Clear Sky Science · pt
Modelo auto-supervisionado não-dominado ordenado para co-clustering
Encontrando grupos ocultos em dados complexos
Tabelas de dados modernas — como avaliações de filmes por usuários, genes por pacientes ou produtos por clientes — são tão grandes e intrincadas que fica difícil ver padrões claros. Este artigo apresenta uma nova maneira de revelar essa estrutura oculta, chamada Modelo Auto-supervisionado Não-dominado Ordenado para Co-clustering (SNSC). Em vez de agrupar apenas pessoas ou apenas itens, o SNSC busca grupos significativos de ambos ao mesmo tempo, revelando quais subconjuntos de linhas e colunas realmente pertencem juntos. Para leitores interessados em como algoritmos mais inteligentes podem extrair mais insight de dados existentes, este trabalho mostra como ideias da evolução, do aprendizado auto-supervisionado e da otimização multiobjetivo podem ser combinadas em uma ferramenta poderosa.
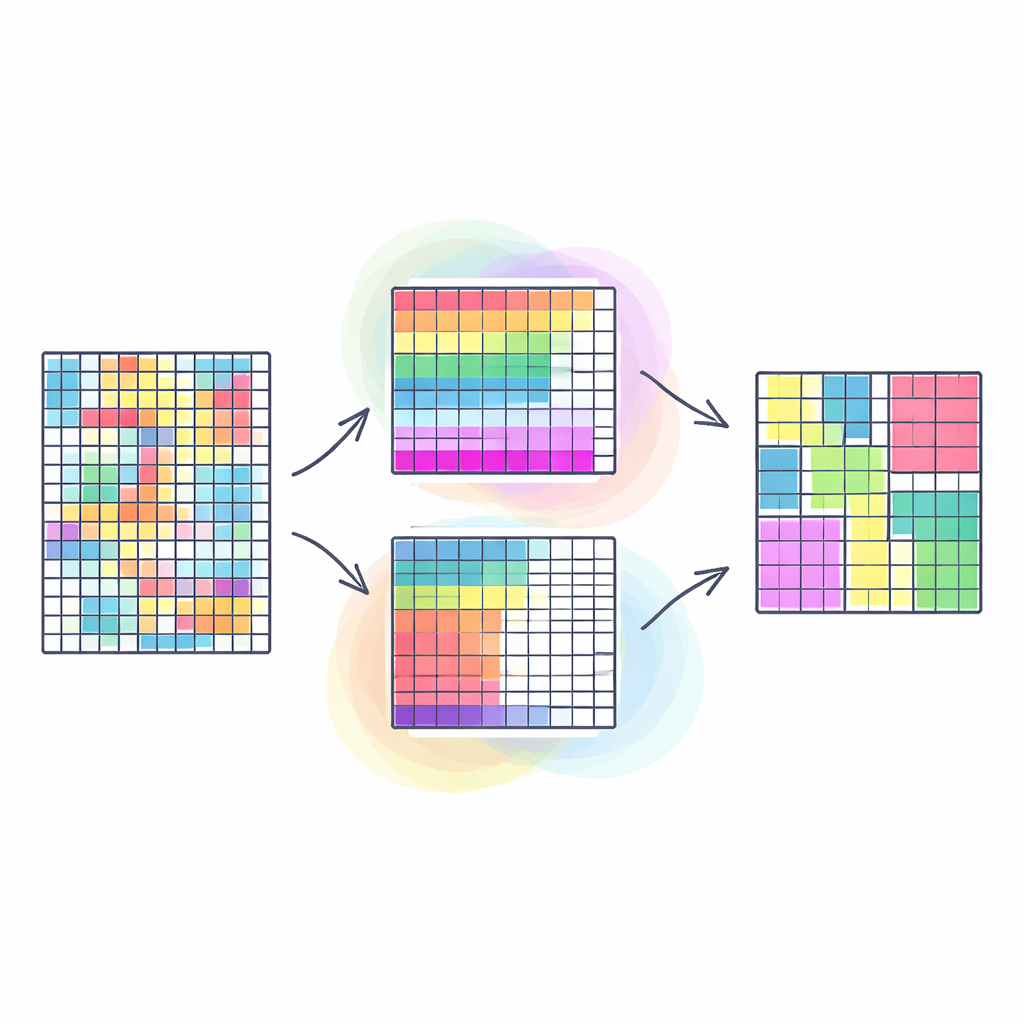
Por que agrupar linhas e colunas juntos importa
Métodos tradicionais de clustering geralmente agrupam linhas semelhantes em uma tabela — por exemplo, clientes com hábitos de compra parecidos — tratando todas as colunas como igualmente importantes. O co-clustering vai além: agrupa simultaneamente linhas e colunas, de modo a descobrir blocos de dados em que um subconjunto particular de clientes se comporta de maneira semelhante em um subconjunto particular de produtos. Esse tipo de “duplo agrupamento” frequentemente revela padrões mais claros e úteis, como comunidades em redes sociais ou segmentos em imagens. No entanto, a maioria das abordagens existentes tenta forçar esse problema naturalmente multifacetado em um único objetivo, o que pode simplificar demais a realidade e tornar a qualidade dos resultados altamente sensível a escolhas arbitrárias de ponderação.
Transformando co-clustering em muitos objetivos ao mesmo tempo
Os autores tratam o co-clustering como uma tarefa verdadeiramente multiobjetivo. Seu modelo SNSC otimiza quatro objetivos ao mesmo tempo: quão compactos são os agrupamentos de amostras, quão bem separados estão os grupos de características, e o quanto ambos concordam com informações de similaridade aprendidas diretamente dos dados. Em vez de usar rótulos fornecidos por humanos, o SNSC constrói dois mapas de similaridade — um para amostras e outro para características — com base em quão próximas elas estão no espaço de dados original. Esses mapas funcionam como uma espécie de orientação interna: amostras ou características que parecem semelhantes de acordo com os dados crus são suavemente encorajadas a cair no mesmo cluster, sem transformar o método em um sistema totalmente supervisionado. Ao equilibrar a estrutura global com essas pistas locais, o SNSC busca encontrar clusters que sejam ao mesmo tempo compactos e fiéis à geometria interna dos dados.
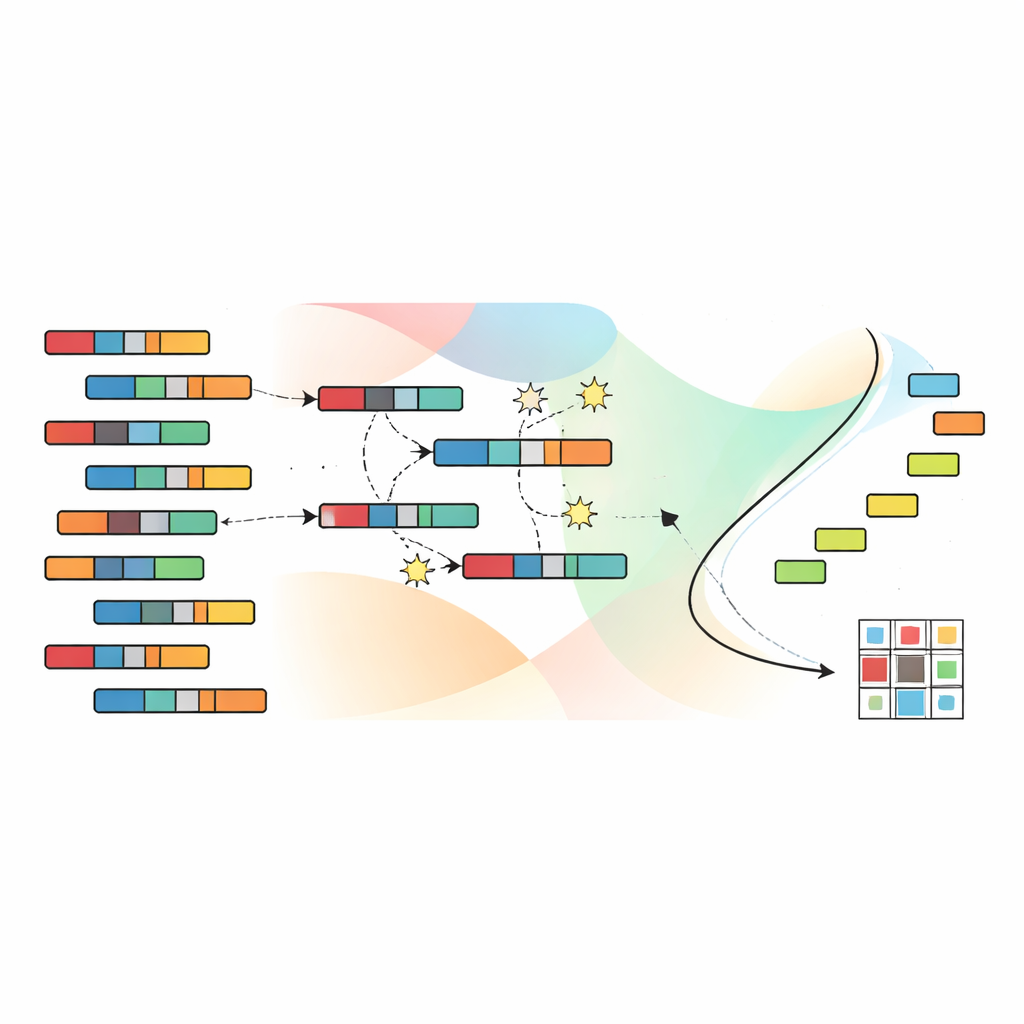
Deixando a evolução buscar agrupamentos melhores
Para navegar pelo enorme espaço de agrupamentos possíveis, os autores recorrem a um algoritmo genético, inspirado na seleção natural. Cada solução candidata codifica uma atribuição completa de amostras e características aos clusters. Uma população dessas candidatas é evoluída ao longo de muitas gerações: soluções promissoras são combinadas e ligeiramente perturbadas, enquanto as menos eficazes são descartadas. Crucialmente, o SNSC usa uma técnica chamada ordenação não-dominada, que não colapsa os quatro objetivos em uma única pontuação. Em vez disso, mantém um conjunto de soluções “não-dominadas” nas quais nenhuma é estritamente pior que outra em todos os objetivos. Pontos de referência no espaço de objetivos ajudam a manter uma distribuição diversa de soluções, para que o algoritmo não fique preso em uma única região estreita de possibilidades.
Aprendendo bons pontos de partida sem rótulos
Uma inovação chave no SNSC é como ele inicializa essa busca evolutiva. Em vez de começar por palpites puramente aleatórios, o modelo usa uma estratégia híbrida. Metade das soluções iniciais é aleatória, fornecendo ampla exploração. A outra metade é criada aplicando métodos de clustering padrão — como k-means, clustering difuso e técnicas relacionadas — aos dados e à sua transposta. Essas candidatas “bootstrapped” atuam como pistas auto-supervisionadas derivadas dos próprios dados, frequentemente iniciando o processo evolutivo mais próximo de padrões úteis. Experimentos mostram que essa mistura de aleatoriedade e auto-supervisão tanto melhora a robustez quanto reduz o risco de cair em ótimos locais pobres.
Testes em conjuntos reais e o que isso significa
Os autores avaliam o SNSC em quatorze conjuntos de dados do mundo real de coleções de imagem, multimídia e aprendizado de máquina clássico, comparando-o com vários métodos de co-clustering bem conhecidos. Usando medidas comumente aceitas de qualidade de clustering, como acurácia e variantes da soma dos erros quadráticos, o SNSC frequentemente supera as alternativas e mostra ganhos estatisticamente significativos em muitos conjuntos de dados. Embora não seja o método mais rápido — sua busca genética e a construção das similaridades são computacionalmente mais pesadas — ele entrega resultados consistentemente fortes e estáveis, sugerindo que é particularmente adequado quando a qualidade é mais importante que a velocidade bruta.
Padrões mais claros com um custo computacional
Em termos simples, o artigo mostra que tratar o co-clustering como um problema multiobjetivo e permitir que um processo evolutivo busque soluções balanceadas pode revelar padrões mais claros e confiáveis em tabelas complexas de dados. Os mapas de similaridade auto-supervisionados ajudam o algoritmo a aproveitar a estrutura já presente nos dados, sem exigir rótulos humanos. A contrapartida é o custo computacional: o SNSC demanda mais tempo e recursos do que métodos mais simples, especialmente em conjuntos de dados muito grandes. Trabalhos futuros, sugerem os autores, devem se concentrar em tornar a abordagem mais escalável, por exemplo acelerando a busca genética ou executando-a em paralelo. Ainda assim, para aplicações em que entender relações intrincadas entre dois tipos de entidades importa, o SNSC oferece uma maneira promissora e nuançada de ver ordem no aparente caos.
Citação: Li, X., Wang, H., Yang, W. et al. Self-supervised non-dominated sorted model for co-clustering. Sci Rep 16, 12088 (2026). https://doi.org/10.1038/s41598-026-42498-9
Palavras-chave: co-clustering, otimização multiobjetivo, aprendizado auto-supervisionado, algoritmos genéticos, mineração de dados