Clear Sky Science · pl
Samonadzorowany model sortowania niedominowanego dla współgrupowania
Odnajdywanie ukrytych grup w złożonych danych
Współczesne tabele danych — na przykład oceny filmów przez użytkowników, ekspresja genów u pacjentów czy zakupy produktów przez klientów — są tak obszerne i splątane, że trudno dostrzec wyraźne wzorce. W artykule przedstawiono nową metodę ujawniania takiej ukrytej struktury, nazwaną Samonadzorowanym Modelem Sortowania Niedominowanego dla Współgrupowania (SNSC). Zamiast grupować wyłącznie obiekty wierszowe albo tylko cechy, SNSC szuka jednocześnie sensownych grup po obu wymiarach, ujawniając, które podzbiory wierszy i kolumn naprawdę do siebie pasują. Dla czytelników ciekawych, jak inteligentniejsze algorytmy mogą wydobyć więcej informacji z istniejących danych, praca ta pokazuje, jak połączyć idee z zakresu ewolucji, uczenia samonadzorowanego i optymalizacji wielokryterialnej w skuteczne narzędzie.
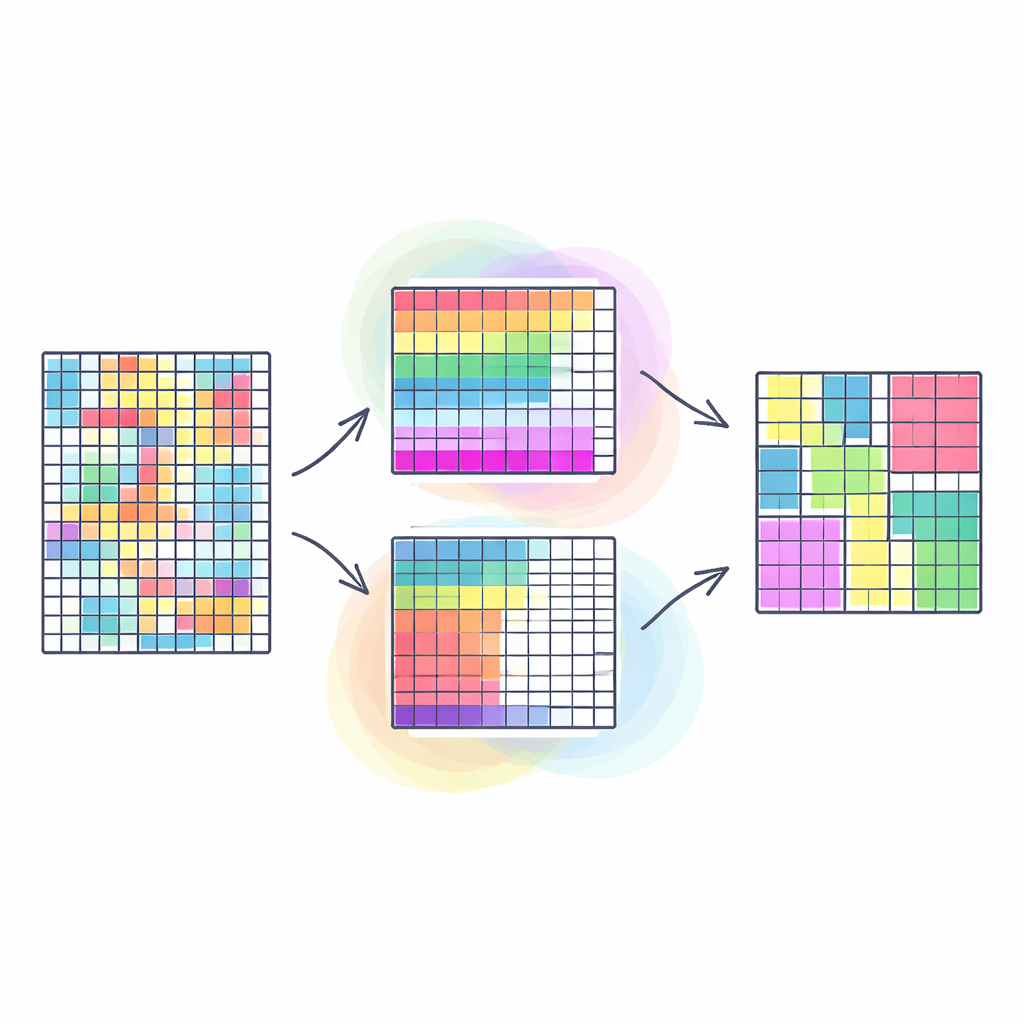
Dlaczego jednoczesne grupowanie wierszy i kolumn ma znaczenie
Tradycyjne metody grupowania zwykle scalają podobne wiersze w tabeli — na przykład klientów o zbliżonych nawykach zakupowych — traktując wszystkie kolumny jako jednakowo istotne. Współgrupowanie idzie o krok dalej: grupuje równocześnie wiersze i kolumny, tak aby odkryć bloki danych, w których określony podzbiór klientów zachowuje się podobnie względem określonego podzbioru produktów. Tego rodzaju „podwójne grupowanie” często ujawnia czytelniejsze, bardziej użyteczne wzorce, takie jak społeczności w sieciach społecznościowych czy segmenty w obrazach. Jednak większość istniejących podejść próbuje spłaszczyć ten wieloaspektowy problem do jednego celu, co może uprościć rzeczywistość i sprawić, że jakość wyników będzie silnie zależała od arbitralnych wyborów wag.
Przekształcanie współgrupowania w zadanie wielokryterialne
Autorzy traktują współgrupowanie jako rzeczywiste zadanie wielocelowe. Ich model SNSC optymalizuje jednocześnie cztery cele: zwartość grup próbek, separację grup cech, oraz zgodność obu z informacją o podobieństwie wyuczoną bezpośrednio z danych. Zamiast korzystać z etykiet dostarczonych przez ludzi, SNSC tworzy dwie mapy podobieństwa — jedną dla próbek i jedną dla cech — na podstawie ich wzajemnej bliskości w oryginalnej przestrzeni danych. Mapy te pełnią rolę wewnętrznego wskazania: próbki lub cechy wyglądające podobnie według surowych danych są łagodnie zachęcane do trafienia do tej samej klastra, bez przekształcania metody w system w pełni nadzorowany. Poprzez balansowanie ogólnej struktury z tymi lokalnymi wskazówkami, SNSC ma na celu znalezienie klastrów, które są jednocześnie zwarte i wierne wewnętrznej geometrii danych.
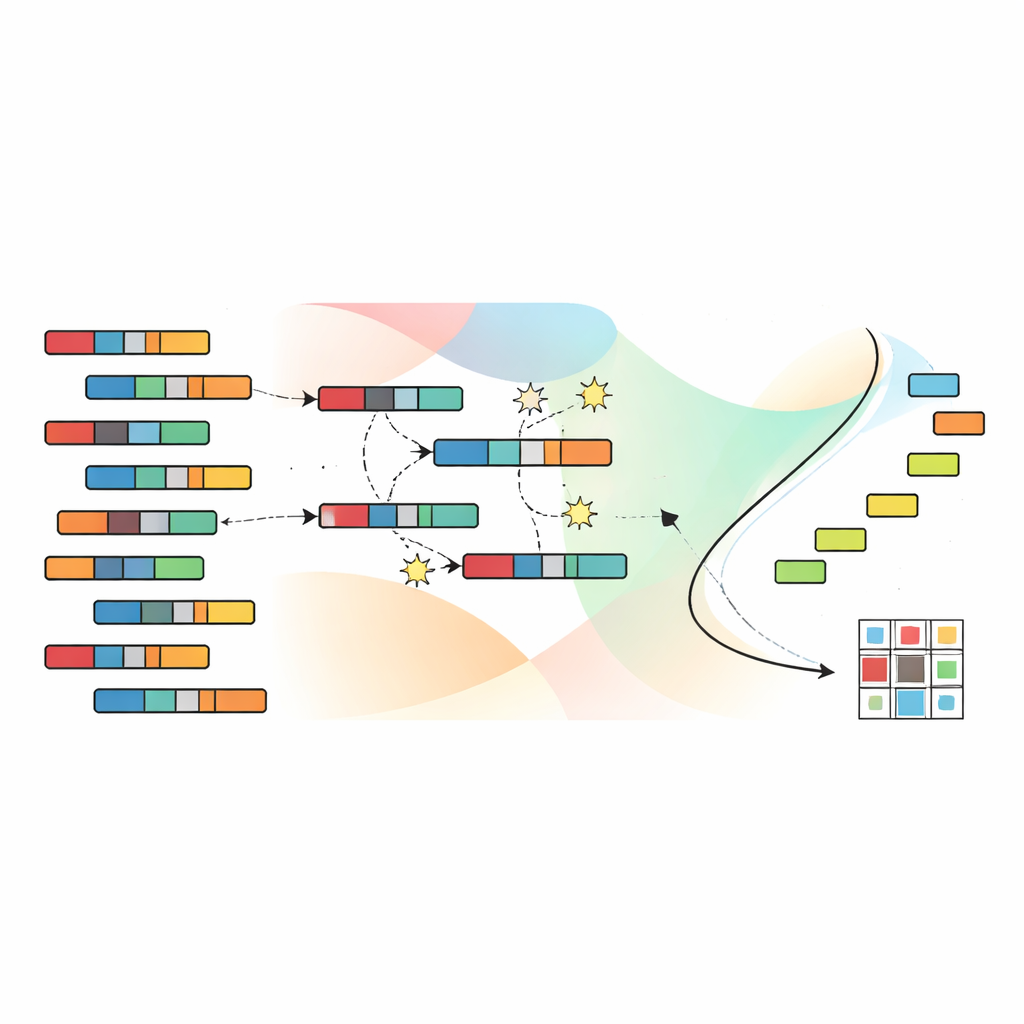
Pozwalanie ewolucji szukać lepszych grupowań
Aby przeszukać ogromną przestrzeń możliwych podziałów, autorzy korzystają z algorytmu genetycznego, inspirowanego doborem naturalnym. Każde kandydatowe rozwiązanie koduje kompletne przypisanie próbek i cech do grup. Populacja takich kandydatów jest ewoluowana przez wiele pokoleń: obiecujące rozwiązania są łączone i nieco modyfikowane, podczas gdy mniej skuteczne są odrzucane. Kluczowe dla SNSC jest użycie techniki zwanej sortowaniem niedominowanym, która nie redukuje czterech celów do jednej skalarnej oceny. Zamiast tego utrzymywany jest zbiór rozwiązań „niedominowanych”, w którym żadne rozwiązanie nie jest zdecydowanie gorsze od innego we wszystkich kryteriach. Punkty odniesienia w przestrzeni celów pomagają zachować różnorodność rozwiązań, aby algorytm nie utknął w jednym wąskim obszarze możliwości.
Uczenie dobrych punktów startowych bez etykiet
Kluczową innowacją w SNSC jest sposób inicjalizacji tego przeszukiwania ewolucyjnego. Zamiast rozpoczynać wyłącznie od losowych zgadywań, model stosuje strategię hybrydową. Połowa początkowych rozwiązań jest losowa, co zapewnia szeroką eksplorację. Druga połowa powstaje poprzez zastosowanie standardowych metod grupowania — takich jak k‑means, grupowanie rozmyte i pokrewne techniki — do danych i ich transpozycji. Tacy „bootstrapowani” kandydaci działają jako samonadzorowane wskazówki wyprowadzone z samych danych, często rozpoczynając proces ewolucji bliżej użytecznych wzorców. Eksperymenty pokazują, że to połączenie losowości i samonadzorowania zwiększa odporność i zmniejsza ryzyko utknięcia w złych lokalnych optimum.
Testy na rzeczywistych zbiorach danych i ich znaczenie
Autorzy ocenili SNSC na czternastu rzeczywistych zbiorach danych z obszarów obrazów, multimediów i klasycznych repozytoriów uczenia maszynowego, porównując go z kilkoma znanymi metodami współgrupowania. Korzystając z powszechnie akceptowanych miar jakości grupowania, takich jak dokładność i warianty sumy kwadratów błędów, SNSC często przewyższał alternatywy i wykazywał istotne statystycznie poprawy w wielu zbiorach. Choć nie jest to najlżejsza metoda pod względem czasu — jej poszukiwanie genetyczne i konstrukcja podobieństw są obliczeniowo bardziej wymagające — dostarcza konsekwentnie silnych, stabilnych wyników, co sugeruje, że nadaje się szczególnie tam, gdzie jakość jest ważniejsza niż surowa szybkość.
Wyraźniejsze wzorce za kosztem zasobów obliczeniowych
Mówiąc wprost, artykuł pokazuje, że traktowanie współgrupowania jako zadania wielokryterialnego i pozwolenie procesowi ewolucyjnemu na poszukiwanie zrównoważonych rozwiązań może ujawnić czytelniejsze, bardziej wiarygodne wzorce w złożonych tabelach danych. Samonadzorowane mapy podobieństwa pomagają algorytmowi wykorzystać strukturę już obecną w danych, bez potrzeby etykietowania przez człowieka. Ceną jest koszt obliczeniowy: SNSC wymaga więcej czasu i zasobów niż prostsze metody, szczególnie dla bardzo dużych zbiorów. Autorzy sugerują, że przyszłe prace powinny skupić się na zwiększeniu skalowalności podejścia, na przykład przez przyspieszenie poszukiwania genetycznego lub uruchamianie go równolegle. Mimo to, dla zastosowań, w których zrozumienie złożonych relacji między dwoma typami bytów ma znaczenie, SNSC oferuje obiecujący, wyrafinowany sposób ujrzenia porządku w pozornym chaosie.
Cytowanie: Li, X., Wang, H., Yang, W. et al. Self-supervised non-dominated sorted model for co-clustering. Sci Rep 16, 12088 (2026). https://doi.org/10.1038/s41598-026-42498-9
Słowa kluczowe: współgrupowanie, optymalizacja wielozadaniowa, uczenie samonadzorowane, algorytmy genetyczne, eksploracja danych