Clear Sky Science · ru
Самостоятельная не доминируемая модель с сортировкой для со-кластеризации
Поиск скрытых групп в сложных данных
Современные таблицы данных — например, оценки фильмов пользователями, гены по пациентам или товары по покупателям — настолько велики и запутаны, что в них трудно заметить ясную структуру. В этой работе предлагается новый способ выявления такой скрытой структуры, названный Самостоятельной Недоминируемой Моделью с Сортировкой для Со-кластеризации (SNSC). Вместо того чтобы группировать только людей или только объекты, SNSC ищет существенные группы и тех, и других одновременно, показывая, какие подмножества строк и столбцов действительно принадлежат друг другу. Для читателей, которые интересуются тем, как более умные алгоритмы могут извлечь больше сведений из имеющихся данных, эта работа демонстрирует, как идеи из эволюции, самостоятельного обучения и многоцелевой оптимизации можно объединить в мощный инструмент.
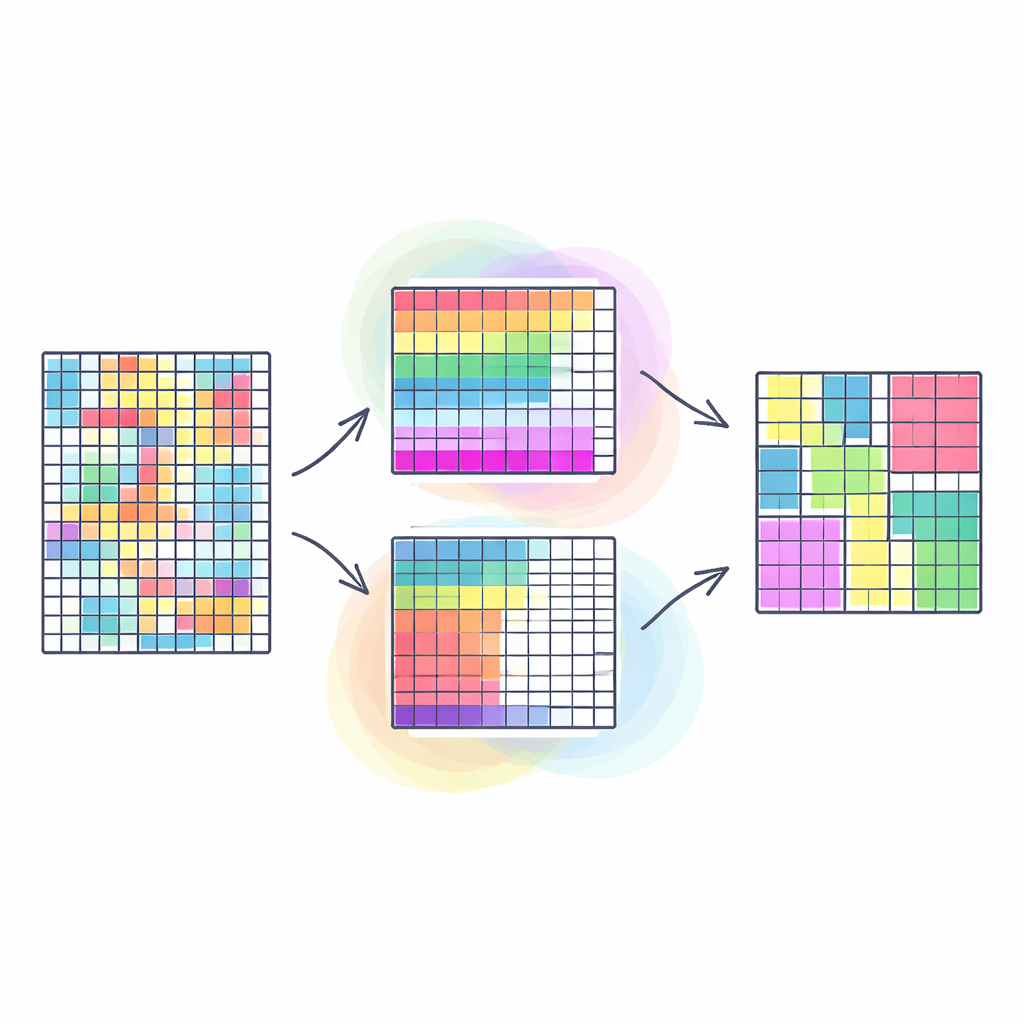
Почему важно группировать строки и столбцы вместе
Традиционные методы кластеризации обычно группируют похожие строки в таблице — например, клиентов с похожими покупательскими привычками — считая все столбцы одинаково важными. Со-кластеризация идёт дальше: она одновременно группирует и строки, и столбцы, благодаря чему обнаруживаются блоки данных, в которых определённое подмножество клиентов ведёт себя похоже на определённом подмножестве товаров. Такой «двойной» подход часто выявляет более ясные и полезные закономерности, например сообщества в социальных сетях или сегменты на изображениях. Однако большинство существующих подходов пытаются свести эту естественно многогранную задачу к одной цели, что может чрезмерно упростить реальность и сделать качество результатов очень чувствительным к произвольному выбору весов.
Преобразование со-кластеризации в множество целей одновременно
Авторы рассматривают со-кластеризацию как истинно многоцелевую задачу. Их модель SNSC одновременно оптимизирует четыре цели: насколько компактно сгруппированы образцы, насколько чётко разделены группы признаков и насколько хорошо обе группировки согласуются с информацией о сходстве, извлечённой прямо из данных. Вместо использования меток, предоставленных человеком, SNSC строит две карты сходства — одну для образцов и одну для признаков — на основе того, насколько близки объекты друг к другу в исходном пространстве данных. Эти карты служат своего рода внутренним ориентиром: образцы или признаки, которые на основании сырых данных выглядят похоже, мягко поощряются попадать в один кластер, не превращая метод в полностью контролируемую систему. Сбалансировав общую структуру и эти локальные подсказки, SNSC стремится находить кластеры, которые и компактны, и правдиво отражают внутреннюю геометрию данных.
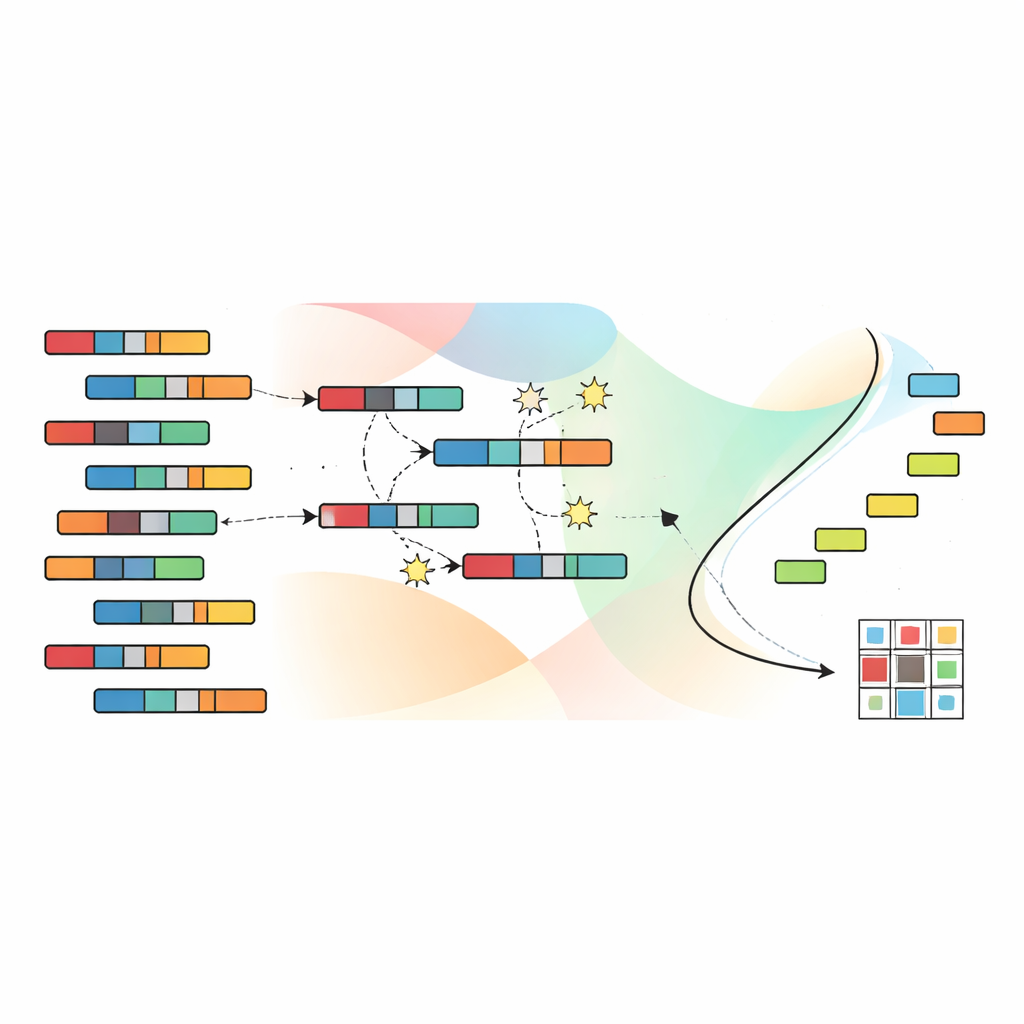
Разрешение поиска лучших группировок с помощью эволюции
Чтобы исследовать огромное пространство возможных группировок, авторы опираются на генетический алгоритм, вдохновлённый естественным отбором. Каждое кандидатное решение кодирует полное назначение образцов и признаков по кластерам. Популяция таких кандидатов эволюционирует на протяжении многих поколений: перспективные решения комбинируются и слегка модифицируются, тогда как менее эффективные отбрасываются. Ключевым является использование SNSC техники, называемой недоминирующей сортировкой, которая не сводит четыре цели к одному суммарному показателю. Вместо этого сохраняется набор «недоминирующих» решений, где ни одно не является строго хуже другого по всем целям одновременно. Опорные точки в пространстве целей помогают поддерживать разнообразный набор решений, чтобы алгоритм не застрял в одной узкой области возможностей.
Обучение хороших начальных точек без меток
Ключевое новшество SNSC — то, как он инициализирует этот эволюционный поиск. Вместо старта с полностью случайных предположений модель использует гибридную стратегию. Половина начальных решений случайна, что обеспечивает широкий охват пространства поиска. Другая половина создаётся применением стандартных методов кластеризации — таких как k-средних, нечёткая кластеризация и связанные техники — к данным и к их транспонированной версии. Эти «бутстрэпнутые» кандидаты выступают в роли самостоятельных подсказок, полученных из самих данных, часто позволяя эволюции стартовать ближе к полезным паттернам. Эксперименты показывают, что такое сочетание случайности и самостоятельного обучения повышает надёжность и снижает риск застрять в плохих локальных оптимумах.
Тестирование на реальных наборах данных и что это означает
Авторы оценивают SNSC на четырнадцати реальных наборах данных из областей изображений, мультимедиа и классических коллекций машинного обучения, сравнивая его с несколькими известными методами со-кластеризации. Используя общепринятые метрики качества кластеризации, такие как точность и варианты суммы квадратов ошибок, SNSC часто превосходит альтернативы и демонстрирует статистически значимые улучшения на многих наборах данных. Хотя это не самый быстрый метод — его генетический поиск и построение карт сходства вычислительно более затратны — он обеспечивает последовательно сильные и стабильные результаты, что делает его особенно пригодным там, где качество важнее сырой скорости.
Более ясные паттерны ценой вычислительных ресурсов
Проще говоря, статья показывает, что рассмотрение со-кластеризации как задачи с множеством целей и предоставление эволюционному процессу возможности искать сбалансированные решения может выявлять более ясные и надёжные закономерности в сложных таблицах данных. Самостоятельные карты сходства помогают алгоритму использовать структуру, уже присутствующую в данных, без требования человеческих меток. Цена вопроса — вычислительные затраты: SNSC требует больше времени и ресурсов, чем более простые методы, особенно на очень больших наборах данных. Как предлагают авторы, дальнейшие работы должны быть направлены на повышение масштабируемости подхода, например за счёт ускорения генетического поиска или его параллелизации. Даже с учётом этого, для приложений, где важно понимать тонкие взаимоотношения между двумя типами сущностей, SNSC предлагает многообещающий и тонко настроенный способ увидеть порядок в кажущемся хаосе.
Цитирование: Li, X., Wang, H., Yang, W. et al. Self-supervised non-dominated sorted model for co-clustering. Sci Rep 16, 12088 (2026). https://doi.org/10.1038/s41598-026-42498-9
Ключевые слова: со-кластеризация, многоцелевое оптимизирование, самостоятельное обучение, генетические алгоритмы, интеллектуальный анализ данных