Clear Sky Science · zh
用于共聚类的自监督非支配排序模型
在复杂数据中发现隐含群体
现代数据表——例如用户的电影评分、病人的基因表达或顾客的商品购买记录——往往庞大且错综复杂,很难看出明确模式。本文提出了一种揭示此类隐含结构的新方法,称为用于共聚类的自监督非支配排序模型(SNSC)。SNSC并不只是对人或物品单独分组,而是同时寻找两者的有意义分组,揭示哪些行子集和列子集真正属于同一类。对于关心更智能的算法如何从现有数据中挖掘更多洞见的读者来说,这项工作展示了如何将进化思想、自监督学习和多目标优化结合成一个强有力的工具。
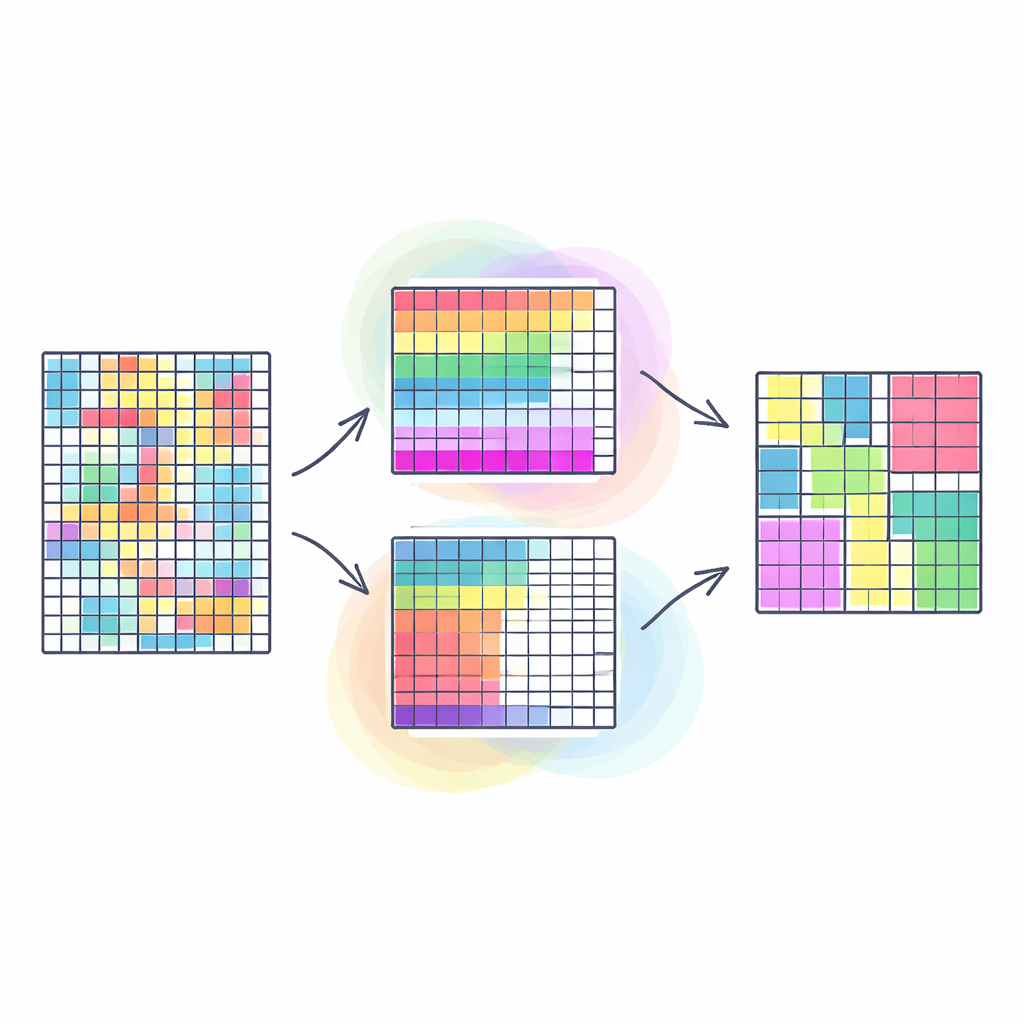
为何同时分组行和列很重要
传统的聚类方法通常只对表格中的相似行进行分组——例如具有相似购买习惯的顾客——并把所有列视为同等重要。共聚类更进一步:它同时对行和列进行分组,从而发现特定行子集在特定列子集上表现相似的数据块。这种“二重分组”常常能揭示更清晰、更有用的模式,例如社交网络中的群体或图像中的分段。然而,大多数现有方法试图将这个自然多面的任务压缩为单一目标,这可能会简化现实,并使结果质量对任意权重选择高度敏感。
把共聚类转化为多个目标同时优化
作者将共聚类视为一个真正的多目标任务。他们的SNSC模型同时优化四个目标:样本的紧密度、特征组的分离度,以及两者与直接从数据中学习到的相似性信息的一致性。SNSC并不使用人工提供的标签,而是基于原始数据空间中样本与特征的接近程度构建两张相似性图——一张针对样本,一张针对特征。这些图作为一种内在引导:在原始数据上看起来相似的样本或特征会被温和地鼓励落入同一簇,而不将方法变成完全监督的系统。通过在全局结构与这些局部提示之间取得平衡,SNSC旨在找到既紧凑又忠实于数据内部几何结构的簇。
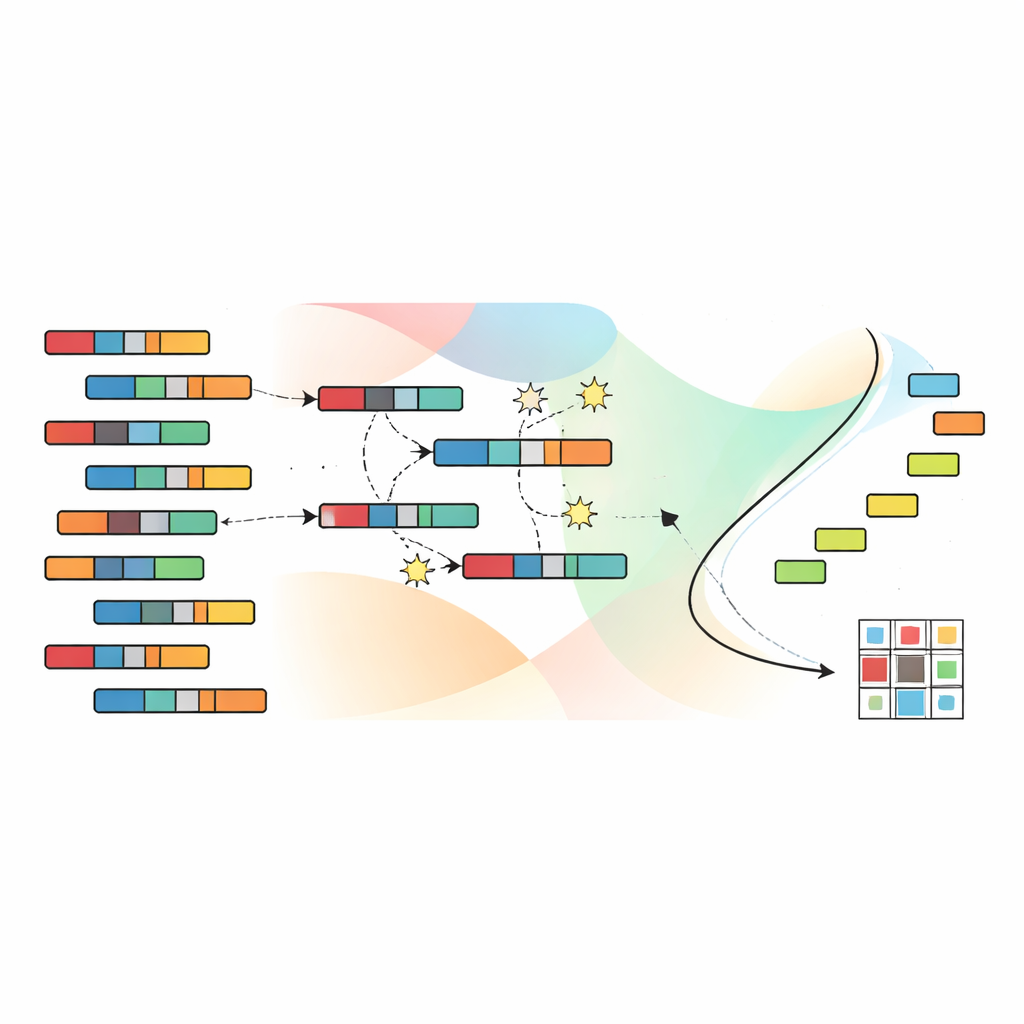
让进化搜索更好的分组
为了在庞大的可能分组空间中导航,作者依赖一种受自然选择启发的遗传算法。每个候选解都编码了样本和特征到簇的完整分配。一组这样的候选解在多代中演化:有前景的解被组合并做轻微扰动,而效果较差的被淘汰。关键在于,SNSC使用一种称为非支配排序的技术,它不会将四个目标合并成单一分数。相反,它保留一组“非支配”解,其中没有一个在所有目标上都严格劣于另一个。目标空间中的参考点有助于保持解的多样分布,从而避免算法陷入狭窄的可能性区域。
在无标签情况下学习良好的起点
SNSC的一个关键创新在于如何初始化这一进化搜索。模型没有从纯随机猜测开始,而是采用一种混合策略。初始解的一半是随机生成的,提供广泛的探索;另一半则通过对数据及其转置应用标准聚类方法(如k均值、模糊聚类及相关技术)生成。这些“自举”候选解作为从数据本身派生的自监督提示,通常使进化过程从更接近有用模式的起点开始。实验证明,这种随机性与自监督的结合既提高了鲁棒性,又降低了陷入差的局部最优的风险。
在真实数据集上的测试及其意义
作者在十四个来自图像、多媒体和经典机器学习集合的真实数据集上评估了SNSC,并将其与几种知名的共聚类方法进行了比较。使用常用的聚类质量指标,如准确率和平方误差和的变体,SNSC经常优于替代方法,并在许多数据集上表现出统计显著的提升。尽管它不是最快的方法——其遗传搜索和相似性构建在计算上更为繁重——但它提供了一致强劲、稳定的结果,表明当质量比计算速度更重要时,它尤为适用。
更清晰的模式与计算代价
简而言之,论文表明将共聚类视作多目标问题,并让进化过程搜索均衡解,可以在复杂数据表中发现更清晰、更可靠的模式。自监督相似性图帮助算法利用数据中已存在的结构,而无需人工标签。代价是计算开销:SNSC比更简单的方法需要更多时间和资源,尤其是在非常大的数据集上。作者建议未来的工作应着重提高可扩展性,例如加速遗传搜索或并行运行。即便如此,对于那些在两类实体间理解复杂关系至关重要的应用,SNSC提供了一种有前景且细致的方式,在表面混乱中看到秩序。
引用: Li, X., Wang, H., Yang, W. et al. Self-supervised non-dominated sorted model for co-clustering. Sci Rep 16, 12088 (2026). https://doi.org/10.1038/s41598-026-42498-9
关键词: 共聚类, 多目标优化, 自监督学习, 遗传算法, 数据挖掘