Clear Sky Science · en
Self-supervised non-dominated sorted model for co-clustering
Finding Hidden Groups in Complex Data
Modern data tables—such as movie ratings by users, genes by patients, or products by customers—are so large and tangled that it’s hard to see any clear pattern. This paper introduces a new way to uncover such hidden structure, called the Self-supervised Non-dominated Sorted Model for Co-clustering (SNSC). Instead of grouping only people or only items, SNSC looks for meaningful groups of both at the same time, revealing which subsets of rows and columns truly belong together. For readers curious about how smarter algorithms can squeeze more insight out of existing data, this work shows how ideas from evolution, self-supervised learning, and multi-objective optimization can be combined into a powerful tool.
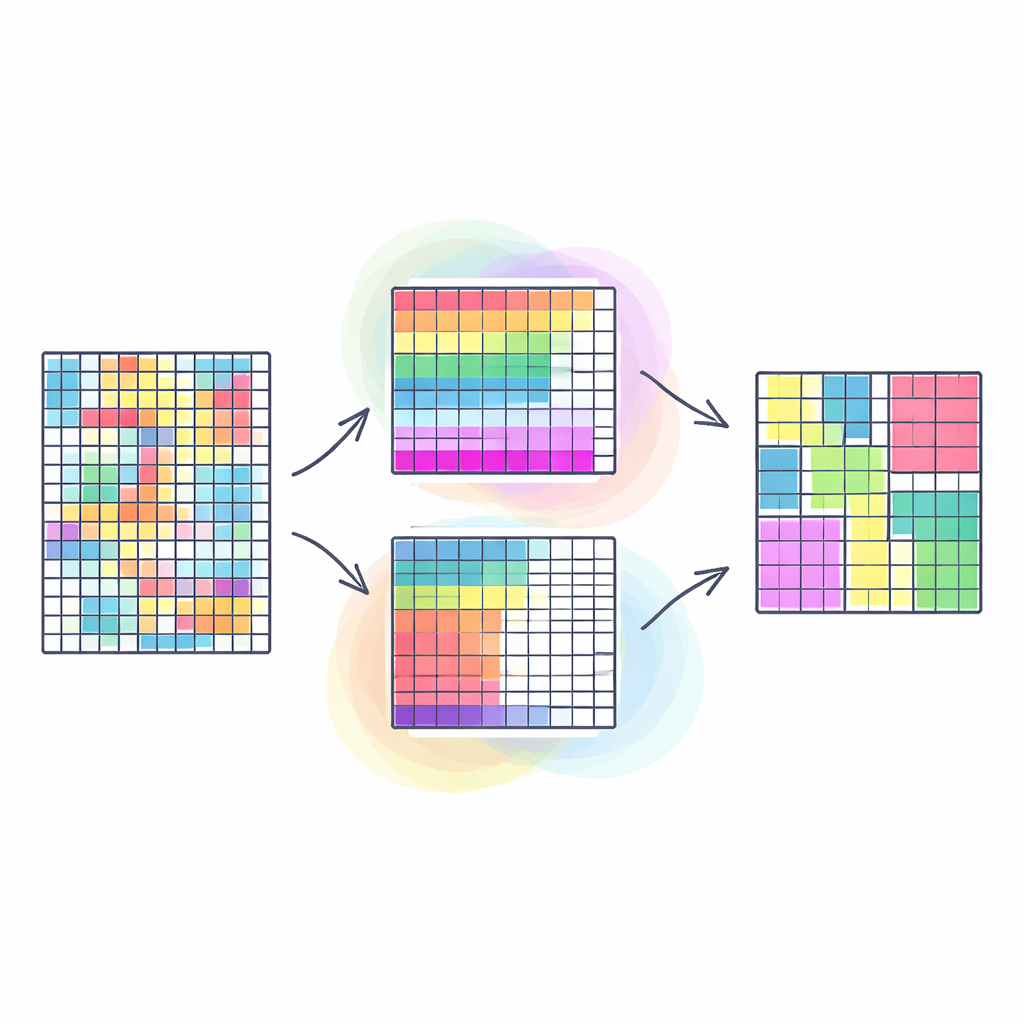
Why Grouping Rows and Columns Together Matters
Traditional clustering methods usually group similar rows in a table—for example, customers with similar purchasing habits—treating all columns as equally important. Co-clustering goes a step further: it simultaneously groups both rows and columns, so that we discover blocks of data where a particular subset of customers behaves similarly on a particular subset of products. This kind of “double grouping” often exposes clearer, more useful patterns, such as communities in social networks or segments in images. However, most existing approaches try to squeeze this naturally multi-faceted problem into a single goal, which can oversimplify reality and make the quality of the results highly sensitive to arbitrary weighting choices.
Turning Co-clustering into Many Goals at Once
The authors treat co-clustering as a true multi-goal task. Their SNSC model optimizes four objectives at the same time: how tightly samples are grouped, how cleanly feature groups are separated, and how well both agree with similarity information learned directly from the data. Instead of using human-provided labels, SNSC builds two similarity maps—one for samples and one for features—based on how close they are to each other in the original data space. These maps serve as a kind of internal guidance: samples or features that look alike according to the raw data are gently encouraged to land in the same cluster, without turning the method into a fully supervised system. By balancing overall structure with these local hints, SNSC aims to find clusters that are both compact and faithful to the data’s inner geometry.
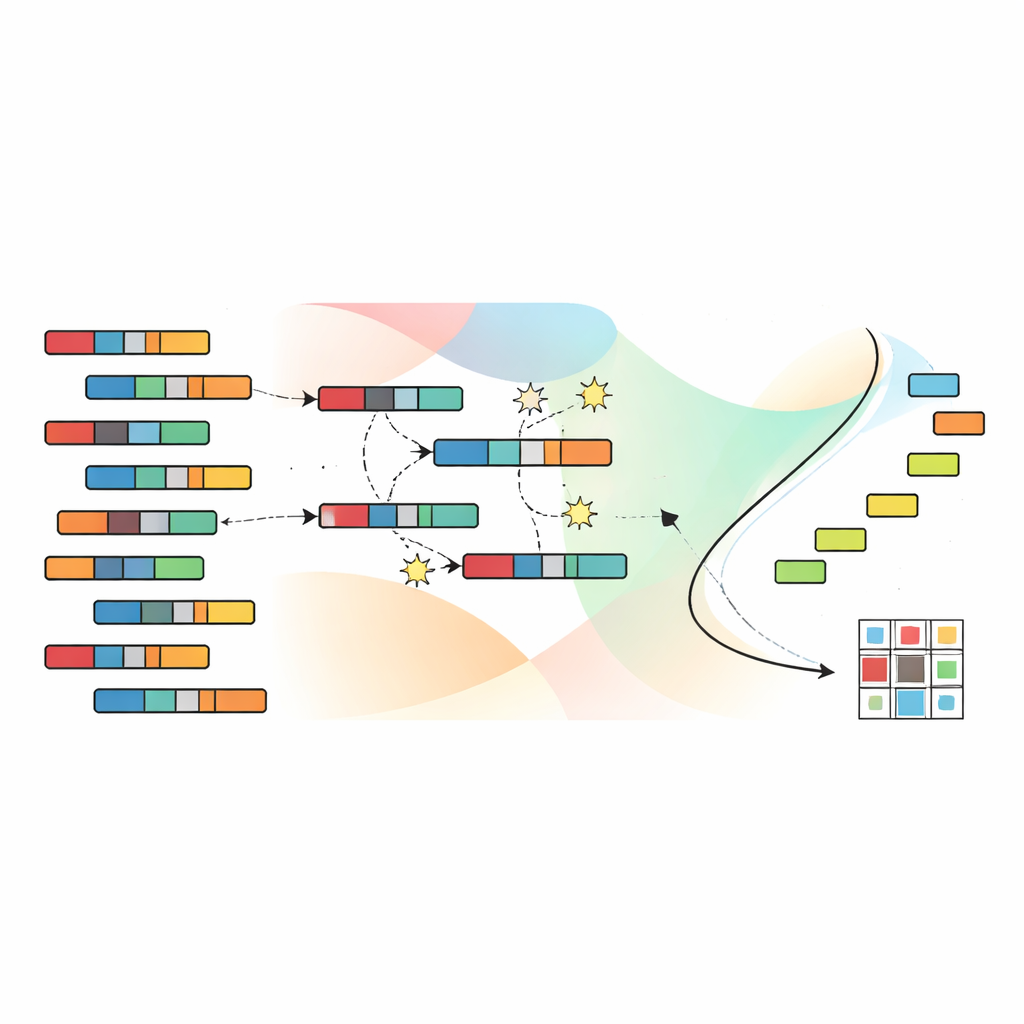
Letting Evolution Search for Better Groupings
To navigate the huge space of possible groupings, the authors rely on a genetic algorithm, inspired by natural selection. Each candidate solution encodes a complete assignment of samples and features to clusters. A population of such candidates is evolved over many generations: promising solutions are combined and slightly perturbed, while less effective ones are discarded. Crucially, SNSC uses a technique called non-dominated sorting, which does not collapse the four objectives into a single score. Instead, it keeps a set of “non-dominated” solutions where none is strictly worse than another across all goals. Reference points in objective space help maintain a diverse spread of solutions, so the algorithm does not get stuck in one narrow region of possibilities.
Learning Good Starting Points Without Labels
A key innovation in SNSC is how it initializes this evolutionary search. Rather than starting from purely random guesses, the model uses a hybrid strategy. Half of the initial solutions are random, providing broad exploration. The other half are created by applying standard clustering methods—such as k-means, fuzzy clustering, and related techniques—to the data and its transpose. These “bootstrapped” candidates act as self-supervised hints derived from the data itself, often starting the evolution process closer to useful patterns. Experiments show that this blend of randomness and self-supervision both improves robustness and reduces the risk of settling into poor local optima.
Testing on Real Datasets and What It Means
The authors evaluate SNSC on fourteen real-world datasets from image, multimedia, and classic machine-learning collections, comparing it against several well-known co-clustering methods. Using commonly accepted measures of clustering quality, such as accuracy and variants of the sum of squared errors, SNSC frequently outperforms the alternatives and shows statistically significant gains on many datasets. While it is not the fastest method—its genetic search and similarity construction are computationally heavier—it delivers consistently strong, stable results, suggesting it is particularly suitable when quality is more important than raw speed.
Clearer Patterns at a Computational Price
In plain terms, the paper shows that treating co-clustering as a many-goal problem and letting an evolutionary process search for balanced solutions can uncover clearer, more reliable patterns in complex tables of data. The self-supervised similarity maps help the algorithm use the structure already present in the data, without requiring human labels. The trade-off is computational cost: SNSC demands more time and resources than simpler methods, especially on very large datasets. Future work, the authors suggest, should focus on making the approach more scalable, for example by speeding up the genetic search or running it in parallel. Even so, for applications where understanding intricate relationships between two kinds of entities matters, SNSC offers a promising, nuanced way to see order in apparent chaos.
Citation: Li, X., Wang, H., Yang, W. et al. Self-supervised non-dominated sorted model for co-clustering. Sci Rep 16, 12088 (2026). https://doi.org/10.1038/s41598-026-42498-9
Keywords: co-clustering, multi-objective optimization, self-supervised learning, genetic algorithms, data mining