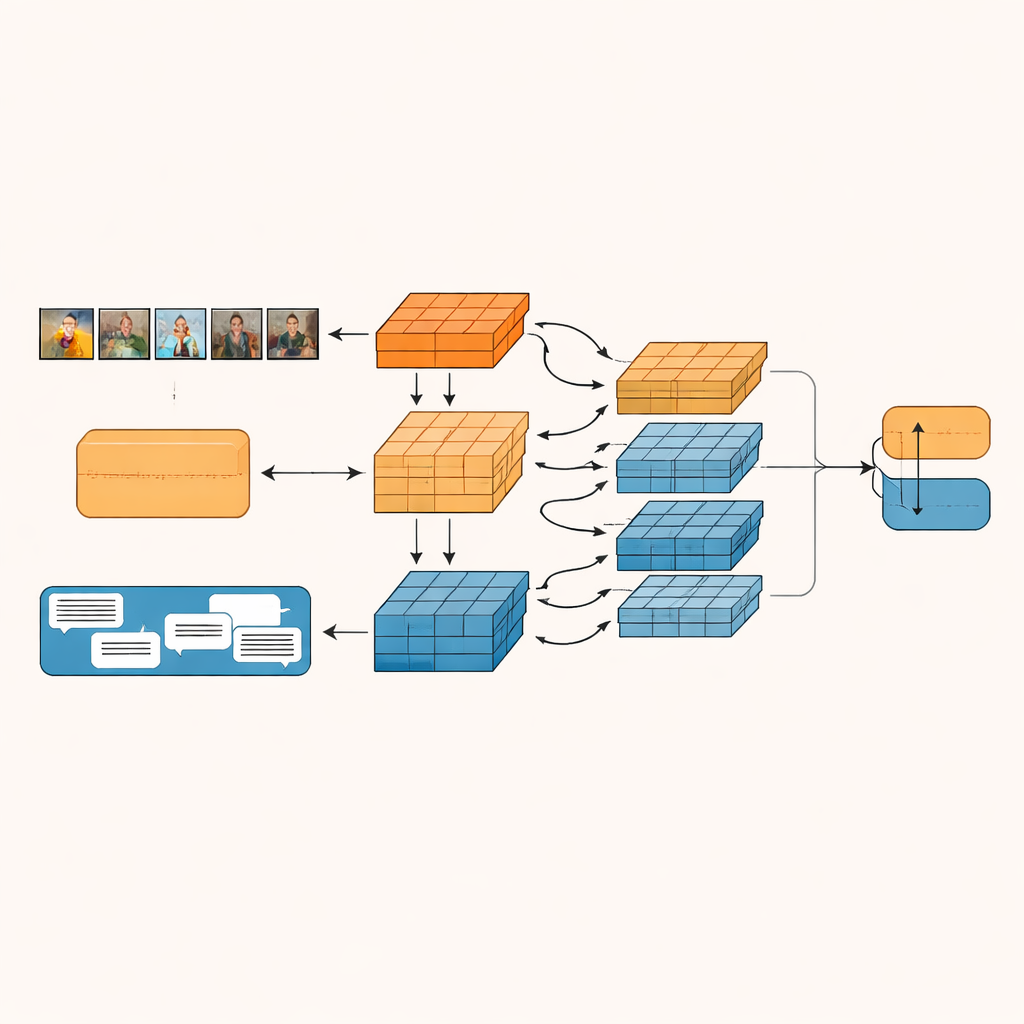
The proposed system, called the Granularity-based Intra-modal and Inter-modal Fusion Network (GIIFN), starts by using powerful pre-trained tools: a vision transformer to understand images and a language model to understand text. It also adds a third source of information by running an automatic captioning tool on the image, creating a short description that acts like external “common sense” about what the picture shows. Instead of treating the resulting feature vectors as a single lump, the model uses a special module to split them into multiple “granularities” — groups of features that are learned automatically. This learnable grouping decides which parts of the representation belong together, forming small semantic units that can highlight, for instance, objects, moods, or relationships inside the content.
Letting images and words talk to each other
Once these semantic units are formed, GIIFN lets them interact in a structured, three-step process. First, it refines what it knows about the image alone, combining coarse overall impressions with fine visual details. Next, it brings the refined image pieces together with the text pieces, using a bidirectional attention mechanism: image units “look at” text units and text units “look at” image units. This mutual exchange helps the system pick up contradictions, such as a stormy sky paired with a cheerful phrase. In the final step, the model folds in the knowledge-rich image caption units, deepening its understanding of what is happening in the scene and how that relates to the written message.
Testing the model in the wild
To see whether these extra layers of analysis really help, the researchers tested GIIFN on a widely used Twitter dataset of posts labeled as sarcastic or not, each containing both text and an image. They compared their system with many existing methods, including strong models that already use graphs, attention, or external knowledge. GIIFN achieved the best scores across standard measures such as accuracy and F1-score, and its results were consistent across different random train–test splits. Careful ablation tests, where individual parts of the system were removed, showed that the learnable granularity grouping brought the largest performance boost, while the fine-grained image details and three-stage fusion also added meaningful gains.
What this means for understanding online emotion
In everyday terms, this work shows that machines can get better at “reading between the lines” by breaking posts into smaller, meaningful pieces and letting images, words, and background knowledge influence one another. GIIFN’s layered design makes it easier for an algorithm to detect when a post’s surface meaning clashes with its underlying intent, a hallmark of sarcasm. Beyond spotting jokes and snark, the same ideas could help future systems interpret online sentiment more reliably, improving tools for content moderation, rumor detection, and mental health monitoring, all while coping with the rich, mixed-media nature of modern social platforms.
Citation: Chen, M., Tang, H., Sun, C. et al. Granularity-guided fusion for multi-modal sentiment understanding. Sci Rep 16, 13286 (2026). https://doi.org/10.1038/s41598-026-43363-5
Keywords: sarcasm detection, multimodal sentiment, social media analysis, deep learning, vision-language models