Clear Sky Science · tr
Kendi kendine denetimli baskın olmayan sıralı model ile eş-kümeleme
Karmaşık Verilerde Gizli Grupları Bulmak
Film puanlamaları, genler × hasta verileri veya müşteriler × ürünler gibi modern veri tabloları o kadar büyük ve karışıktır ki açık bir desen görmek zordur. Bu makale, bu tür gizli yapıları ortaya çıkarmak için Kendinden Denetimli Baskın Olmayan Sıralı Model for Co-clustering (SNSC) adı verilen yeni bir yaklaşım tanıtıyor. Sadece insanları ya da sadece öğeleri gruplamak yerine, SNSC aynı anda her iki yöndeki anlamlı grupları arar ve hangi satır ve sütun altkümelerinin gerçekten birlikte olduğunu ortaya koyar. Daha akıllı algoritmaların mevcut verilerden nasıl daha fazla içgörü çıkarabileceğini merak eden okuyucular için bu çalışma, evrimsel fikirler, kendi kendine denetimli öğrenme ve çok amaçlı optimizasyonu güçlü bir araçta nasıl birleştirebileceğimizi gösteriyor.
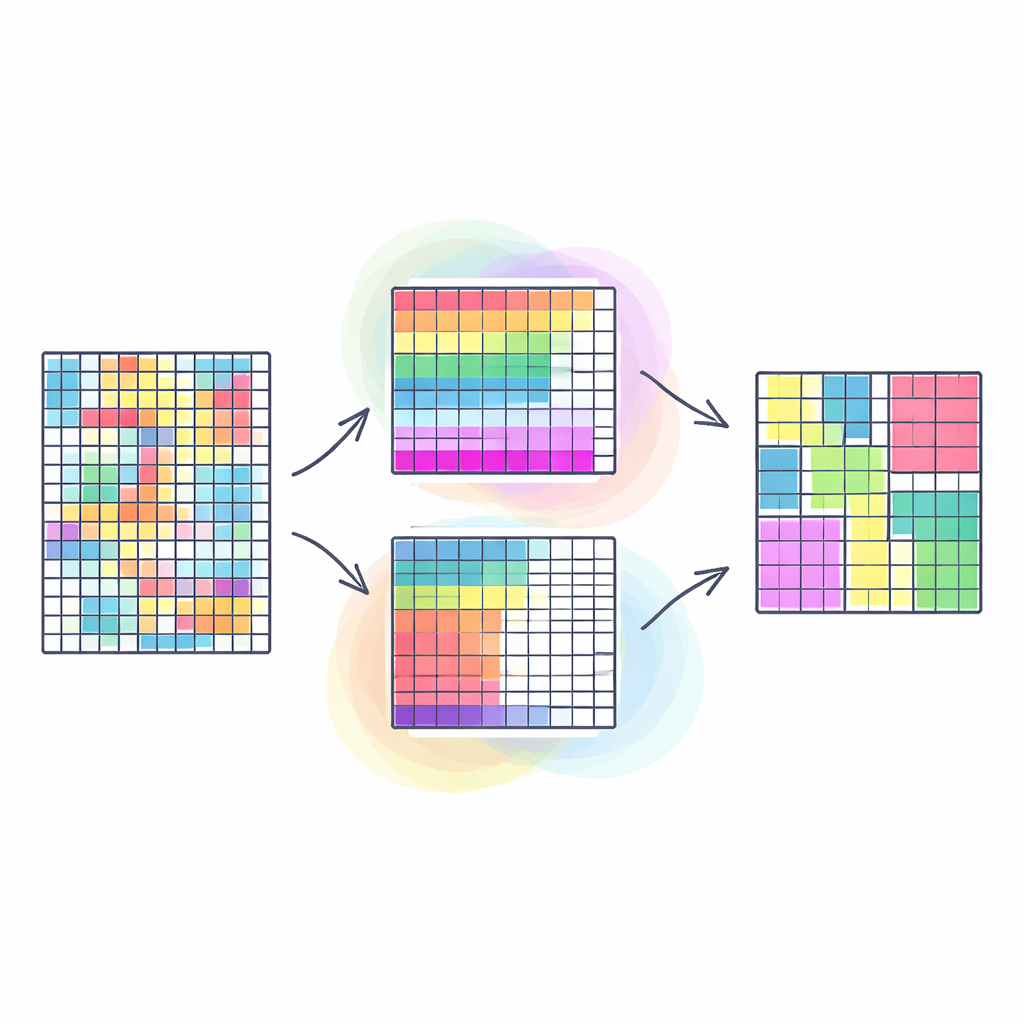
Satır ve Sütunları Birlikte Gruplamanın Önemi
Geleneksel kümeleme yöntemleri genellikle bir tablodaki benzer satırları gruplayarak—örneğin benzer satın alma alışkanlıklarına sahip müşterileri—tüm sütunları eşit önemli kabul eder. Eş-kümeleme bir adım daha ileri gider: hem satırları hem sütunları eşzamanlı olarak gruplayarak, belirli bir müşteri altkümesinin belirli bir ürün altkümesi üzerinde benzer davrandığı veri bloklarını ortaya çıkarır. Bu tür “çifte gruplayıcı” yaklaşımlar sıklıkla sosyal ağlardaki topluluklar veya görüntülerdeki segmentler gibi daha net, daha kullanışlı desenleri açığa çıkarır. Ancak mevcut yaklaşımların çoğu bu doğal olarak çok yönlü sorunu tek bir hedefe sıkıştırmaya çalışır; bu da gerçeği aşırı basitleştirebilir ve sonuçların kalitesini keyfi ağırlıklandırma seçimlerine karşı çok hassas hale getirebilir.
Eş-kümelemeyi Aynı Anda Birkaç Hedefe Çevirmek
Yazarlar eş-kümelemeyi gerçek bir çok amaçlı görev olarak ele alıyor. SNSC modeli aynı anda dört amacı optimize ediyor: örneklerin ne kadar sıkı gruplanmış olduğu, özellik gruplarının ne kadar net ayrıldığı ve her iki tarafın da veriden doğrudan öğrenilen benzerlik bilgisiyle ne kadar iyi uyuştuğu. İnsan tarafından sağlanan etiketler yerine, SNSC orijinal veri uzayında birbirlerine ne kadar yakın olduklarına dayanarak bir örnekler ve bir özellikler benzerlik haritası oluşturur. Bu haritalar bir tür iç rehberlik görevi görür: ham verilere göre benzer görünen örnekler veya özellikler aynı kümede yer almaya nazikçe teşvik edilir, yöntemi tamamen denetimli bir sisteme dönüştürmeden. Genel yapıyı bu yerel ipuçlarıyla dengeleyerek, SNSC hem sıkı hem de verinin iç geometrisine sadık kümeler bulmayı hedefler.
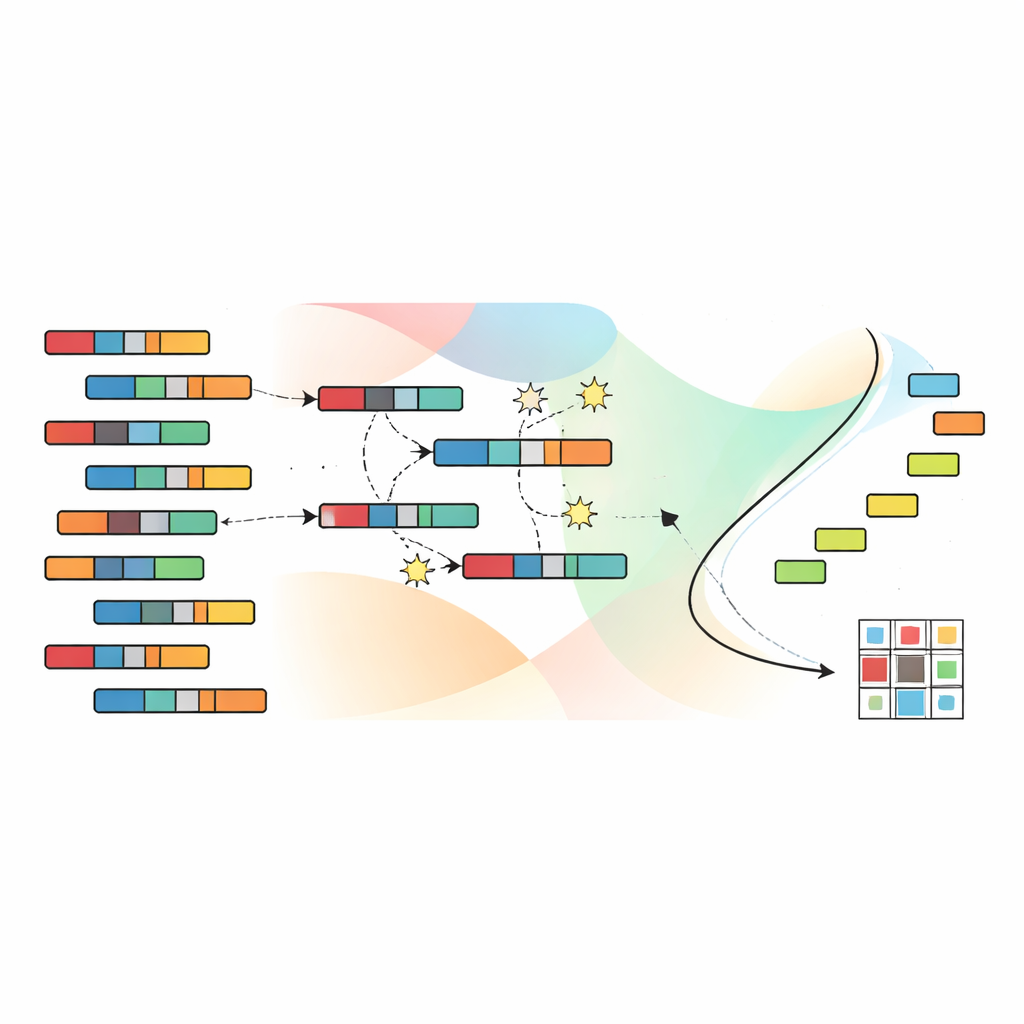
Daha İyi Gruplamalar İçin Evrimin Aramasına İzin Vermek
Olası gruplamaların çok geniş uzayında gezinmek için yazarlar doğal seçilimi andıran bir genetik algoritmaya dayanıyor. Her aday çözüm, örneklerin ve özelliklerin kümelere tam atamasını kodlar. Böyle adaylardan oluşan bir popülasyon birçok nesil boyunca evrilir: umut verici çözümler birleştirilir ve hafifçe bozulur, daha az etkili olanlar elenir. Kritik olarak, SNSC dört amacı tek bir skorda toplamayan baskın olmayan sıralama adı verilen bir teknik kullanır. Bunun yerine, hiçbirinin tüm hedefler açısından diğerine göre mutsuz edici biçimde daha kötü olmadığı bir dizi “baskın olmayan” çözümü korur. Amaç uzayındaki referans noktaları, algoritmanın çözümlerini tek dar bir bölgeye takılıp kalmaması için çeşitli bir dağılımı korumaya yardımcı olur.
Etiket Olmadan İyi Başlangıç Noktaları Öğrenmek
SNSC’deki önemli yeniliklerden biri, bu evrimsel aramayı nasıl başlattığıdır. Tamamen rastgele tahminlerden başlamak yerine model hibrit bir strateji kullanır. Başlangıç çözümlerinin yarısı geniş keşif sağlayan rastgele çözümlerdir. Diğer yarısı ise veriye ve transpozuna standart kümeleme yöntemleri—örneğin k-means, bulanık kümeleme ve ilgili teknikler—uygulanarak oluşturulur. Bu “başlangıçtan türetilmiş” adaylar verinin kendisinden elde edilen kendi kendine denetimli ipuçları olarak hareket eder ve evrim sürecini genellikle yararlı desenlere daha yakın bir noktadan başlatır. Deneyler, bu rastgelelik ve kendi kendine denetim karışımının hem dayanıklılığı artırdığını hem de kötü yerel optimumlarda takılma riskini azalttığını gösteriyor.
Gerçek Veri Kümeleri Üzerinde Test Etme ve Anlamı
Yazarlar SNSC’yi görüntü, multimedya ve klasik makine öğrenimi koleksiyonlarından alınmış on dört gerçek dünya veri kümesi üzerinde değerlendirir ve onu birkaç iyi bilinen eş-kümeleme yöntemine karşı karşılaştırır. Doğruluk ve kareler toplamı gibi kümelenme kalitesi için yaygın olarak kabul edilen ölçüler kullanıldığında, SNSC sıklıkla alternatiflerin önüne geçer ve birçok veri kümesinde istatistiksel olarak anlamlı kazanımlar gösterir. En hızlı yöntem olmasa da—genetik arama ve benzerlik inşası hesaplama açısından daha ağırdır—tutarlı şekilde güçlü ve kararlı sonuçlar verir; bu da ham hızdan çok kaliteyi önemseyen uygulamalarda özellikle uygun olduğunu düşündürür.
Hesaplama Maliyeti Karşısında Daha Net Desenler
Basitçe söylemek gerekirse, makale eş-kümelemeyi çok amaçlı bir problem olarak ele almanın ve evrimsel bir sürecin dengeli çözümler aramasına izin vermenin karmaşık veri tablolarında daha net, daha güvenilir desenler ortaya çıkarabileceğini gösteriyor. Kendi kendine denetimli benzerlik haritaları algoritmanın veride zaten var olan yapıyı insan etiketlerine ihtiyaç duymadan kullanmasına yardımcı olur. Takas noktası hesaplama maliyetidir: SNSC daha basit yöntemlere göre özellikle çok büyük veri kümelerinde daha fazla zaman ve kaynak gerektirir. Yazarlar gelecekte yaklaşımı daha ölçeklenebilir kılmaya—örneğin genetik aramayı hızlandırmaya veya paralel çalıştırmaya—odaklanılması gerektiğini öneriyor. Buna rağmen, iki farklı varlık türü arasındaki karmaşık ilişkileri anlamanın önemli olduğu uygulamalar için SNSC görünürdeki kaosta düzen görmenin ümit vadeden, nüanslı bir yolunu sunar.
Atıf: Li, X., Wang, H., Yang, W. et al. Self-supervised non-dominated sorted model for co-clustering. Sci Rep 16, 12088 (2026). https://doi.org/10.1038/s41598-026-42498-9
Anahtar kelimeler: eş-kümeleme, çok amaçlı optimizasyon, kendi kendine denetimli öğrenme, genetik algoritmalar, veri madenciliği