Clear Sky Science · de
Selbstüberwachtes, nicht-dominiertes Sortiermodell für Co-Clustering
Verborgene Gruppen in komplexen Daten finden
Moderne Datentabellen — etwa Filmratings von Nutzern, Gene von Patientinnen oder Produkte von Kundinnen — sind so groß und verwoben, dass sich kaum klare Muster erkennen lassen. Dieser Artikel stellt eine neue Methode vor, um solche verborgenen Strukturen aufzudecken: das Selbstüberwachte, Nicht-dominiert Sortierte Modell für Co‑Clustering (SNSC). Anstatt nur Personen oder nur Objekte zu gruppieren, sucht SNSC gleichzeitig nach sinnvollen Gruppen auf beiden Seiten und zeigt, welche Teilmengen von Zeilen und Spalten wirklich zusammengehören. Für Leserinnen und Leser, die wissen wollen, wie intelligentere Algorithmen mehr Einsichten aus vorhandenen Daten gewinnen können, demonstriert diese Arbeit, wie Konzepte aus Evolution, selbstüberwachtem Lernen und Multi‑Objective‑Optimierung zu einem leistungsfähigen Werkzeug kombiniert werden können.
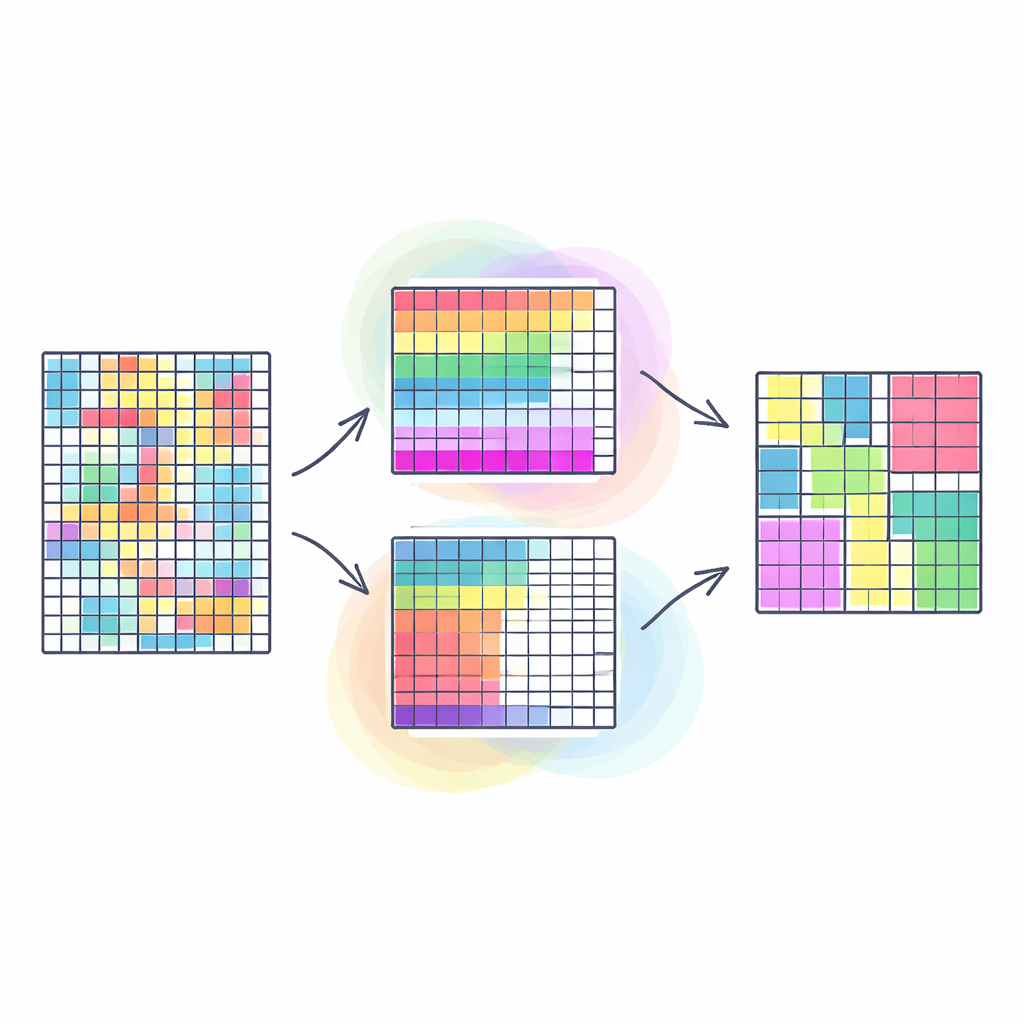
Warum das gemeinsame Gruppieren von Zeilen und Spalten wichtig ist
Traditionelle Clustering‑Methoden gruppieren meist ähnliche Zeilen in einer Tabelle — zum Beispiel Kundinnen mit ähnlichem Kaufverhalten — und behandeln alle Spalten als gleich wichtig. Co‑Clustering geht einen Schritt weiter: Es gruppiert gleichzeitig Zeilen und Spalten, sodass Blöcke von Daten entdeckt werden, in denen eine bestimmte Teilmenge von Kundinnen sich bei einer bestimmten Teilmenge von Produkten ähnlich verhält. Diese Art der „doppelten Gruppierung“ legt oft klarere, nützlichere Muster offen, etwa Gemeinschaften in sozialen Netzwerken oder Segmente in Bildern. Allerdings versuchen die meisten bestehenden Ansätze, dieses von Natur aus vielschichtige Problem auf ein einziges Ziel zu reduzieren, was die Realität vereinfachen und die Ergebnisqualität sehr empfindlich gegen willkürliche Gewichtungsentscheidungen machen kann.
Co‑Clustering als gleichzeitiges Mehrzielproblem
Die Autorinnen und Autoren betrachten Co‑Clustering als echtes Mehrzielproblem. Ihr SNSC‑Modell optimiert vier Ziele gleichzeitig: wie kompakt die Proben gruppiert sind, wie sauber die Merkmalsgruppen getrennt sind und wie gut beide mit Ähnlichkeitsinformationen übereinstimmen, die direkt aus den Daten gelernt wurden. Anstatt von Menschen bereitgestellte Labels zu verwenden, baut SNSC zwei Ähnlichkeitskarten auf — eine für Proben und eine für Merkmale — basierend darauf, wie nah sie sich im ursprünglichen Datenraum sind. Diese Karten dienen als eine Art interne Orientierung: Proben oder Merkmale, die laut Rohdaten ähnlich erscheinen, werden sanft dazu angeregt, in denselben Cluster zu fallen, ohne das Verfahren in ein voll überwachtes System zu verwandeln. Durch das Ausbalancieren der Gesamtstruktur mit diesen lokalen Hinweisen zielt SNSC darauf ab, Cluster zu finden, die sowohl kompakt als auch treu zur inneren Geometrie der Daten sind.
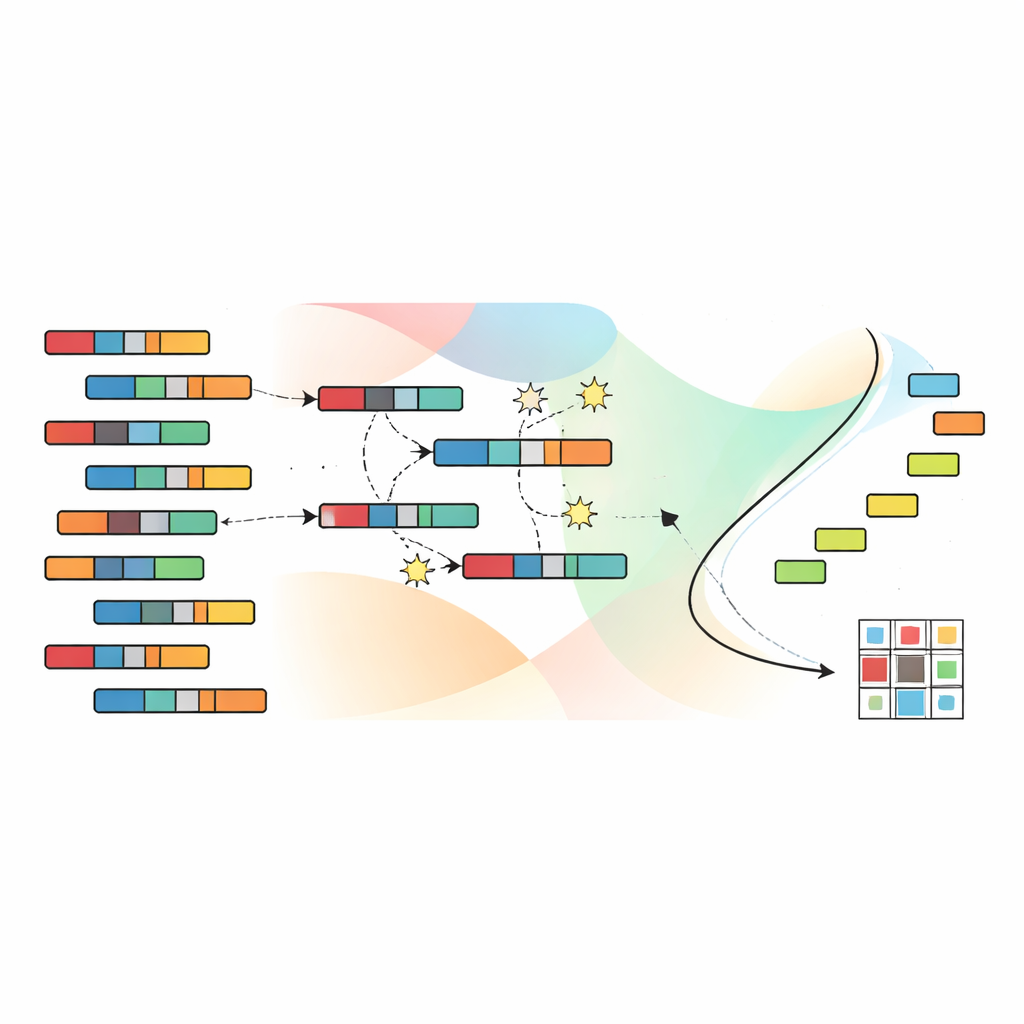
Evolution die Suche nach besseren Gruppierungen überlassen
Um den riesigen Raum möglicher Gruppierungen zu durchsuchen, greifen die Autorinnen und Autoren auf einen genetischen Algorithmus zurück, inspiriert von natürlicher Selektion. Jede Kandidatenlösung codiert eine vollständige Zuordnung von Proben und Merkmalen zu Clustern. Eine Population solcher Kandidaten wird über viele Generationen weiterentwickelt: vielversprechende Lösungen werden kombiniert und leicht verändert, während weniger effektive verworfen werden. Entscheidendes Element von SNSC ist eine Technik namens nicht‑dominierte Sortierung, die die vier Ziele nicht zu einer einzigen Kennzahl zusammenfasst. Stattdessen bleibt eine Menge von „nicht‑dominierten“ Lösungen erhalten, bei denen keine strikt schlechter ist als eine andere über alle Ziele hinweg. Referenzpunkte im Zielraum helfen, eine vielfältige Verteilung von Lösungen zu bewahren, sodass der Algorithmus nicht in einer engen Region des Lösungsraums stecken bleibt.
Gute Startpunkte ohne Labels lernen
Eine Schlüsselinnovation von SNSC ist, wie die evolutionäre Suche initialisiert wird. Anstatt rein zufällig zu starten, verwendet das Modell eine hybride Strategie. Die Hälfte der Anfangslösungen ist zufällig und ermöglicht breite Exploration. Die andere Hälfte entsteht durch Anwendung gängiger Clustering‑Methoden — etwa k‑means, Fuzzy‑Clustering und verwandte Verfahren — auf die Daten und deren Transponierte. Diese „bootstrappten“ Kandidaten fungieren als selbstüberwachte Hinweise, die aus den Daten selbst abgeleitet sind, und bringen den Evolutionsprozess oft näher an nützliche Muster. Experimente zeigen, dass diese Mischung aus Zufall und Selbstüberwachung sowohl die Robustheit verbessert als auch das Risiko verringert, in schlechten lokalen Optima stecken zu bleiben.
Tests an realen Datensätzen und ihre Bedeutung
Die Autorinnen und Autoren evaluieren SNSC an vierzehn realen Datensätzen aus den Bereichen Bild, Multimedia und klassischen Machine‑Learning‑Sammlungen und vergleichen es mit mehreren bekannten Co‑Clustering‑Methoden. Mit üblichen Maßnahmen zur Bewertung von Clustering‑Qualität, wie Genauigkeit und Varianten der Summe quadratischer Fehler, übertrifft SNSC häufig die Alternativen und zeigt auf vielen Datensätzen statistisch signifikante Verbesserungen. Zwar ist es nicht die schnellste Methode — die genetische Suche und die Ähnlichkeitskonstruktion sind rechnerisch aufwändiger — doch liefert es durchgehend starke, stabile Ergebnisse, was darauf hindeutet, dass es besonders dann geeignet ist, wenn Qualität wichtiger ist als rohe Geschwindigkeit.
Klarere Muster zum Preis höherer Rechenkosten
Einfach gesagt zeigt der Artikel, dass die Behandlung von Co‑Clustering als Mehrzielproblem und die Überlassung der Suche an einen evolutionären Prozess ausgewogene Lösungen zutage fördern können, die klarere und verlässlichere Muster in komplexen Datentabellen offenlegen. Die selbstüberwachten Ähnlichkeitskarten helfen dem Algorithmus, die bereits in den Daten vorhandene Struktur zu nutzen, ohne menschliche Labels zu benötigen. Der Ausgleich besteht in höheren Rechenkosten: SNSC verlangt mehr Zeit und Ressourcen als einfachere Methoden, besonders bei sehr großen Datensätzen. Die Autorinnen und Autoren schlagen vor, künftige Arbeit auf bessere Skalierbarkeit zu richten, etwa durch Beschleunigung der genetischen Suche oder parallele Ausführung. Dennoch bietet SNSC für Anwendungen, bei denen das Verständnis komplexer Beziehungen zwischen zwei Entitätstypen wichtig ist, eine vielversprechende, nuancierte Möglichkeit, Ordnung im scheinbaren Chaos zu erkennen.
Zitation: Li, X., Wang, H., Yang, W. et al. Self-supervised non-dominated sorted model for co-clustering. Sci Rep 16, 12088 (2026). https://doi.org/10.1038/s41598-026-42498-9
Schlüsselwörter: Co-Clustering, Multi-Objectives-Optimierung, selbstüberwachtes Lernen, Genetische Algorithmen, Data Mining