Clear Sky Science · sv
Självövervakad icke-dominated sorterad modell för co-klustring
Att hitta dolda grupper i komplexa data
Moderna datatabeller — som filmbetyg från användare, gener per patienter eller produkter per kunder — är så stora och invecklade att det är svårt att urskilja tydliga mönster. Den här artikeln presenterar ett nytt sätt att avslöja sådan dold struktur, kallat Self-supervised Non-dominated Sorted Model for Co-clustering (SNSC). Istället för att gruppera endast personer eller endast objekt söker SNSC meningsfulla grupper av båda samtidigt, och visar vilka delmängder av rader och kolumner som verkligen hör ihop. För läsare som är nyfikna på hur smartare algoritmer kan pressa fram mer insikt ur befintliga data visar detta arbete hur idéer från evolution, självövervakad inlärning och multiobjektoptimering kan kombineras till ett kraftfullt verktyg.
Varför det spelar roll att gruppera rader och kolumner tillsammans
Traditionella klustringsmetoder grupperar vanligtvis liknande rader i en tabell — till exempel kunder med liknande köpmönster — och behandlar alla kolumner som lika viktiga. Co-klustring går ett steg längre: den grupperar samtidigt både rader och kolumner, så att vi upptäcker datablokker där en viss delmängd av kunder beter sig likartat på en viss delmängd av produkter. Denna typ av ”dubbel gruppering” exponerar ofta tydligare och mer användbara mönster, såsom community-strukturer i sociala nätverk eller segment i bilder. De flesta befintliga angreppssätt försöker dock pressa detta naturligt mångfacetterade problem in i ett enda mål, vilket kan förenkla verkligheten för mycket och göra resultatens kvalitet mycket känslig för godtyckliga viktningar.
Att göra co-klustring till många mål på en gång
Författarna behandlar co-klustring som en verklig multi-mål-uppgift. Deras SNSC-modell optimerar fyra målsättningar samtidigt: hur tätt proverna är grupperade, hur tydligt egenskapsgrupperna är separerade, och hur väl båda stämmer överens med likhetsinformation som lärs direkt från datan. Istället för att använda mänskligt tillhandahållna etiketter bygger SNSC två likhetskartor — en för prover och en för egenskaper — baserade på hur nära de ligger varandra i det ursprungliga datarummet. Dessa kartor fungerar som en form av intern vägledning: prover eller egenskaper som ser lika ut enligt rådatan uppmuntras mjukt att hamna i samma kluster, utan att göra metoden helt övervakad. Genom att balansera övergripande struktur med dessa lokala antydningar strävar SNSC efter att hitta kluster som både är kompakta och trogna datans inre geometri.
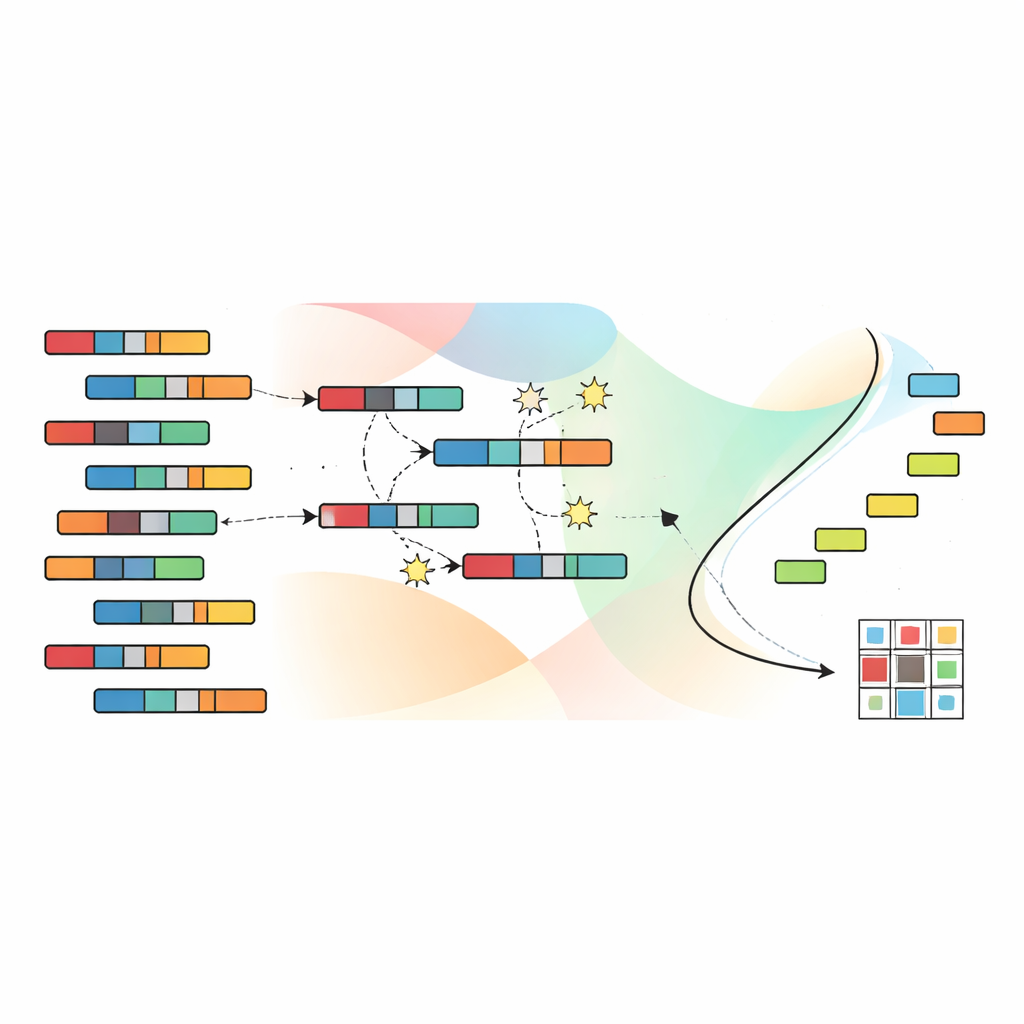
Låta evolutionen söka efter bättre grupperingar
För att navigera i det stora utrymmet av möjliga gruppering använder författarna en genetisk algoritm, inspirerad av naturligt urval. Varje kandidatlösning kodar en komplett fördelning av prover och egenskaper till kluster. En population av sådana kandidater utvecklas över många generationer: lovande lösningar kombineras och störs lätt, medan mindre effektiva lösningar förkastas. Avgörande använder SNSC en teknik som kallas icke-dominated sortering, som inte kollapsar de fyra målen till en enda poäng. Istället behålls en mängd ”icke-dominerade” lösningar där ingen är strikt sämre än en annan över alla mål. Referenspunkter i målrummet hjälper till att upprätthålla en divers spridning av lösningar, så att algoritmen inte fastnar i en snäv region av möjliga lösningar.
Lära sig bra startpunkter utan etiketter
En viktig nyskapelse i SNSC är hur den initierar denna evolutionära sökning. Istället för att börja från helt slumpmässiga gissningar använder modellen en hybridstrategi. Hälften av de initiala lösningarna är slumpmässiga och ger bred utforskning. Den andra hälften skapas genom att tillämpa standardklustringsmetoder — såsom k-means, fuzzy-klustring och relaterade tekniker — på datan och dess transponat. Dessa ”bootstrapade” kandidater fungerar som självövervakade ledtrådar härledda från datan själv och startar ofta evolutionsprocessen närmare användbara mönster. Experiment visar att denna blandning av slump och självövervakning både förbättrar robustheten och minskar risken att fastna i dåliga lokala optima.
Testning på verkliga datamängder och vad det betyder
Författarna utvärderar SNSC på fjorton verkliga dataset från bild-, multimedia- och klassiska maskininlärningssamlingar, och jämför det mot flera välkända co-klustringsmetoder. Med vanligt accepterade mått på klustringskvalitet, såsom noggrannhet och varianter av summan av kvadrerade fel, överträffar SNSC ofta alternativen och visar statistiskt signifikanta vinster på många dataset. Även om det inte är den snabbaste metoden — dess genetiska sökning och likhetskonstruktion är beräkningsmässigt tyngre — levererar det konsekvent starka, stabila resultat, vilket tyder på att det är särskilt lämpligt när kvalitet är viktigare än rå hastighet.
Tydligare mönster till en beräkningskostnad
Enkelt uttryckt visar artikeln att genom att behandla co-klustring som ett mångmålsproblem och låta en evolutionär process söka efter balanserade lösningar kan man avslöja tydligare, mer pålitliga mönster i komplexa datatabeller. De självövervakade likhetskartorna hjälper algoritmen att använda den struktur som redan finns i datan utan att kräva mänskliga etiketter. Avvägningen är beräkningskostnad: SNSC kräver mer tid och resurser än enklare metoder, särskilt för mycket stora dataset. Författarna föreslår att framtida arbete bör fokusera på att göra metoden mer skalbar, till exempel genom att snabba upp den genetiska sökningen eller köra den parallellt. Ändå, för tillämpningar där förståelsen av invecklade relationer mellan två typer av entiteter är viktig, erbjuder SNSC ett lovande och nyanserat sätt att se ordning i till synes kaos.
Citering: Li, X., Wang, H., Yang, W. et al. Self-supervised non-dominated sorted model for co-clustering. Sci Rep 16, 12088 (2026). https://doi.org/10.1038/s41598-026-42498-9
Nyckelord: co-klustring, multiobjektoptimering, självövervakad inlärning, genetiska algoritmer, datautvinning