Clear Sky Science · es
Fusión guiada por granularidad para la comprensión multimodal del sentimiento
Por qué el sarcasmo en línea resulta difícil para las máquinas
El sarcasmo está en todas partes en Internet: una foto de una playa soleada etiquetada con «Qué mal tiempo hoy», o una selfie sonriente acompañada de «Me encantan los atascos». Los humanos captamos el chiste al instante porque percibimos la discordancia entre lo que vemos y lo que leemos. Sin embargo, los ordenadores tienen dificultades con este doble sentido, especialmente cuando las publicaciones combinan imágenes, texto y señales culturales implícitas. Este artículo presenta un nuevo modelo de inteligencia artificial que examina las publicaciones de las redes sociales de forma más estratificada, ayudando a las máquinas a detectar contradicciones sutiles y a comprender mejor cuándo la gente utiliza el sarcasmo.
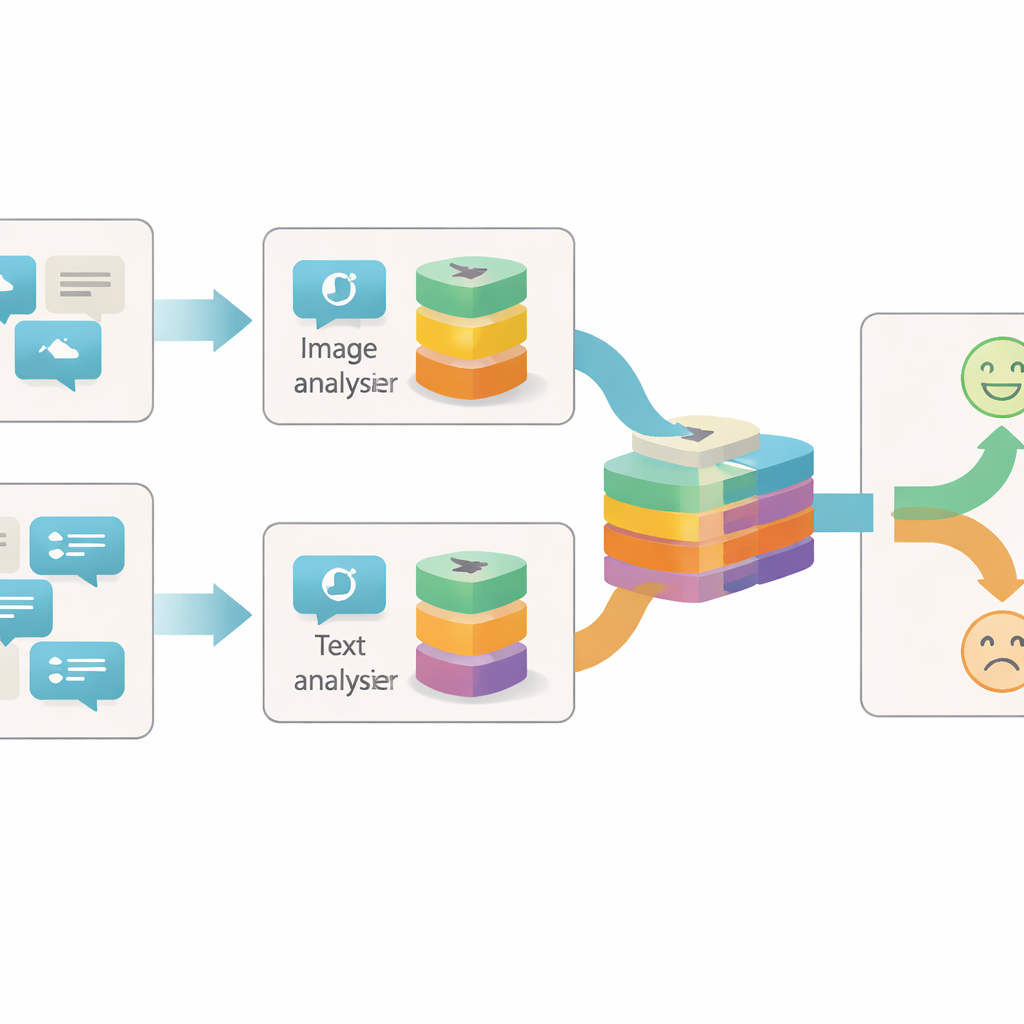
Examinar las publicaciones desde más de un ángulo
La mayoría de los sistemas anteriores para detectar sarcasmo en línea se centraban en el texto o en una combinación simple de texto e imagen. A menudo trataban cada imagen o frase como un único bloque de información y solo analizaban cómo esos bloques concordaban o discrepaban. Los autores sostienen que eso es demasiado burdo: dentro de una sola imagen o frase puede haber muchas pistas separadas sobre el sentimiento real detrás de una publicación. Por ejemplo, una imagen luminosa y alegre puede entrar en conflicto con un texto sombrío, o una foto neutra solo puede volverse sarcástica cuando se empareja con cierta frase. Para captar estas sutilezas, un modelo necesita explorar el interior de cada pieza de contenido en distintos niveles de detalle.
Descomponer el significado en pequeñas piezas
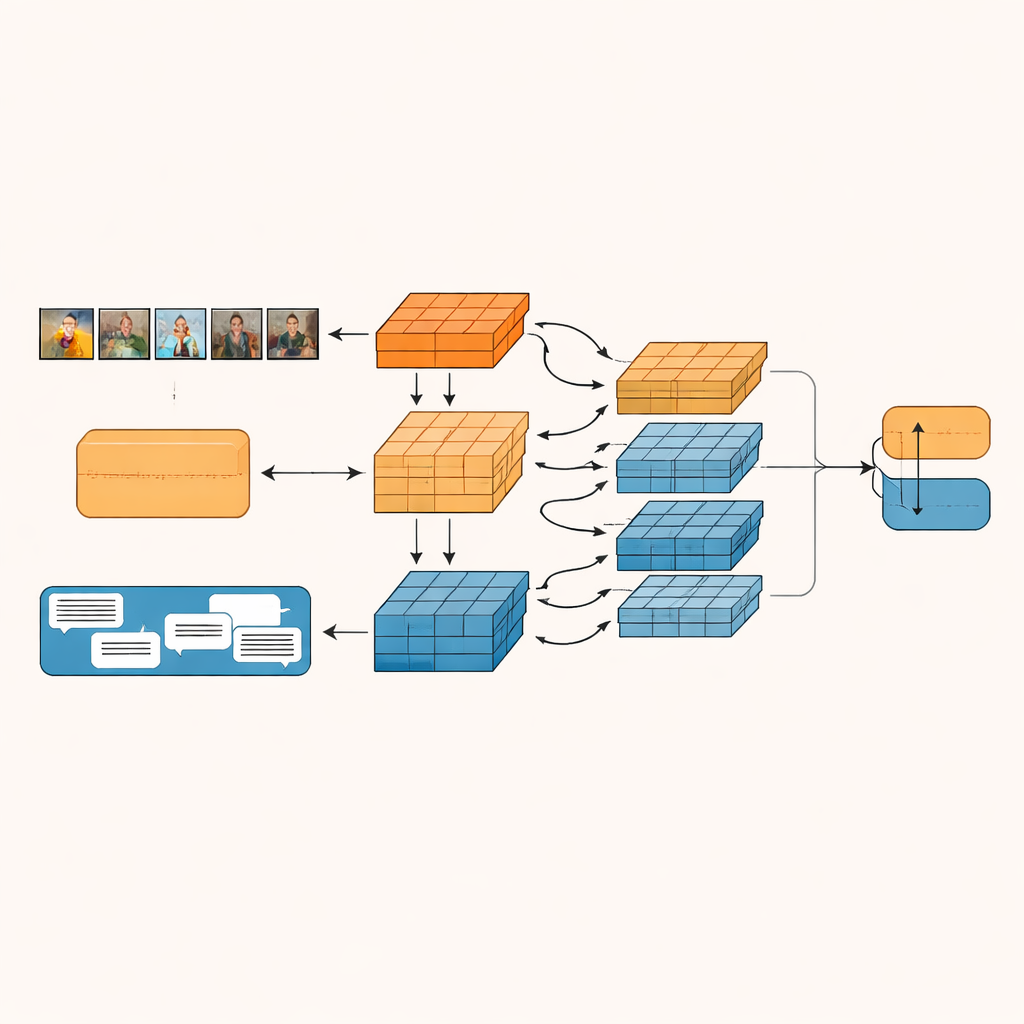
El sistema propuesto, denominado Red de Fusión Intra-modal e Inter-modal basada en Granularidad (GIIFN), comienza utilizando herramientas preentrenadas potentes: un transformador visual para entender las imágenes y un modelo de lenguaje para comprender el texto. También añade una tercera fuente de información ejecutando una herramienta automática de subtitulado sobre la imagen, generando una breve descripción que actúa como “sentido común” externo sobre lo que muestra la foto. En lugar de tratar los vectores de características resultantes como un único bloque, el modelo emplea un módulo especial para dividirlos en múltiples “granularidades”: grupos de características que se aprenden automáticamente. Esta agrupación aprendible decide qué partes de la representación pertenecen juntas, formando pequeñas unidades semánticas que pueden resaltar, por ejemplo, objetos, estados de ánimo o relaciones dentro del contenido.
Permitir que imágenes y palabras dialoguen entre sí
Una vez formadas estas unidades semánticas, GIIFN permite que interactúen mediante un proceso estructurado de tres pasos. Primero, refina lo que sabe solo de la imagen, combinando impresiones generales gruesas con detalles visuales finos. A continuación, reúne las piezas de imagen refinadas con las piezas de texto, usando un mecanismo de atención bidireccional: las unidades de imagen «miran» a las de texto y las unidades de texto «miran» a las de imagen. Este intercambio mutuo ayuda al sistema a captar contradicciones, como un cielo tormentoso emparejado con una frase alegre. En el paso final, el modelo incorpora las unidades ricas en conocimiento procedentes de los subtítulos de imagen, profundizando su comprensión de lo que ocurre en la escena y de cómo eso se relaciona con el mensaje escrito.
Probar el modelo en condiciones reales
Para comprobar si estas capas adicionales de análisis realmente ayudan, los investigadores evaluaron GIIFN en un conjunto de datos de Twitter ampliamente usado, con publicaciones etiquetadas como sarcásticas o no, cada una con texto e imagen. Compararon su sistema con muchos métodos existentes, incluidos modelos potentes que ya emplean grafos, atención o conocimiento externo. GIIFN obtuvo las mejores puntuaciones en medidas estándar como precisión y F1, y sus resultados fueron consistentes a través de distintas particiones aleatorias de entrenamiento y prueba. Pruebas de ablación cuidadosas, en las que se eliminaron partes individuales del sistema, mostraron que la agrupación aprendible por granularidad aportó la mayor mejora en rendimiento, mientras que los detalles finos de la imagen y la fusión en tres etapas también proporcionaron ganancias significativas.
Qué significa esto para la comprensión de las emociones en línea
En términos cotidianos, este trabajo muestra que las máquinas pueden mejorar en «leer entre líneas» si descomponen las publicaciones en piezas más pequeñas y significativas y permiten que imágenes, palabras y conocimientos contextuales se influyan mutuamente. El diseño por capas de GIIFN facilita que un algoritmo detecte cuando el significado superficial de una publicación choca con su intención subyacente, una característica distintiva del sarcasmo. Más allá de detectar bromas e ironías, las mismas ideas podrían ayudar a futuros sistemas a interpretar el sentimiento en línea con mayor fiabilidad, mejorando herramientas para la moderación de contenido, la detección de rumores y el seguimiento de la salud mental, todo ello afrontando la rica y multimodal naturaleza de las plataformas sociales modernas.
Cita: Chen, M., Tang, H., Sun, C. et al. Granularity-guided fusion for multi-modal sentiment understanding. Sci Rep 16, 13286 (2026). https://doi.org/10.1038/s41598-026-43363-5
Palabras clave: detección de sarcasmo, sentimiento multimodal, análisis de redes sociales, aprendizaje profundo, modelos visión-lenguaje