Clear Sky Science · ar
نموذج فرز غير مهيمن ذاتي الإشراف للتجميع المشترك
اكتشاف المجموعات الخفية في البيانات المعقدة
جداول البيانات الحديثة — مثل تقييمات الأفلام من المستخدمين، أو الجينات عبر المرضى، أو المنتجات عبر العملاء — كبيرة ومعقّدة لدرجة تجعل رؤية نمط واضح أمراً صعباً. تقدم هذه الورقة طريقة جديدة للكشف عن هذه البنية الخفية تُدعى نموذج الفرز غير المهيمن ذاتي الإشراف للتجميع المشترك (SNSC). بدلاً من تجميع الأشخاص فقط أو العناصر فقط، يبحث SNSC عن مجموعات ذات مغزى لكلتيهما في آن واحد، كاشفاً أي مجموعات فرعية من الصفوف والأعمدة تنتمي فعلاً معاً. للقراء المهتمين بكيفية تمكين الخوارزميات الأذكى من استخلاص رؤى أكثر من بيانات موجودة، توضح هذه الدراسة كيف يمكن دمج أفكار من التطور، والتعلّم الذاتي الإشراف، والتحسين متعدد الأهداف في أداة قوية.
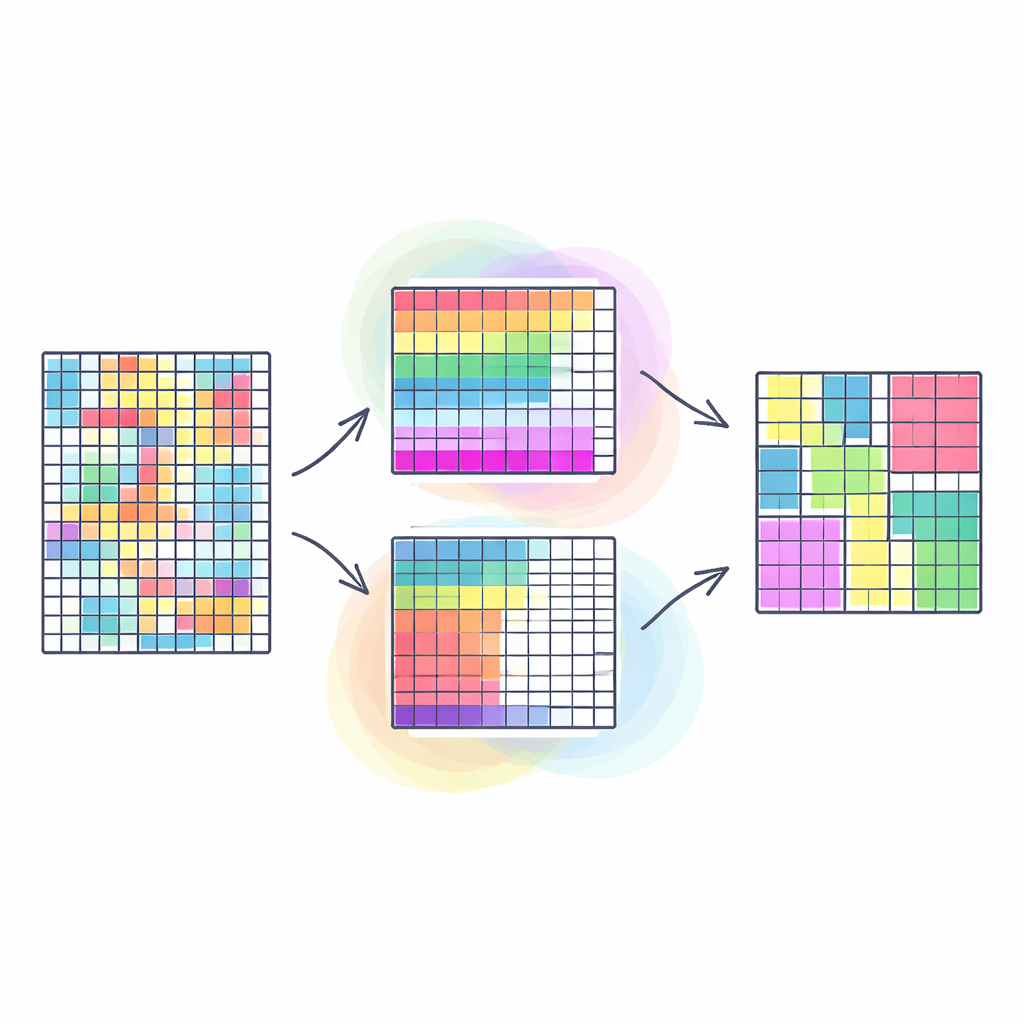
لماذا يهم تجميع الصفوف والأعمدة معاً
تجمع طرق التكتّل التقليدية عادةً الصفوف المتشابهة في جدول — مثل العملاء ذوي أنماط الشراء المتشابهة — معاملةً كل الأعمدة على أنها مهمة بنفس الدرجة. التجميع المشترك يذهب خطوة أبعد: فهو يجمع الصفوف والأعمدة معاً في آنٍ واحد، ليكشف عن كتل من البيانات حيث يسلك مجموعة محددة من العملاء سلوكاً متشابهًا تجاه مجموعة محددة من المنتجات. غالباً ما تكشف هذه «المجموعة المزدوجة» عن أنماط أوضح وأكثر فائدة، مثل المجتمعات في الشبكات الاجتماعية أو المقاطع في الصور. مع ذلك، تحاول معظم الأساليب الحالية ضغط هذه المسألة متعددة الوجوه في هدف واحد، ما قد يبسط الواقع بشكل مفرط ويجعل جودة النتائج حساسة لاختيارات وزنية عشوائية.
تحويل التجميع المشترك إلى أهداف متعددة في نفس الوقت
يعامل المؤلفون التجميع المشترك كمهمة ذات أهداف متعددة حقيقية. يقوم نموذج SNSC بتحسين أربعة أهداف في آنٍ واحد: مدى تماسك تجمّعات العينات، ومدى فصل مجموعات الميزات بوضوح، ومدى توافق كلاهما مع معلومات التشابه المستخلصة مباشرة من البيانات. بدلاً من استخدام تسميات بشرية، يبني SNSC خريطتي تشابه — واحدة للعينات وأخرى للميزات — اعتماداً على مدى قربها من بعضها البعض في فضاء البيانات الأصلي. تعمل هذه الخرائط كنوع من الإرشاد الداخلي: تُشجّع العينات أو الميزات التي تبدو متشابهة وفق البيانات الخام بلطف على الانتماء إلى نفس العنقود، دون تحويل الطريقة إلى نظام مُشرف بالكامل. من خلال موازنة البنية العامة مع هذه الإشارات المحلية، يسعى SNSC إلى إيجاد جماعات تكون مدمجة ومخلصة للهندسة الداخلية للبيانات.
السماح للتطور بالبحث عن تجميعات أفضل
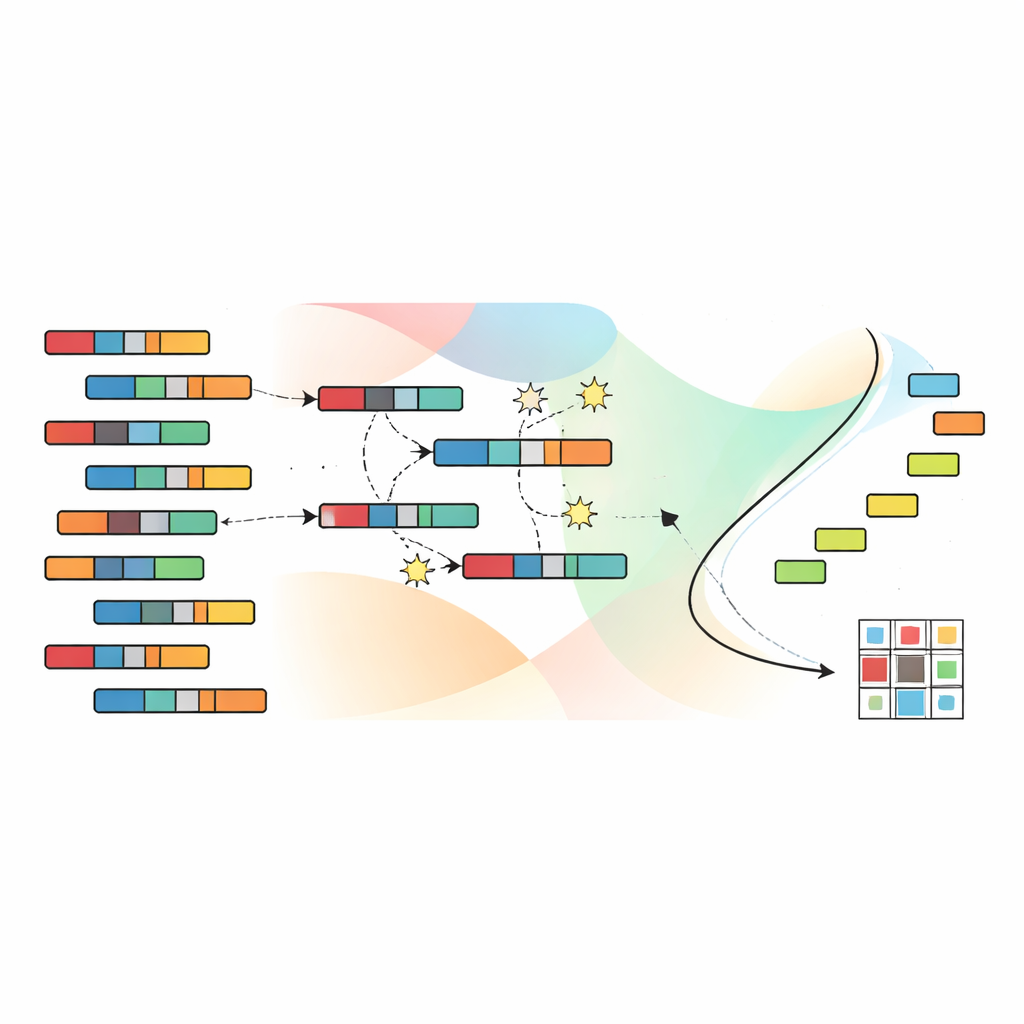
للتنقل في فضاء التجميعات الممكنة الهائل، يعتمد المؤلفون على خوارزمية جينية مستلهمة من الانتقاء الطبيعي. يُشفّر كل حل محتمل توزيعًا كاملاً للعينات والميزات إلى عناقيد. تتطور مجموعة من هذه الحلول عبر أجيال عديدة: تُدمَج الحلول الواعدة وتُطرأ عليها طفرات طفيفة، بينما تُستبعد الحلول الأقل فعالية. والأهم أن SNSC يستخدم تقنية تُسمى الفرز غير المهيمن، التي لا تُجمّع الأهداف الأربعة في درجة واحدة. بدلاً من ذلك، يحتفظ بمجموعة من الحلول «غير المهيمنة» حيث لا يُعتبر أي منها أسوأ بشكل قاطع من آخر عبر جميع الأهداف. تساعد نقاط المرجع في فضاء الأهداف على الحفاظ على تنوّع الحلول، حتى لا تحصر الخوارزمية نفسها في منطقة ضيقة من الاحتمالات.
تعلّم نقاط بداية جيدة دون تسميات
ابتكار رئيسي في SNSC هو كيفية تهيئة هذا البحث التطوري. بدلاً من البدء بتخمينات عشوائية بحتة، يستخدم النموذج استراتيجية هجينة. نصف الحلول الأولية عشوائية، مما يوفر استكشافًا واسعًا. تُنشأ النصف الآخر بتطبيق طرق تجمع معيارية — مثل كاي-مينز، والتجميع الضبابي، وتقنيات ذات صلة — على البيانات وعلى مصفوفة المعطيات المعكوسة. تعمل هذه الحلول «المُرتكزة» كإشارات ذاتية الإشراف مشتقة من البيانات نفسها، وغالباً ما تُقود عملية التطور بدايةً نحو أنماط مفيدة. تُظهر التجارب أن هذا المزج من العشوائية والتعلّم الذاتي يُحسّن المتانة ويقلل خطر الوقوع في أمثلية محلية ضعيفة.
الاختبار على مجموعات بيانات حقيقية وما يعنيه ذلك
يقيم المؤلفون أداء SNSC على أربعة عشر مجموعة بيانات حقيقية من مجالات الصور والوسائط المتعددة ومجموعات تعلم الآلة الكلاسيكية، ويقارنونه بعدة طرق تجميع مشترك معروفة. باستخدام مقاييس قبول شائعة لجودة التكتّل، مثل الدقة وتباينات مجموع المربعات، يتفوّق SNSC في كثير من الأحيان على البدائل ويُظهر مكاسب ذات دلالة إحصائية على العديد من المجموعات. ورغم أنه ليس الأسرع — لأن البحث الجيني وبناء خرائط التشابه أكثر ثقلًا حسابياً — فإنه يقدم نتائج قوية ومستقرة باستمرار، ما يجعله مناسباً بشكل خاص عندما تكون الجودة أهم من سرعة التنفيذ الخام.
أنماط أوضح بتكلفة حسابية
بعبارة بسيطة، توضح الورقة أن معاملة التجميع المشترك كمشكلة متعددة الأهداف وترك عملية تطورية تبحث عن حلول متوازنة يمكنها الكشف عن أنماط أوضح وأكثر موثوقية في جداول البيانات المعقّدة. تساعد خرائط التشابه الذاتية الإشراف الخوارزمية على استخدام البنية الموجودة بالفعل في البيانات دون الحاجة إلى تسميات بشرية. المقابل هو التكلفة الحسابية: يتطلب SNSC وقتًا وموارد أكبر من الطرق الأبسط، خاصة على مجموعات البيانات الكبيرة جداً. يشير المؤلفون إلى أن الأعمال المستقبلية ينبغي أن تركز على جعل النهج أكثر قابلية للتوسّع، على سبيل المثال بتسريع البحث الجيني أو تشغيله بالتوازي. ومع ذلك، للتطبيقات التي يهم فيها فهم العلاقات المعقّدة بين نوعين من الكيانات، يقدم SNSC طريقة واعدة وذات نبرة دقيقة لرؤية النظام وسط الفوضى الظاهرة.
الاستشهاد: Li, X., Wang, H., Yang, W. et al. Self-supervised non-dominated sorted model for co-clustering. Sci Rep 16, 12088 (2026). https://doi.org/10.1038/s41598-026-42498-9
الكلمات المفتاحية: التجميع المشترك, التحسين متعدد الأهداف, التعلّم الذاتي الإشراف, الخوارزميات الجينية, تنقيب البيانات